AI Patent Clustering for SEP Analysis
Intellectual Property Management
Apr 15, 2026
Overview of K-Means, Hierarchical and DBSCAN for grouping SEPs, spotting over-declarations, and informing FRAND licensing.

AI is transforming how patent professionals analyze Standard-Essential Patents (SEPs). By automating tasks like grouping patents and identifying patterns, AI clustering tools such as K-Means, Hierarchical Clustering, and DBSCAN streamline processes that were once manual and error-prone. These methods help categorize patents by technology, detect over-declarations, and assess compliance with FRAND (Fair, Reasonable, and Non-Discriminatory) licensing terms.
Key highlights:
K-Means: Groups patents by technical areas but requires pre-set cluster numbers.
Hierarchical Clustering: Builds nested relationships, ideal for exploratory analysis without predefined clusters.
DBSCAN: Excels at spotting outliers and over-declared patents using density-based analysis.
AI also aids in benchmarking portfolios, mapping technologies, and supporting FRAND negotiations by offering data-driven insights into patent relevance and licensing opportunities. Platforms like Patently integrate top patent tools, providing semantic search, collaborative project management, and analytics for SEP landscapes.
AI clustering is reshaping SEP workflows, enabling faster, more accurate analysis and better decision-making in patent management.
GSLC Tim Pohlmann Welcome Remarks - SEP determination using AI
AI Clustering Techniques for SEP Analysis
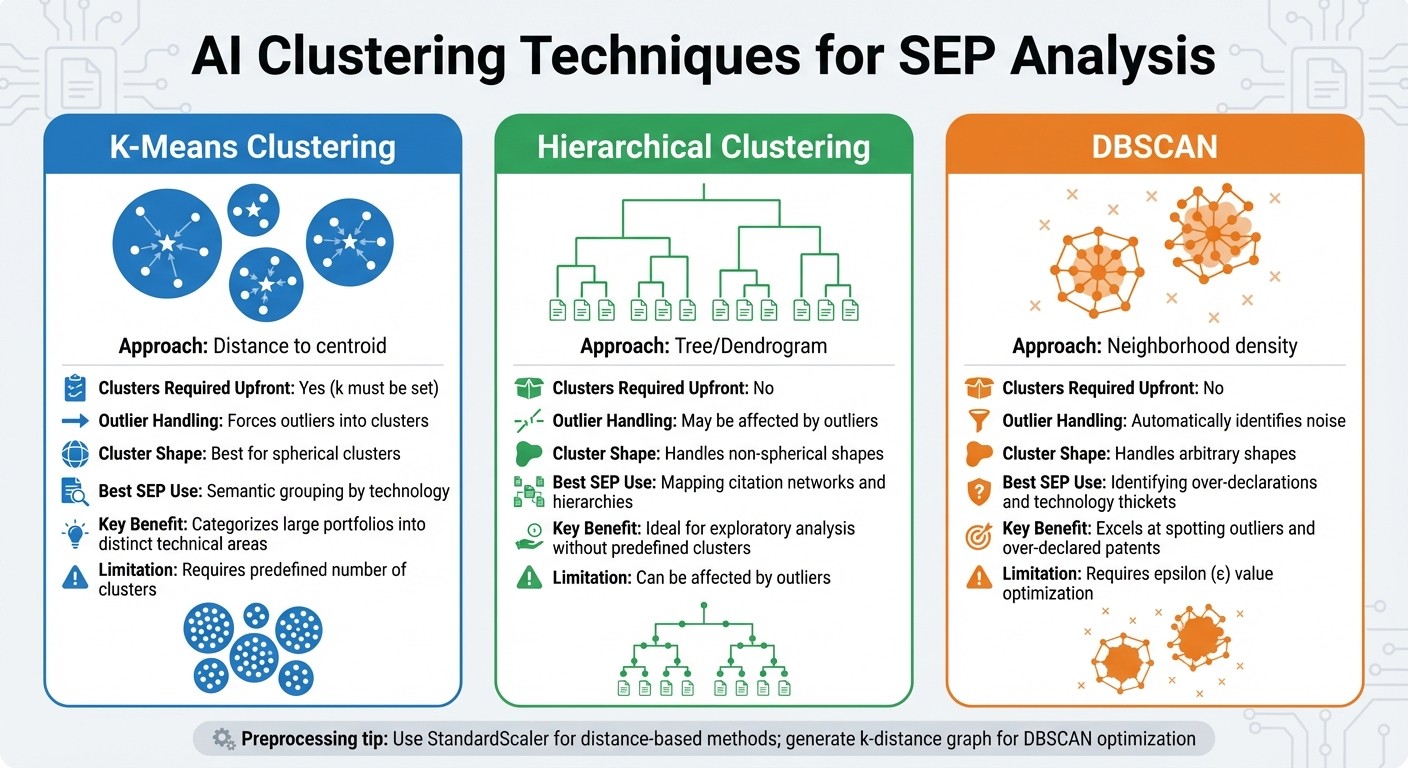
Comparison of AI Clustering Methods for SEP Patent Analysis
Three AI clustering methods simplify the analysis of SEP portfolios, each offering unique benefits for organizing and interpreting patent data.
