Study: AI Accuracy in Citation Relevance Scoring
Intellectual Property Management
Feb 22, 2026
Patent AI models beat general systems in citation relevance using full-text semantics, GNNs and hybrid extraction to improve prior-art search.

AI is transforming how citations are evaluated in patents. Traditional methods focus on simple counts or document-level references, but AI tools analyze full texts to determine how well citations align with patent claims. A 2025 study showed that AI models like Pat-SPECTER and PaECTER outperform general-purpose models by ranking relevant citations more effectively. These systems use advanced techniques like semantic graphs and machine learning to improve accuracy and reduce noise from irrelevant references.
Key Findings:
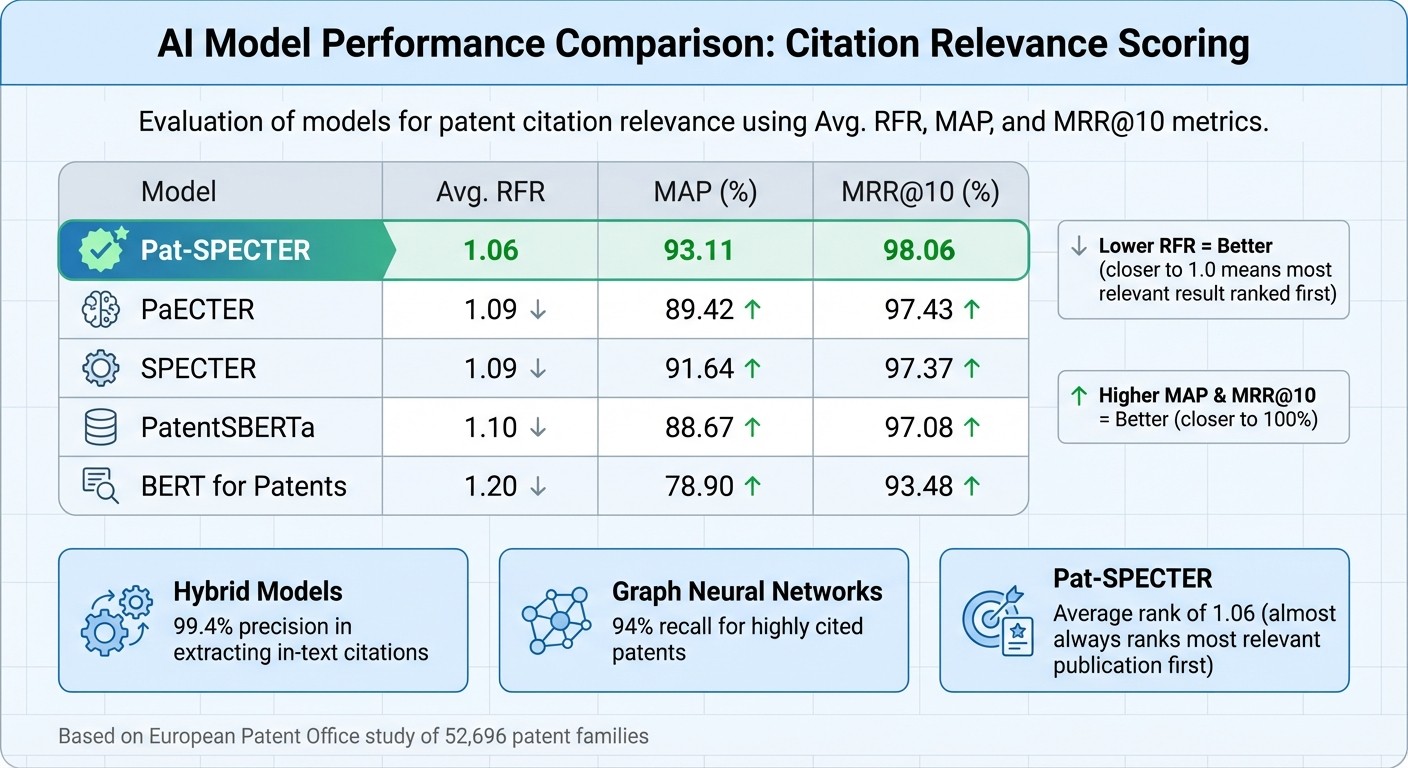
Pat-SPECTER: Ranked first in citation relevance with an average rank of 1.06 and an MRR@10 score of 98.06%.
