Best Practices for Patent Embedding Model Training
Intellectual Property Management
May 9, 2026
Clean patent data, use patent-specific embeddings, tune contrastive training and hard negatives, and validate with patent benchmarks.

Patent embedding models convert complex patent texts into numerical vectors, enabling systems to identify related concepts even when different terms are used, a core feature of AI-enabled patent analysis. This approach outperforms traditional keyword searches, which often miss 20%–40% of relevant results. However, general-purpose models struggle with legal and technical patent language. Here's how to address these challenges:
Data Preparation: Clean and organize patent data by removing duplicates, noise, and irrelevant content. Use techniques like MinHash deduplication and Byte-Pair Encoding for tokenization.
Model Selection: Choose patent-specific models like ModernBERT-base-PT or PatentSBERTa for better accuracy and speed. Consider architectures optimized for long texts and technical terms.
Training Optimization: Use larger batch sizes, higher masking probabilities, and loss functions like Multiple Negatives Ranking Loss to improve learning. Incorporate hard negatives and multi-task fine-tuning for better results.
Testing and Validation: Evaluate models using patent-specific benchmarks like PatenTEB and metrics like NDCG@100. Regularly test for semantic similarity and retrieval accuracy.
Training State-of-the-Art Sentence Embedding Models
Preparing Patent Data for Training
Training an effective patent embedding model starts with carefully preparing the data. Patent documents are often packed with legal jargon, technical details, and inconsistent formatting. To ensure the model learns meaningful patterns, rather than getting bogged down by irrelevant noise, the data must be cleaned and organized.
Structuring Patent Text Data
Patent documents are divided into sections like titles, abstracts, claims, and detailed descriptions, each serving specific legal and technical purposes. To prevent the model from losing focus on key details, long descriptions are broken into smaller chunks. Typically, chunks range from 200 to 800 tokens, striking a balance between maintaining context and preserving semantic clarity.
Different chunking methods are used depending on the goal:
Fixed-size chunking: Splits text every N tokens for simplicity but risks cutting sentences awkwardly.
Semantic chunking: Uses natural language processing to split at logical points, like paragraph or sentence boundaries.
Section-based chunking: Divides text by patent sections (e.g., claims, abstracts) to retain legal structure, which is especially useful for tasks like prior art searches.
For fixed-size chunking, adding overlaps (about 400 characters) between chunks helps retain context. Metadata, such as the section origin of each chunk, is also preserved to allow retrieval systems to prioritize critical sections like claims over less important boilerplate text.
Tokenization is the next step, where text is converted into tokens. Byte-Pair Encoding (BPE) is preferred over WordPiece tokenization for patent data. BPE handles frequent technical terms as single tokens while breaking rarer terms into subwords, creating a balanced vocabulary.
Managing Technical and Legal Terminology
Patents are a unique mix of technical precision and legal language. For instance, "consideration" in patent law refers to payment, and "articulated mechanical member" might mean "robot arm." Training data must connect these specialized concepts to ensure the model understands their context.
To address text inconsistencies, Unicode NFKC normalization and lowercasing are applied. This step ensures that visually similar characters, like "μ" (Greek mu) and "µ" (micro sign), are treated as identical, reducing unnecessary complexity.
Another challenge is antecedent basis, a legal rule requiring terms like "a motor" to be introduced before "the motor" can reference it. Datasets that maintain these reference chains are critical for preserving legal accuracy in embeddings.
High-quality datasets, such as the Derwent World Patents Index (DWPI), are invaluable. These sources provide expert-curated descriptions that simplify complex legal language, helping models generalize across different jurisdictions and technologies.
Removing Noise and Redundant Data
After structuring the data, further refinement using top patent tools is necessary to eliminate duplicates and irrelevant content. Patent databases often include the same invention filed in multiple jurisdictions, creating redundancy. MinHash-based fuzzy deduplication is a method that computes n-gram signatures to identify and remove near-duplicates. This step is crucial since patents tend to cluster within legal hierarchies.
For example, in October 2025, Clarivate researchers pretrained ModernBERT-base-PT by applying MinHash deduplication and FineWeb-style quality filters. This process reduced their dataset from 100 million to 64 million unique patents, while also removing figure references and non-English characters.
