Domain Ontologies in Patent Similarity Algorithms
Intellectual Property Management
Apr 29, 2026
How domain ontologies, SAO/FOP models, and hybrid vector methods sharpen patent similarity, retrieval, and classification—plus trade-offs.

Patent similarity algorithms often struggle to fully understand the technical meaning of inventions. Traditional methods rely on keywords, which miss the relationships between terms and lack context. Domain ontologies solve this by organizing concepts and their relationships into structured frameworks, enabling deeper semantic analysis.
Here’s what you need to know:
Domain ontologies define specialized concepts and relationships within fields like engineering or medicine, offering a structured way to analyze patents.
SAO models (Subject-Action-Object) help capture functional relationships, such as "motor controls valve", improving retrieval accuracy by 43%.
Challenges with keywords: They ignore word order, relationships, and context, making it hard to differentiate between similar but technically distinct patents.
Ontology benefits: Better semantic understanding, stronger contextual relevance, and improved patent analysis and entity extraction.
Trade-offs: Ontology-based methods require more computational resources and expertise compared to simpler keyword or vector-based approaches.
Bottom line: Domain ontologies provide a more precise way to analyze patents, especially for tasks like infringement detection and novelty evaluation, though they come with added complexity and resource demands.
Semantic Indexing of Unstructured Documents Using Taxonomies and Ontologies
How Domain Ontologies Improve Patent Similarity Algorithms
Domain ontologies are reshaping how algorithms interpret patent documents by introducing structured knowledge that goes beyond traditional methods. Instead of viewing patents as mere collections of words, these systems analyze the semantic relationships and technical hierarchies within the text. This approach addresses the limitations of keyword-based methods by incorporating word order, hierarchical structures, and functional connections between components.
Better Semantic Understanding
With ontologies, algorithms can grasp the hierarchical relationships and synonym networks that define technical terms. For instance, a Function-Object-Property (FOP) framework captures intricate "property-parameter" details that standard keyword analysis often misses. Imagine a patent describing a motor controlling a valve - an ontology-based system doesn’t just see "motor" and "valve" as isolated terms. It understands their functional relationship and technical hierarchy.
SAO-based frameworks, which focus on extracting complex entities and their functional connections, significantly improve retrieval accuracy - by 43% compared to keyword methods and 26% over document embeddings. These frameworks excel at capturing the "semantic direction" of technical claims, leading to more contextually relevant similarity assessments.
Stronger Contextual Relevance
Ontologies enhance how algorithms identify deeper technical connections by analyzing relationships within a structured knowledge network. Unlike traditional methods that treat word co-occurrences equally, ontology-based systems examine "reachable nodes" in a feature network to separate functional relationships from non-functional ones.
The results are impressive. Advanced configurations that combine SAO embeddings with clustering-based weighting reduced the average ranking position of relevant patents from 5.7 to 2.7 in retrieval tasks. Additionally, knowledge-based similarity thresholds - typically between 0.4 and 0.6 - have proven effective for distinguishing between closely related and unrelated patents.
Managing Computational Challenges
While ontology-based methods enhance semantic accuracy, they also introduce computational demands. To address this, optimization techniques are essential. One effective approach involves applying K-means clustering weights, enabling algorithms to prioritize high-value semantic features. This method has shown a 32% improvement in performance over unweighted baselines.
Another strategy involves using averaged embeddings of semantic structures like FOP to streamline processing without sacrificing accuracy. By combining pre-trained patent vectors with clustering-based weighting, systems achieve a balance between computational efficiency and retrieval precision. Platforms like Patently, which utilize semantic search powered by Vector AI, rely on these techniques to analyze large patent databases effectively while maintaining the depth of understanding provided by domain ontologies.
Applications of Domain Ontologies in Patent Analysis
Domain ontologies bring a deeper semantic understanding to patent analysis, offering practical benefits across several key areas. These include classification, entity extraction, and semantic search - each addressing unique challenges in managing and interpreting patent data.
Ontology-Driven Patent Classification
Ontologies create structured networks where each node represents a specific technical feature derived from patent metadata. These networks allow for a more nuanced analysis of patent relevance by examining interconnected technical features. Compared to traditional methods, this approach has shown better performance on USPTO datasets. For example, the PatentSBERTa model, which merges Sentence-BERT embeddings with K-Nearest Neighbors classification, demonstrated 54% accuracy and an F1 score exceeding 66% when predicting Cooperative Patent Classification (CPC) codes at the subclass level across nearly 1.5 million patents. By leveraging domain ontologies, this hybrid method enhances semantic relatedness calculations between word pairs, enabling better word sense disambiguation and more precise mapping of patent text to custom taxonomies.
Entity and Relationship Extraction in Patents
Patent language is notoriously dense, making it challenging to extract meaningful entities and relationships using basic keyword approaches. SAO (Subject─Action─Object) frameworks step in to capture functional connections, offering a more structured way to extract entities. For instance, instead of simply identifying "motor" and "valve" as separate terms, these frameworks identify their functional relationships, such as "motor controls valve" or "motor actuates valve mechanism."