K-Means clustering divides patent vectors into k groups by minimizing the distance to each group's centroid. This method helps categorize large portfolios into distinct technical areas, such as radio interface, core network, or codec technologies. Licensing teams can then align patents with relevant sections of technical standards. However, it requires defining the number of clusters (k) beforehand and assigns outliers to the nearest cluster, which may not always be ideal.
Hierarchical clustering creates dendrograms to uncover nested relationships among patents. This method is particularly useful for exploring citation networks when the number of clusters isn’t known in advance. By "cutting" the dendrogram at different levels, analysts can examine both broad categories and finer sub-clusters. This makes it a go-to approach for exploratory analysis, especially when the portfolio's structure is uncertain.
Moving away from hierarchical methods, DBSCAN (Density-Based Spatial Clustering of Applications with Noise) takes a density-focused approach. It identifies densely packed regions in the data while labeling isolated points as noise. This feature is especially valuable in SEP analysis, as patents marked as noise often warrant essentiality challenges. DBSCAN’s ability to filter out over-declared patents makes it a strong choice for tackling technology thickets and ensuring cleaner, more actionable data.
To enhance the accuracy of these methods, preprocessing is key. For distance-based techniques, standardizing patent data (e.g., with StandardScaler) ensures consistent results. For DBSCAN, generating a k-distance graph helps determine the optimal epsilon (ε) value, improving the clustering process and boosting the quality of insights.
Feature | K-Means | Hierarchical | DBSCAN |
|---|---|---|---|
Approach | Distance to centroid | Tree/Dendrogram | Neighborhood density |
Clusters Required Upfront | Yes (k must be set) | No | No |
Outlier Handling | Forces outliers into clusters | May be affected by outliers | Automatically identifies noise |
Cluster Shape | Best for spherical clusters | Handles non-spherical shapes | Handles arbitrary shapes |
Best SEP Use | Semantic grouping by technology | Mapping citation networks and hierarchies | Identifying over-declarations and technology thickets |
These clustering methods provide a strong foundation for advanced SEP analysis, paving the way for deeper insights in the following sections.
Applications of AI Clustering in SEP Analytics
Using methods like K-Means, hierarchical clustering, and DBSCAN, AI clustering brings practical insights to SEP (Standard-Essential Patent) analytics. Here's how these techniques make a difference.
Technology Mapping and SEP Portfolio Benchmarking
AI clustering transforms patent data into visual maps that align SEP portfolios with specific technical standards. By grouping patents based on semantic similarity, it becomes easier to spot dominant players in various technology areas. These visualizations not only highlight strengths but also reveal gaps in a portfolio.
Clustering algorithms also aid in benchmarking SEP portfolios. They organize patents by technical domain and compare them against industry standards and competitors' holdings. This analysis helps guide critical decisions, such as whether to acquire additional patents or adjust an existing portfolio for better alignment with market trends and standards.
Measuring SEP Clustering Performance
To ensure clustering methods are effective, it's important to evaluate their accuracy using specific metrics. The F-Measure, which balances precision and recall, assesses clustering quality. Meanwhile, the Sum of Square Error (SSE) measures how closely patents cluster around their centroids. Computational efficiency also matters - K-Means, for instance, operates at O(nkt), making it faster for large datasets compared to K-Medoids, which operates at O(k(n-k)²).
An example worth noting is Fuzzy Ontological Document Clustering (FODC). This method leverages semantic webs to match patents with clusters, achieving higher F-Measure scores than Key-Phrase K-Means, which often relies on fragmented sentences that may lack technical depth. This distinction is particularly valuable when analyzing thousands of SEP declarations across multiple standards.
Algorithm | Computational Complexity | Key Metric for Accuracy |
|---|---|---|
K-Means | O(nkt) | SSE (Sum of Square Error) |
K-Medoids | O(k(n-k)²) | SSE (Sum of Square Error) |
D-M (Density Means) | O(ni) | SSE (Sum of Square Error) |
FODC | N/A | F-Measure (High) |
FRAND Compliance and Licensing Opportunities
Clustering techniques also play a crucial role in FRAND (Fair, Reasonable, and Non-Discriminatory) licensing analyses. By grouping patents, these methods help distinguish between those that cover core features and those that address peripheral elements. Patents tightly clustered around key standard specifications are more likely to be truly essential, giving licensors a stronger position in FRAND negotiations. On the other hand, patents outside these clusters may need further review to confirm their essentiality.