"Additional deduplication was critical given that patents are often clustered in families or legal hierarchies." - Amirhossein Yousefiramandi, Clarivate
Language identification filters are applied early in the pipeline to ensure consistency, typically focusing on English-language patents for initial models. Heuristic filters weed out documents with excessive repetition or low-quality content.
Other forms of noise, such as figure references ("FIG. 1"), non-English characters in otherwise English documents, and repetitive legal boilerplate, are also removed. Frequency-based pruning eliminates terms that appear too infrequently, reducing vocabulary size without losing meaningful technical language.
This cleaning process can cut a patent dataset by about 33.79%, reducing it from 47.7 billion tokens to 31.6 billion. By removing redundancy while keeping essential technical and legal details, the dataset becomes a solid foundation for building embedding models that capture complex semantic relationships.
Selecting Embedding Models for Patent Data
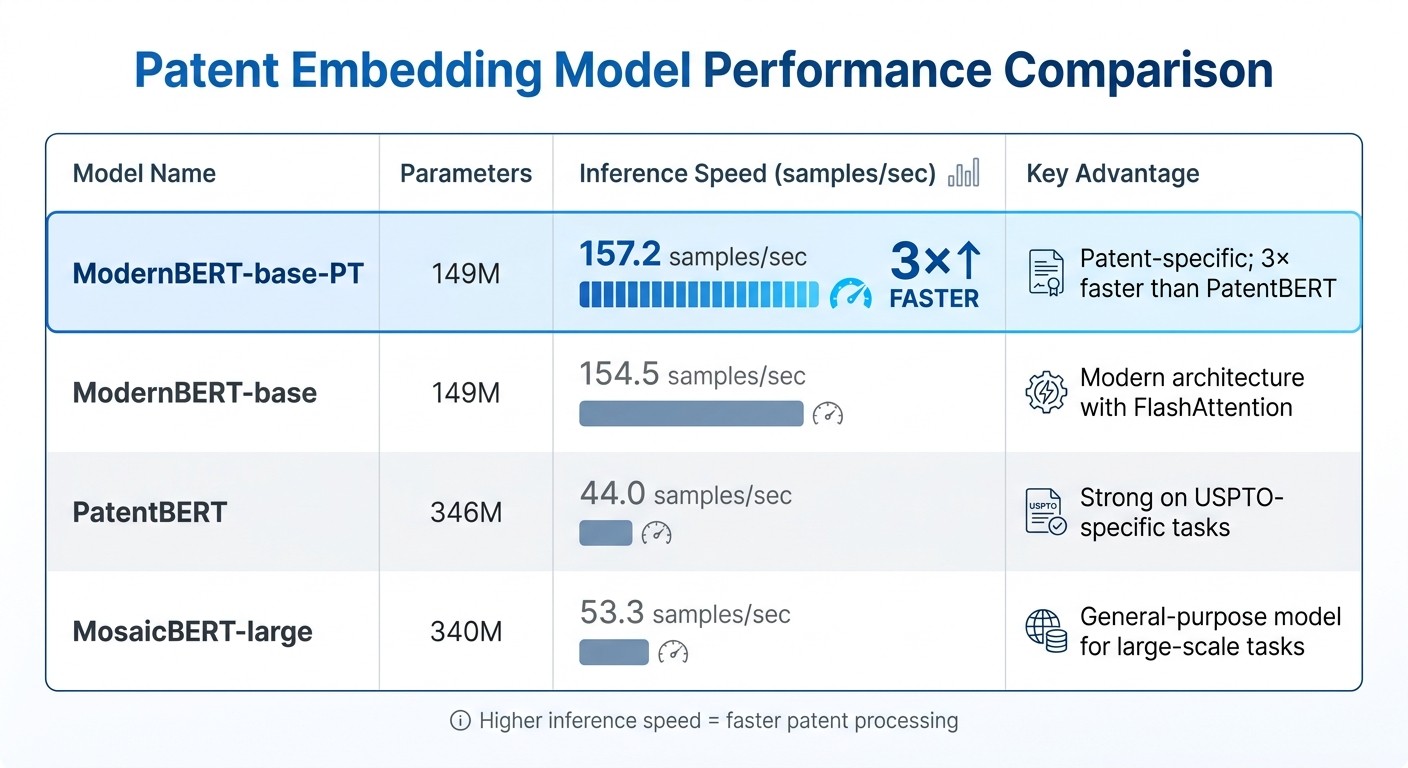
Patent Embedding Model Performance Comparison: Speed and Parameters
Once the patent data is refined, the next step is choosing an embedding model that can handle the intricate mix of technical and legal language found in patents. Pretrained models designed specifically for patents tend to outperform general-purpose ones in accuracy, efficiency, and speed. This is because patent documents demand a model that can interpret specialized terminology, legal phrasing, and lengthy text structures.