Subject─Action─Object (SAO) structures provide a promising semantic representation; however, their effectiveness has been limited by the scarcity of specialized Semantic Text Similarity (STS) datasets and the lack of comprehensive evaluations.
This methodology clarifies the technical logic within patent claims, allowing for a more detailed understanding of how individual components interact.
Supporting Semantic Search with Vector AI
By combining ontologies with Vector AI, platforms like Patently, one of the top patent tools for IP professionals, enable natural language patent searches that go beyond keyword matching to understand conceptual meaning. For example, the system can recognize that "autonomous vehicle" and "self-driving car" describe the same concept, even when expressed differently across documents or languages. This is achieved through ontology-based semantic knowledge extensions and clustering-based weighting strategies. These optimizations prioritize the most technically important elements of a patent's vector embedding. Additionally, knowledge-based thresholds (ranging from 0.4 to 0.6) are used to differentiate closely related patents, ensuring accurate prior art searches.
Ontology-Based vs. Non-Ontology Patent Similarity Methods
Patent Similarity Methods Comparison: Keyword vs Vector vs Ontology-Based Approaches
Ontology-based methods offer precise semantic understanding, but they come with added complexity in implementation. These methods leverage domain-specific ontologies to achieve deeper semantic insights, making them particularly effective in understanding nuanced technical relationships. Let’s break down how these approaches compare.
Advantages of Ontology-Based Approaches
Ontology-based methods excel at interpreting technical relationships within patent language. For example, the Function-Object-Property (FOP) structure can differentiate between phrases like "motor controls valve" and "valve controls motor." This level of precision is critical when subtle differences carry significant meaning.
Teng, Hao et al. (Journal of Informetrics) noted: "Current methods such as keywords, co‐word analysis and even the Subject-Action-Object (SAO) algorithms, are not quite reasonable for the patent similarity calculation due to the lack of fine‐grained semantic knowledge, 'property‐parameter' features and flexible 'functional or non‐functional' combinations."
Research by National Chiao Tung University underscores the effectiveness of ontology-based methods. Their findings show that leveraging patent networks - structured graphs of metadata - outperforms traditional approaches by identifying connections between nodes.
However, these benefits come with some trade-offs.
Limitations of Ontology-Based Approaches
The main drawback of ontology-based methods lies in their resource demands. Developing domain-specific ontologies requires significant expertise to accurately extract entities and relationships. As Xuefeng Wang and colleagues from the Beijing Institute of Technology observed, calculating patent similarity with high precision can be a slow and resource-intensive process.
Additionally, implementing these methods is inherently complex. Unlike basic keyword approaches, ontology-based systems involve multiple advanced steps. For instance, they may require K-means clustering for weighted strategies or knowledge extensions to assess the global importance of sequence structures. This technical depth increases computational costs and limits scalability compared to simpler methods.
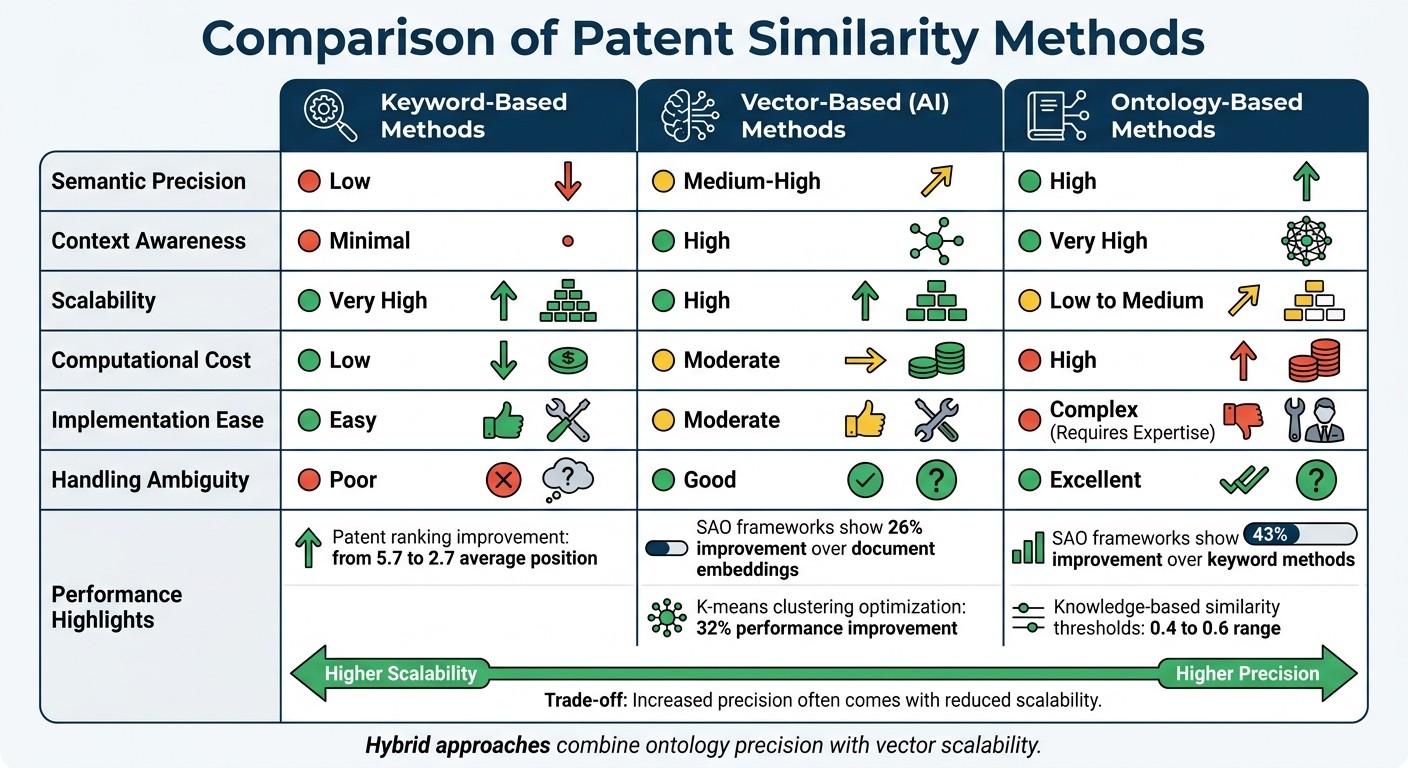
Comparison Table: Ontology-Based vs. Non-Ontology Methods
Here’s a quick look at how different methods stack up:
Feature | Keyword-Based Methods | Vector-Based (AI) Methods | Ontology-Based Methods |
|---|---|---|---|
Semantic Precision | Low | Medium-High | High |
Context Awareness | Minimal | High | Very High |
Scalability | Very High | High | Low to Medium |
Computational Cost | Low | Moderate | High |
Implementation Ease | Easy | Moderate | Complex (Requires Expertise) |
Handling Ambiguity | Poor | Good | Excellent |
A Balanced Approach