Data from clustering also supports FRAND compliance by offering an objective view of actual SEP coverage. Licensing teams can use this information to justify royalty rates based on true SEP coverage rather than relying solely on the number of declared patents. Additionally, clustering can identify "white spaces" where no single company dominates, signaling potential for new licensing agreements or cross-licensing opportunities.
How Patently Supports SEP Clustering and Analysis
Patently's platform simplifies the process of managing large SEP portfolios and navigating complex standard declarations by streamlining SEP clustering and analysis.
AI Semantic Search with Vector AI
Patently's Vector AI dives deep into the meaning behind patent texts, uncovering semantic relationships and grouping SEPs based on technical similarities. This method automatically accounts for variations in synonyms. For instance, when analyzing 5G patents tied to beamforming, Vector AI can link related concepts like antenna array processing or spatial filtering, even if the patents are written in different languages.
Collaborative Project Management for SEP Analysis
SEP analysis often requires teamwork, especially when dealing with multiple client matters or standards. Patently's matter-centric structure organizes tasks into collaborative patent projects, allowing separate workflows for standards such as 4G LTE and 5G NR. With role-based access controls, users can assign specific permissions, ensuring ethical boundaries are upheld in cases involving conflicting client matters. Automated notifications further enhance collaboration, reducing the chances of workflow errors.
SEP Data Analysis Tools
Patently provides analytics tools tailored for 4G and 5G SEP landscapes. These tools map out technology coverage and portfolio positioning, making it easier to spot licensing opportunities by identifying coverage gaps or overlapping patent holders. Additionally, users can generate exportable reports to support FRAND negotiations. Together, these features enable patent professionals to conduct thorough SEP analyses, paving the way for more detailed discussions and insights.
Conclusion: The Future of AI in SEP Analysis
Benefits of AI Clustering for Patent Professionals
AI clustering is reshaping the way patent professionals handle large SEP portfolios. By automatically grouping patents based on technical similarities, citation patterns, or density relationships, these algorithms streamline portfolio management. What once took weeks - like identifying FRAND non-compliance, benchmarking portfolios, or finding coverage gaps - can now be done in minutes. This efficiency is becoming increasingly important as the industry moves toward AI-integrated standards.
With wireless standards advancing from AI-enhanced 5G to a potential AI-driven 6G core, the ability to process semantic relationships across languages and technical nuances gives patent teams a clear advantage. These capabilities not only speed up decision-making but also enhance strategic planning, making them invaluable for licensing negotiations and portfolio assessments.
Next Steps for SEP Analytics with AI
To fully embrace AI-powered SEP workflows, a phased approach can help organizations transition smoothly. Start small by piloting AI tools on a specific patent pool or product line. This "Crawl" phase, lasting 1–3 months, allows teams to validate the approach. Once proven, expand efforts in the "Walk" phase to broader applications.
Integrating AI tools with existing IT systems through APIs ensures real-time data sharing and better collaboration across teams. Platforms like Patently, with their matter-centric design and role-based access, make it easier to incorporate AI into current workflows.
FAQs
How do I choose between K-Means, Hierarchical Clustering, and DBSCAN for SEP analysis?
Choosing between K-Means, Hierarchical Clustering, and DBSCAN depends on the nature of your data and your specific objectives:
K-Means: Works well with large datasets that have evenly sized, spherical clusters and when you already know the number of clusters in advance.
Hierarchical Clustering: A great choice when you want to explore hierarchical relationships or if you're unsure about the number of clusters.
DBSCAN: Perfect for identifying clusters with irregular shapes, managing noisy data, or handling datasets with outliers.
What data should I use to cluster SEPs (claims, specs, citations, or all of it)?
To get a well-rounded analysis, it's important to use every piece of available information - claims, specifications, and citations - when grouping standard-essential patents (SEPs). Taking this broader approach can reveal more detailed insights and lead to better decision-making.
How can clustering results support FRAND royalty and essentiality arguments?
AI-powered clustering in Standard Essential Patent (SEP) analysis plays a key role in pinpointing patents that genuinely matter. By cutting through over-declaration noise, it ensures that only the most relevant patents are factored into licensing discussions. This approach supports FRAND compliance by helping calculate royalties fairly and discouraging unfair practices.
Additionally, clustering uncovers patterns across different jurisdictions, making it easier to spot inconsistencies. It also enhances portfolio valuation and risk assessment, promoting greater clarity and fairness during licensing negotiations.