Working with Pretrained Patent Models
Models trained on patent-specific datasets consistently deliver better results than general-purpose models. These specialized models are fine-tuned on large patent corpora, allowing them to grasp the unique format and language of patent text. For example, in October 2025, Clarivate introduced ModernBERT-base-PT, a model trained on 64 million unique patents (about 30.8 billion tokens). This model outperformed general-purpose ModernBERT on three out of four classification datasets and was over three times faster in inference than PatentBERT.
"ModernBERT variants retain substantially faster inference - over 3× that of PatentBERT - underscoring their suitability for time-sensitive applications." – Amirhossein Yousefiramandi, Clarivate
For tasks like patent similarity searches, Sentence-BERT (SBERT) architectures are particularly effective. Models such as PatentSBERTa are specifically tuned for comparing patents and excel in subclass-level classification tasks. Another standout is patembed-base, which uses multi-task learning and achieved a V-measure score of 0.494 on the BigPatentClustering.v2 benchmark, surpassing the previous best of 0.445.
When selecting a pretrained model, it's essential to consider the training data. Models trained on USPTO data may perform better with U.S. patents, while those using broader datasets, like the Derwent World Patents Index, tend to generalize more effectively across international patents.
Additionally, exploring a variety of model architectures can further enhance performance.
Comparing Model Architectures
Beyond pretrained models, advanced transformer architectures provide opportunities for optimization. Models like ModernBERT and FlexBERT integrate features such as FlashAttention, rotary positional embeddings (RoPE), and Gated Linear Units (GLU). These features improve both training efficiency and inference speed without compromising accuracy. Such optimizations are particularly beneficial for processing long and complex patent documents.
For extended patent texts, models supporting longer context lengths (up to 8,192 tokens) are invaluable. Approaches like ALiBi (Attention with Linear Biases) positional encoding allow models to handle sequences longer than those in their training data, making them ideal for capturing the full scope of patent descriptions and claims.
In January 2024, researchers from the University of Chicago and Zhejiang University developed an ensemble model for patent phrase matching. By combining DeBERTa-v3-large (weighted at 0.35), ELECTRA-large (0.25), and BERT-for-Patents (0.2), they achieved a cross-validation score of 0.8534. This demonstrates how blending diverse architectures can lead to higher accuracy than using individual models.
Although transformer models typically offer superior precision, large static models like Word2vec remain competitive when trained on massive datasets. These models are less computationally demanding and easier to interpret. However, they struggle with words that have multiple meanings, such as "consideration", which can vary between legal and technical contexts.
Model | Parameters | Inference Speed (samples/sec) | Key Advantage |
|---|---|---|---|
ModernBERT-base-PT | 149M | 157.2 | Patent-specific; 3× faster than PatentBERT |
ModernBERT-base | 149M | 154.5 | Modern architecture with FlashAttention |
PatentBERT | 346M | 44.0 | Strong on USPTO-specific tasks |
MosaicBERT-large | 340M | 53.3 | General-purpose model for large-scale tasks |
The choice of tokenizer also plays a critical role. Byte-Pair Encoding (BPE) tokenizers trained on patent-specific corpora are more effective than standard WordPiece tokenizers, which often break technical terms into less meaningful components. Custom BPE tokenizers have shown sharper declines in Masked Language Modeling loss, leading to improved overall performance.
Training and Optimization Methods
Once you've selected the right embedding model, the next step is fine-tuning the training process to handle the unique complexities of patent language. This involves tweaking hyperparameters, selecting the right loss functions, and implementing strategies to avoid overfitting. Each decision plays a critical role in ensuring the model effectively captures the technical and legal intricacies of patents.
Setting Hyperparameters
To train on large-scale patent datasets, start with a peak learning rate of 3×10⁻⁴, using a linear warmup for the first 6% of steps. Gradually decay the learning rate to about 2% of the peak by the end of training. A global batch size of 4,096 sequences has proven effective when working with a corpus of 64 million patents. Larger batch sizes offer more negative examples during contrastive learning, enabling the model to better differentiate between similar patents.