Hybrid Models: Achieved 99.4% precision in extracting in-text citations.
Graph Neural Networks (GNNs): Reached 94% recall for identifying highly cited patents.
Challenges:
Limited in-text citations and metadata errors hinder accuracy.
Imbalanced datasets make identifying nuanced cases harder.
Future Directions:
Combining machine learning with rule-based heuristics.
Using examiner-added citations to reduce bias.
Focusing on full-text analysis for better claim verification.
AI tools are becoming indispensable for patent professionals, improving citation analysis efficiency and aligning with examiner practices.
Key Findings from the Study
AI Model Performance Comparison for Patent Citation Relevance Scoring
Research Objectives and Scope
The study set out to automate the identification of inline citations and match them to bibliographic references while calculating relevancy scores between citing and cited documents. This approach goes beyond simple citation counts, using AI to analyze the entire text of patents and scholarly articles instead of just abstracts or front-page details.
A European Patent Office study reviewed 52,696 patent families and roughly 750,000 test cases to assess eight different language models. The challenge was to rank five relevant scientific publications from a pool of 30 documents (five relevant and 25 irrelevant), testing which AI model could most effectively pinpoint non-patent literature. Other research explored creating patent-specific document encoders, like PaECTER, to improve semantic similarity searches beyond what general-purpose models could achieve. These efforts provided a foundation for evaluating model performance across different benchmarks.
Performance Results
The results highlighted the strength of patent-focused AI models. Pat-SPECTER, fine-tuned with patent data, achieved an average first relevant rank (RFR) of 1.06 and an MRR@10 score of 98.06, almost always ranking the most relevant publication first. Hybrid methods combining machine learning with manually tuned heuristics reached 99.4% precision in extracting in-text patent-to-article citations, with 87.6% coverage. Additionally, an automated citation-matching system scored a solid 0.78 on the Normalized Discounted Cumulative Gain (NDCG) scale, further showcasing its effectiveness.
AI Model Comparison
The comparative analysis revealed clear distinctions in model performance. Pat-SPECTER surpassed its predecessor, SPECTER, in cross-corpus evaluations, ranking relevant publications more accurately. The PaECTER model excelled with an average rank of 1.09 when compared against 25 unrelated patents, outperforming general-purpose models like E5, GTE, and BGE.
Model | Avg. RFR | MAP | MRR@10 |
|---|---|---|---|
Pat-SPECTER | 1.06 | 93.11 | 98.06 |
PaECTER | 1.09 | 89.42 | 97.43 |
SPECTER | 1.09 | 91.64 | 97.37 |
1.10 | 88.67 | 97.08 | |
1.20 | 78.90 | 93.48 |
Key factors driving these results included the use of patent-specific training datasets and the development of semantic graphs to map technological relationships between documents. Notably, lightweight models like Qwen3 (featuring 1.7B and 4B parameters) matched the performance of larger commercial systems while using far fewer computational resources. These findings highlight how AI can precisely assess citation relevance, emphasizing the importance of integrating such models into top patent analysis tools.
Applications for Patent Analysis
Improving Prior Art Search
AI-enabled patent analysis tools are transforming how prior art searches are conducted. Unlike traditional keyword matching, models like PaECTER use patent-specific algorithms to create numerical representations of documents. This allows them to identify similar inventions even when different terminology is used. Impressively, these systems achieve an average rank of 1.32 when tested against 25 irrelevant patents, cutting down review times significantly.
One major challenge in patent analysis is dealing with the overwhelming number of irrelevant citations included by applicants to obscure relevant references. AI relevance scoring addresses this by analyzing the deeper connections between documents rather than just surface-level metadata. These systems can even highlight specific paragraphs within lengthy patent specifications, directing attention to the sections that are critical for determining patentability.
AI also goes beyond simple document retrieval. It categorizes citation relationships into detailed groups such as Supported, Partially Supported, Unsupported, or Uncertain. This granular classification helps patent drafters refine applications before submission and provides examiners with clear evidence trails during reviews. By streamlining prior art retrieval and analysis, these AI advancements seamlessly integrate into and enhance examiner workflows.