To address the strengths and weaknesses of each method, some systems, like Patently License, combine ontology-based techniques with vector embeddings. This hybrid approach balances precision and scalability. By using ontology structures for technical relationship analysis and vector-based methods for broader scalability, such systems are well-suited for tasks like infringement detection and novelty evaluation. These high-stakes applications demand both accuracy and contextual understanding, where missing even a single relevant patent can lead to significant legal and financial risks.
Conclusion
Domain ontologies have transformed how patent similarity algorithms operate, moving beyond simple keyword matching to adopt structured, semantic frameworks. These advanced methods capture the nuanced semantic relationships that traditional approaches often fail to recognize. Research shows that SAO-based frameworks significantly boost retrieval accuracy and improve the ranking of relevant patents when compared to keyword-based techniques.
By enhancing semantic understanding, the integration of ontologies with AI technologies has opened the door to powerful hybrid systems. For example, graph-augmented models like RA-Sim combine textual encoders with Graph Attention Networks, utilizing both local context and global citation data from the USPTO's database of 7.6 million utility patents and 102 million citations. These systems employ self-supervised learning, removing the need for expensive expert labeling and making patent analysis more efficient and accessible.
"Ontologies play a crucial role in enhancing the transparency, interpretability, and accountability of LLMs by providing structured representations of domain knowledge."
Dr. Nicolas Figay
Beyond improving search precision, ontology-based approaches bring essential structural validation to critical IP processes like infringement detection and novelty evaluation. They impose structural constraints on AI outputs, reducing the risk of errors while enabling innovative solutions. Platforms such as Patently exemplify this by incorporating semantic search powered by Vector AI, which combines the accuracy of ontological frameworks with the scalability of AI-driven systems.
The combination of structured knowledge and AI capabilities represents a major advancement in intellectual property management. As Benny Cheung from Dynamind Research insightfully puts it:
"Constraints do not limit creativity but enable it: just as grammar makes poetry possible, ontology makes structured generation possible."
FAQs
Do I need a custom ontology for each technology area?
When deciding if you need a custom ontology, it largely comes down to the complexity and specific needs of your technology area. Domain-specific ontologies are particularly useful because they are designed to capture the precise concepts, terminology, and relationships relevant to that field. This refinement can significantly improve how patent similarity algorithms perform.
While general ontologies can serve as a starting point, customizing them ensures they align with the unique characteristics of your domain. This tailored approach can make similarity assessments far more accurate and reliable.
How are SAO or FOP structures extracted from patent text?
When patent documents are analyzed, SAO (Subject-Action-Object) or FOP (Function-Operation-Property) structures are created to summarize key technological findings and the relationships between components. While SAO triples offer a high-level overview, FOP structures dive deeper, providing richer semantic details. This added depth makes FOP structures particularly useful for patent similarity analysis, as they reveal more nuanced insights into the technological content.
When is an ontology-based approach worth the extra compute and effort?
An ontology-based approach proves useful when it enhances the precision of tasks like patent classification, similarity analysis, or semantic interpretation. This becomes particularly important in cases involving complex or highly specialized fields, where traditional methods often fail to grasp the subtle or intricate relationships present in patent documents.