AI Patent Search: Semantic Similarity Explained
Intellectual Property Management
Mar 17, 2026
How AI turns patent text into vectors for semantic search, improving recall, reducing search time, and combining vector results with Boolean filters.

Semantic similarity transforms patent searches by focusing on meaning rather than exact keywords. AI models convert patent text into numerical vectors, enabling tools to identify related documents, even when terminology differs. For example, terms like "drone" and "unmanned aerial rotorcraft" are recognized as conceptually similar. This approach addresses challenges like vocabulary gaps and vague language, which traditional searches often miss.
Key Takeaways:
How It Works: AI turns text into vectors, compares them using cosine similarity, and ranks results by relevance.
Benefits: Cuts search time by up to 80%, improves accuracy, and bridges terminology gaps.
Applications: Prior art searches, portfolio analysis, competitor tracking, and standards essential patent evaluation.
Semantic search combines AI with Boolean logic for both broad coverage and precision, making patent research faster and more reliable.
How Semantic Similarity Analysis Works
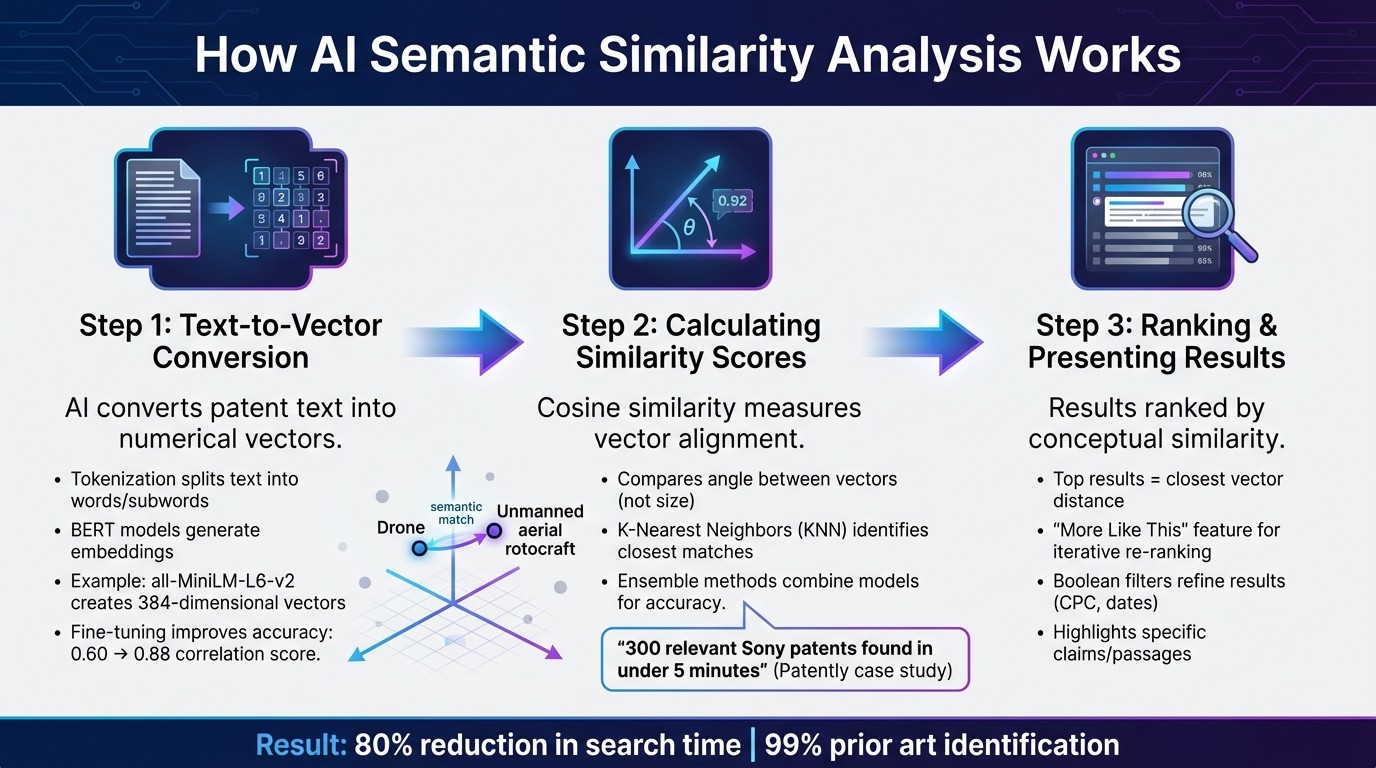
How AI Semantic Similarity Works in Patent Search: 3-Step Process
To understand why AI-powered patent searches outperform older methods, it helps to break down the key steps involved. The process revolves around three main stages: transforming text into numerical data, comparing those data points for similarity, and ranking the results efficiently. Together, these steps create a smooth workflow for AI-driven patent searches.