Alignment with Examiner Practices
AI citation tools are also designed to align closely with the methods used by patent examiners. Instead of relying solely on keyword searches, these tools derive context from CPC codes, specifications, and abstracts. This approach improves both applicant strategies and the examiner’s review process. For instance, the PK-Bert model improved recall for citation recommendations by 2.15% compared to the standard BERT model. This demonstrates how examiner-informed training data can improve performance in practical settings.
In October 2025, the United States Patent and Trademark Office (USPTO) introduced the Artificial Intelligence Search Automated Pilot (ASAP!) Program. This program offers applicants an AI-Assisted Search Results Notice (ASRN), which includes a top ten list of prior art issues before formal examination begins. Under Secretary John A. Squires highlighted the program's impact:
"Quality starts at filing - and our enterprising examiners have developed a cadre of new tools that re-imagine workflows and attack thorny chokepoints that constrain productivity, throughput, and ultimately quality for new applicants".
This early-stage transparency allows applicants to address potential issues or risks before the formal review process. Using the same AI-generated insights that examiners rely on, applicants can make informed decisions about amendments or patentability risks, ensuring their strategies are better aligned with examination standards.
Limitations and Future Directions
Challenges in Data Quality and Class Imbalance
AI citation scoring faces some tough hurdles, especially when it comes to data quality. Errors in bibliometric metadata - like typos in author names or titles - can throw automated systems off track. These inaccuracies make matching citations a lot harder than it should be.
Another issue is the decline in in-text citations over the last five decades. In the past, 80% of patent-to-article citations were in-text, but now that number has dropped to less than 40%. Many datasets only include front-page citations, ignoring in-text references that often reveal an inventor's deeper understanding. As Matt Marx, a professor at Cornell University, pointed out:
"Failing to capture in-text citations leads to understating the role of academic science in commercial invention".
Then there's the problem of class imbalance. Most citation datasets are flooded with "Supported" or "Relevant" examples, leaving very few negative samples like "Unsupported" or "Uncertain" citations. This imbalance makes it hard for AI models to accurately identify less straightforward cases. To make matters worse, nuanced classifications - such as "Partially Supported" or "Uncertain" - require more advanced reasoning and higher-quality data.
Traditional citation formats add another layer of difficulty. They often reference entire documents instead of pinpointing the exact sections that back a claim. This makes it tricky for AI to figure out which specific parts of the source text are relevant. As a result, standard machine learning models often fall short in citation extraction tasks compared to generative AI patent drafting tools and hybrid systems that combine ML with custom heuristics.
Opportunities for Improvement
Despite these challenges, there are promising ways to improve citation relevance scoring. One effective approach is using hybrid methods that blend machine learning with rule-based heuristics. For instance, tools like GROBID can achieve 99.4% precision and 88% recall for error-free references. By combining the strengths of automation with human-like rules, these systems can address many of the limitations seen in purely AI-driven methods.
Graph Neural Networks (GNNs) also show a lot of promise. By analyzing semantic graphs, GNNs can capture the structural relationships between citations, leading to recall rates as high as 94% for predicting highly cited patents. Instead of focusing solely on isolated text, these models provide a broader and more connected view of citation patterns.
Training models on examiner-added citations - rather than those submitted by applicants - can further improve accuracy. Examiner-added references tend to be less biased, as they aren't influenced by strategic or opportunistic citing. This shift aligns AI systems more closely with regulatory standards.
Another exciting avenue is fine-tuning lightweight language models, which can rival the performance of large commercial systems while requiring far less computational power. This makes large-scale citation verification more practical and efficient.
Finally, moving toward full-text analysis could be a game-changer. Instead of relying only on metadata, advanced systems could analyze entire patent documents to verify whether specific claims are genuinely supported by the cited text. This approach would not only improve accuracy but also increase transparency by linking claims directly to the supporting snippets. Together, these strategies address many of the core challenges in AI citation scoring.