Additionally, use a 30% masking probability, which is higher than the typical 15%, to better capture complex technical terms. Interestingly, some newer architectures have eliminated dropout without sacrificing generalization, relying instead on stable components like FlashAttention and Gated Linear Units.
Hyperparameter | Recommended Setting | Purpose |
|---|---|---|
Peak Learning Rate | 3×10⁻⁴ | Balances speed of convergence with training stability |
Warmup Period | 6% of total steps | Prevents instability during early training |
Global Batch Size | 4,096 sequences | Provides more negatives for better contrastive learning |
Masking Ratio | 30% | Improves understanding of technical terminology |
Sequence Length | 1,024 to 4,096 | Captures entire patent claims and descriptions |
For parameter updates, StableAdamW is a reliable optimizer during large-scale pretraining.
Selecting Loss Functions
Choosing the right loss function is key to teaching the model how to understand relationships between patents. Multiple Negatives Ranking Loss (MNRL) is a popular choice for fine-tuning patent embeddings. This method treats all other items in a training batch as negative examples, making efficient use of in-batch negatives. To maximize its impact, use the largest batch size your GPU can handle (typically 256–1,024 on an A100) and pair it with a lower learning rate (1e-5 to 5e-5) for contrastive loss.
Another option is Matryoshka Representation Learning (MRL), which trains the model to ensure that the first N dimensions of an embedding are high-quality representations. This allows you to truncate embeddings - for example, from 768 to 128 dimensions - for faster searches without significant quality loss.
Incorporating hard negative mining can also refine the model. Instead of random negatives, use documents from the same International or Cooperative Patent Classification (IPC/CPC) classes. These documents are topically similar but technically distinct, forcing the model to make finer distinctions. An iterative approach - where the model identifies documents it mistakenly deems relevant, and these are added as hard negatives in future training rounds - can further enhance performance.
Another effective strategy is multi-task fine-tuning, where the model is trained on multiple objectives, such as retrieval and classification. This approach acts as a mutual regularizer, as explained by ML Journey:
"Each objective acts as a regulariser for the other - the model can't overfit purely to keyword overlap patterns for retrieval when it also needs to capture class-discriminative features for classification." – ML Journey
These methods not only improve performance but also help address overfitting concerns.
Preventing Overfitting
To avoid overfitting, focus on high-quality data and synthetic augmentation. Expert-curated pairs - sometimes as few as 2,000 - often outperform larger but noisier datasets of 20,000+ pairs. However, models trained on fewer than 500 pairs are prone to overfitting.
Regular evaluation is essential. Assess the model every 200 to 500 training steps, saving the best-performing checkpoint to capture the optimal state before overfitting occurs. When the dataset is too small for stable metrics, use 5-fold cross-validation across the labeled set.
Synthetic data generation can also be a game-changer. Large language models can generate 2–3 plausible search queries per patent passage, creating additional training pairs. This approach makes it possible to build a dataset of 5,000 to 10,000 pairs without requiring extensive manual labeling.
Finally, domain adaptation can boost performance significantly. Pretraining on technical or patent-specific data often leads to a 10–25% improvement in Recall@10. Starting with a model already trained on similar data ensures better results than using a general-purpose model.
Testing and Validating Model Performance
Once the model is trained, the next step is to thoroughly test it to ensure it performs well in real-world patent-related tasks using an AI-enabled patent platform. This phase builds on the training methods discussed earlier and focuses on assessing the model's ability to handle semantic relationships between patents, differentiate closely related technical concepts, and adapt across different technology fields.
Testing Semantic Similarity
A key part of this process is verifying the model's ability to identify patents with similar meanings while avoiding incorrect matches. Historical cases of patent interference - where USPTO examiners identified overlapping claims between applications - offer a strong reference point for testing maximum similarity.
Testing should include both symmetric matching (comparing two full documents) and fragment-to-document matching. Incorporating hard negatives from related IPC classes is vital to help the model make more precise distinctions.
Using Patent Datasets for Testing
To complement similarity tests, use specialized benchmark datasets. For instance, the PatenTEB benchmark (introduced in October 2025) includes 15 tasks such as retrieval, classification, paraphrasing, and clustering. It contains 2.06 million examples, with 319,000 test examples made publicly available.