Text-to-Vector Conversion
AI models begin by converting patent text - such as titles, abstracts, or claims - into numerical vectors that represent the document's meaning in a multi-dimensional space. Advanced models like BERT derivatives are commonly used to generate these embeddings.
The process kicks off with tokenization, which splits the text into smaller units like words or subwords. Then, the model applies pooling techniques to these contextual word embeddings, producing a single dense vector that encapsulates the meaning of a phrase or paragraph. For instance, the "all-MiniLM-L6-v2" model maps text into a 384-dimensional vector space, while models like "all-mpnet-base-v2" deliver higher accuracy but may operate at slower speeds.
In this vector space, documents with similar meanings are grouped close together, even if they don’t share identical keywords. Golam Rabiul Alam, PhD, Professor at BRAC University, explains:
AI converts your query into a mathematical vector. It understands that 'Drone' and 'Rotocraft' are semantically close.
Fine-tuning these models with patent-specific data can significantly improve accuracy. For example, Pearson correlation scores can jump from 0.60 (using standard Sentence-BERT) to 0.88.
Calculating Similarity Scores
Once the text is transformed into vectors, the system measures how closely they align using cosine similarity. This mathematical technique compares the angle between two vectors, focusing on their orientation rather than their size, which makes it ideal for handling documents of varying lengths.
The K-Nearest Neighbors (KNN) algorithm then identifies the vectors closest to your search query. To enhance accuracy, ensemble methods combine BERT-based models with weighted averaging and token scoring. For example, in October 2024, Patently integrated Elastic's Search AI and vector search to improve discovery across its vast database of 82 million patent families. Using this technology, IP professional Laurence Brown searched for "In-ear headphones with noise isolating tips" with a priority date before 2000 and identified 300 relevant Sony applications in under five minutes.
Ranking and Presenting Search Results
After calculating similarity scores, the system ranks results based on the distance between the query vector and document vectors. The most conceptually similar patents appear at the top of the list.
Many professional platforms include an iterative re-ranking feature (often called "More Like This"). This allows users to select a specific relevant patent, prompting the system to re-rank the entire list based on its similarity to that document. Interfaces also highlight specific sections - like claims, passages, or figures - that directly relate to the search query, making it easier for users to review results quickly. To address semantic drift, users can apply Boolean filters (such as CPC classes or date ranges) to refine the ranked list further.
Jerome Spaargaren, Founder and Director at Patently, highlights the impact of these advancements:
This powerful addition has positioned Patently as one of the most innovative platforms for semantic patent search and is core to our technology stack.
Applications of Semantic Similarity in Patent Workflows
Prior Art Search and Patentability Analysis
In the world of patents, terminology often varies widely. For instance, an inventor might use the term "drone", while prior art might refer to it as an "unmanned aerial rotocraft." Semantic search bridges this gap by converting these terms into mathematical vectors that recognize their conceptual equivalence, ensuring no relevant prior art is overlooked.
This approach doesn’t stop at vocabulary differences. It also connects related technologies across industries, even when they use entirely different terminologies. By doing so, semantic search has drastically reduced search times - by as much as 80% - saving both time and money during the patent application process.
The standard workflow projected for 2026 combines vector-based semantic search for broad recall with Boolean logic for precision. Professionals can start with semantic search to identify the top 500 conceptually similar patents, extract new keywords from these results, and then refine the search using Boolean filters like date ranges or CPC classifications. This process narrows the focus to the 50 most relevant patents for detailed review.
These advancements go beyond just prior art searches, offering valuable insights for broader patent portfolio and competitive analyses.
Portfolio Comparison and Competitor Analysis
Semantic similarity tools are also revolutionizing portfolio management and competitor analysis. By clustering patents into distinct technology segments, they simplify the process of benchmarking and identifying opportunities. It’s no surprise that 73% of in-house IP teams now rely on AI-enhanced search tools .
Organizations use these tools to evaluate the strength of their portfolios and uncover "technology white spaces" - areas where competitors haven’t yet ventured. During mergers and acquisitions, semantic analysis accelerates the evaluation of patent quality and overlap, while also flagging potential infringement risks by identifying similar technical concepts across varying terminologies .
Compared to traditional keyword-only methods, AI-assisted semantic search reduces the need for manual query adjustments by up to 60%, making the process far more efficient.
Standards Essential Patent (SEP) Analysis
Semantic similarity has also transformed how companies determine whether patents are essential to technical standards like 5G or Wi-Fi. AI tools now generate Semantic Essentiality Scores (SES), which range from 1 to 100, indicating how likely a patent is to be essential to a particular standard. These tools map independent patent claims to specific sections of technical standards, identifying conceptual overlaps even when the language differs.