How Patently Uses Study Insights
Patently's FAB Citation Browser
Patently's Forward and Backward (FAB) Citation Browser is designed to help patent professionals pinpoint relevant citations with accuracy. One standout feature is its ability to differentiate between applicant-submitted and examiner-added citations, which is crucial for evaluating a patent's defensive strength.
Using advanced Graph Neural Network (GNN) techniques and incremental indexing powered by Hierarchical Navigable Small-World (HNSW) graphs, the browser achieves an impressive 94% recall for highly cited patents. It also updates in real time to include newly issued patents, ensuring users can swiftly identify impactful prior art.
The tool goes a step further by combining in-text citations with front-page references, offering a full-spectrum view of citation relevance. As Stan Zurek, Head of Research and Innovation at Megger Instruments, remarked:
"Patently has become an indispensable tool for us, playing a crucial role in various aspects of our Research and Innovation processes".
Semantic Search with Vector AI
Patently enhances its citation analysis with semantic search capabilities, taking patent research to the next level. This approach refines citation relevance by identifying patents that share contextual and functional similarities, rather than relying solely on keyword matches.
With Vector AI, Patently captures the full semantic meaning of patent language. This method prioritizes the descriptive context of citations, aligning with the way examiners evaluate prior art - through functional language and problem–solution framing. Instead of focusing on exact terms, the system identifies patents based on their technical intent, making it easier to uncover relevant connections.
One of the standout features is semantic prior-art searching, which shifts the focus from keyword frequency to the underlying technical goals of a patent. By employing a two-stage deep learning system for citation recommendations, Patently achieves a Mean Reciprocal Rank (MRR) of 0.2506, outperforming traditional approaches through its emphasis on technological context.
Patently integrates this semantic technology into its FAB Citation Browser, grouping related patents into proprietary "Genetic families". These clusters make it easier for professionals to identify and prioritize impactful references, cutting down the time spent on irrelevant results. Together, these tools streamline the process of finding high-value citations, saving time and improving research outcomes.
Conclusion
Key Takeaways
Recent advancements in AI-powered citation relevance scoring are reshaping how patent professionals evaluate prior art. Tools like PaECTER, which are fine-tuned using examiner-added citation data, consistently perform better than general-purpose text embedding systems in tasks like similarity analysis and citation prediction.
Graph Neural Network methods have demonstrated impressive results, achieving 94% recall for highly cited patents, while automated systems for identifying in-text citations have reached a 97% F-score.
Moving beyond front-page citations to focus on in-text citation analysis offers a more accurate reflection of technological connections and inventor insights. As noted by Verluise, C., Cristelli, G., Higham, K., and de Rassenfosse, G.:
"In-text citations are more likely to originate from inventors and signal meaningful technological linkages."
AI-driven semantic search tools are also proving to be game-changers, prioritizing technical intent over simple keyword matching. This shift allows professionals to uncover 40–60% more relevant patents compared to traditional search methods. By aligning more closely with examiner practices, these tools emphasize deeper technological connections rather than surface-level matches.
The practical benefits are hard to ignore. AI-powered patent search systems can cut search times by 60–70%, while delivering a 3–5× return on investment by improving the quality of Freedom to Operate or novelty searches and reducing billable attorney hours. Even lightweight, fine-tuned models are now matching the performance of larger commercial systems, making advanced citation analysis accessible to organizations of all sizes.
FAQs
How does AI decide whether a citation really supports a patent claim?
AI determines if a citation backs up a patent claim by examining the entire text of both the patent and the cited source through advanced natural language processing. It evaluates semantic similarity and contextual relevance to confirm whether the citation genuinely supports the claim. Additionally, machine learning models play a role in identifying and validating in-text citations. This approach helps ensure that citations are both accurate and relevant to the patent's details.
Why do patent-specific models outperform general-purpose AI in citation ranking?
Patent-specific models outperform in citation ranking due to their training on specialized datasets. This focused training helps them understand the distinct language, claim structures, and intricate technical details found in patents. As a result, they provide more precise and relevant evaluations than general-purpose AI models.
What data problems most often cause AI citation scoring mistakes?
The most frequent problems involve semantic citation errors, where sources are misrepresented, fabricated references, and incorrect attribution of sources. These issues typically arise due to challenges in accurately analyzing source material and grasping the intricate connections between citations.