For phrase-level testing, the Patent Phrase Similarity dataset provides about 50,000 human-rated phrase pairs with detailed ratings, such as synonym, antonym, hypernym, and holonym. Models fine-tuned on patent-specific data typically achieve a Pearson correlation of 0.87–0.88 on this dataset, far exceeding the 0.44–0.60 range for general-purpose models tested without fine-tuning. Additionally, the Harvard USPTO Patent Dataset (HUPD) offers a vast collection of over 4.5 million patent documents, useful for classification and acceptance prediction tasks.
Measuring Embedding Quality
To evaluate how well the model organizes and retrieves information, use metrics like NDCG@100 for retrieval ranking and V-measure for clustering quality. For example, state-of-the-art models such as patembed-large achieved an NDCG@100 score of 0.377 on the DAPFAM dataset, while patembed-base reached a V-measure score of 0.494 on the MTEB BigPatentClustering.v2 benchmark.
Regular evaluation during training - every 200 to 500 steps - can help track progress and identify the optimal checkpoint before performance starts to decline. Comparing the model's output with actual citing and cited patent pairs is another effective way to confirm its ability to align similar patents with real-world citation patterns. This comprehensive testing ensures that the model's training results in reliable and practical patent embeddings for various applications.
Conclusion
Training effective patent embedding models calls for a well-rounded approach that prioritizes data quality, innovative architecture, and thorough evaluation. As Amirhossein Yousefiramandi from Clarivate explains:
"These results underscore the benefits of domain-specific pretraining and architectural improvements for patent-focused NLP tasks".
Models trained on patent-specific datasets consistently outperform general-purpose options in tasks like classification, retrieval, and clustering.
Data Preparation: The Foundation
A strong data preparation strategy is key. Techniques like fuzzy deduplication using MinHash help reduce redundancy and improve overall dataset quality. Pairing this with domain-specific tokenization methods, such as Byte-Pair Encoding, ensures that the model can effectively process complex technical terms without breaking them into meaningless fragments.
Architectural Advancements
Modern architectural updates bring notable improvements in both speed and efficiency. For instance, ModernBERT-based models have been shown to outperform traditional PatentBERT models in processing speed while maintaining accuracy. Features like FlashAttention, rotary embeddings, and Gated Linear Units not only cut down compute costs but also allow the model to handle longer contexts - up to 8,192 tokens.
Optimized Training Techniques
Optimizing training strategies is another critical step. For patent datasets, using a 30% masking probability during pretraining has proven more effective than the standard 15% used in general NLP models. Additionally, multi-task learning enhances the model's versatility across tasks like retrieval, classification, and clustering. Hard negative mining further refines the model's ability to differentiate between closely related technical concepts.
Rigorous Evaluation
Finally, robust evaluation frameworks are indispensable. Benchmarks like PatenTEB, which includes 2.06 million examples across 15 tasks, provide the level of testing required to validate a model's performance in patent-specific contexts. Unlike general NLP benchmarks, these specialized tests ensure the model excels in understanding the unique blend of technical and legal language found in patents.
FAQs
How do I choose the best chunk size for patent text?
When deciding on the ideal chunk size, it's essential to balance the length of your document with the model's token limit (e.g., up to 8,191 tokens). To keep the meaning intact, split the text in logical ways - such as by paragraphs - so the flow of ideas remains clear. Adding overlaps of about 20-50 tokens between chunks can help retain context across sections.
A good starting point is using fixed chunk sizes, like 512-1,000 tokens. From there, you can test and adjust as needed to fine-tune retrieval performance, especially for patent data.
Should I use a patent-specific tokenizer or a standard one?
A tokenizer designed specifically for patents is highly recommended due to the unique and specialized terminology patents often include. This domain-specific approach enhances the quality of embeddings and improves task performance by effectively managing the intricate and complex linguistic structures found in patent texts.
What’s the simplest way to evaluate patent embedding retrieval quality?
The easiest way to assess the quality of patent embedding retrieval is by checking how well the embeddings pull up relevant patents. Popular metrics like NDCG@10 or specialized benchmarks tailored to the field help measure both accuracy and relevance of the results. These tools offer a clear and simple way to evaluate performance and confirm that the embeddings are delivering reliable outcomes.