Platforms can automatically extract relevant sections from standards and align them with patent claims, providing structured evidence for IP teams. This process, which once took weeks, can now be completed in minutes. The result? Nonessential patents are quickly filtered out, while semantic scores support FRAND rate calculations and help lower legal costs .
Benefits of AI-Powered Semantic Similarity in Patent Search
Better Precision and Recall
Semantic similarity, built on a vector-based approach, significantly improves precision by bridging vocabulary gaps. Unlike traditional keyword matching, these tools assign numerical rankings to measure patent relevance objectively. With over 130 million global patent documents in circulation, this capability is crucial for filtering out irrelevant results.
As of 2026, the industry relies on hybrid search methods. These combine semantic vectors for broader recall with Boolean filters for precision. Golam Rabiul Alam, PhD from Patent AI Lab, illustrates this balance perfectly:
Relying on Boolean alone is negligent (you will miss art). Relying on Vector alone is dangerous (you will get noise).
This hybrid approach enables professionals to identify 99% of prior art while minimizing false positives. The result? Faster and more reliable patent searches.
Time and Efficiency Gains
The time savings with AI-powered semantic search are dramatic. Complex patent searches that once required 100 billable hours can now be completed in just 20, representing an 80% reduction in time. For example, biotechnology companies have reported saving 10–15 hours per patent application thanks to AI-assisted tools.
In October 2024, Laurence Brown demonstrated this efficiency using Patently's Vector AI tool. He searched for "in-ear headphones with noise isolating tips" with a priority date before 2000. Within five minutes, he filtered 300 results to Sony applications and identified the specific patents he needed. Andrew Crothers, Creative Director at Patently, summed it up well:
With Elastic, it's like having a patent attorney with decades of experience guiding every search.
Better Collaboration and Decision-Making
The precision and speed of semantic tools also enable better collaboration across teams. By allowing natural language queries, semantic search makes patent research accessible to R&D teams, product managers, and portfolio analysts - even those without extensive training in Boolean operators. Inventors can perform their own preliminary novelty checks, reducing the load on patent departments.
This technology shifts the focus of IP professionals from building complex search queries to higher-value tasks like framing intent, validating AI outputs, and uncovering competitive insights. In fact, using AI for infringement risk assessments can save companies between $20,000 and $50,000 per case by avoiding external counsel costs. As one Director of IP & Litigation at a cybersecurity firm noted:
If I can give the executive team an answer in a few minutes, that's priceless. Patlytics makes me look good to my boss, which is always a sound investment.
Conclusion
Semantic similarity has reshaped how patent professionals conduct prior art searches and analyze portfolios. By moving beyond simple keyword matching to a deeper understanding of technical concepts, this approach tackles the problem of missing relevant patents due to variations in terminology. For instance, it bridges terms like "autonomous vehicle" and "self-driving car" or uncovers multiple expressions for "cell phone", ensuring no critical information slips through the cracks.
The benefits in terms of efficiency and accuracy are hard to ignore. Some firms have reported cutting down complex searches from 100 hours to just 20, while biotechnology companies have saved 10–15 hours per patent application. It also mitigates risks by identifying prior art that may be intentionally vague, bypassing traditional keyword-based detection methods.
This technology also makes patent research more accessible. With natural language queries, inventors and R&D teams can perform initial novelty checks without needing to master complex Boolean logic. This frees up patent professionals to concentrate on strategic and high-value legal tasks. Additionally, AI-driven similarity scores provide a clear, measurable way to evaluate relevance and prioritize reviews.
Today’s patent workflows often integrate semantic search with traditional Boolean methods, ensuring both extensive coverage and precise results when navigating vast patent databases.
Ultimately, semantic similarity is revolutionizing the patent lifecycle - from invention intake to litigation and licensing decisions. It delivers faster insights, lowers costs, and enhances strategic decision-making at every step of intellectual property management.
FAQs
What is semantic similarity in patent search?
Semantic similarity in patent search focuses on assessing how closely two patents align in terms of their meaning, context, and technical details. Instead of relying on traditional keyword searches, this approach leverages AI and natural language processing (NLP) to understand synonyms, subtle technical distinctions, and the intent behind the text. This makes it easier for patent professionals to uncover prior art, evaluate potential infringement risks, and discover related inventions - an essential tool for navigating the often complex and technical language found in patents.
Why combine semantic search with Boolean filters?
Combining semantic search with Boolean filters enhances patent searches by leveraging semantic understanding to uncover related concepts and connections. This method goes beyond keyword-based queries, helping to identify relevant prior art that might otherwise be overlooked. The result? Broader and more accurate search outcomes.
How can I reduce false positives in vector search results?
To cut down on false positives in vector search results, it’s important to use filtering strategies that refine the search space and improve accuracy. This might involve applying advanced filtering techniques specifically designed for your vector search system. These approaches can help deliver results that are more relevant and precise.