Comparing Embedding Models for Patent Similarity
Intellectual Property Management
Apr 17, 2026
Compare five embedding approaches for patent similarity—accuracy, speed, and domain adaptation to choose the right model.

Patent similarity analysis is crucial for identifying related patents, understanding innovation trends, and improving search accuracy. Traditional keyword searches often fail to capture the deeper meaning of patent language, which is where embedding models come in. These models convert patent text into numerical vectors, enabling more precise comparisons. Here's a quick breakdown of five popular approaches:
Word2Vec: Efficient and simple, but struggles with context and new terminology.
Doc2Vec: Captures document-level meaning but lacks flexibility with ambiguous terms.
BERT: Context-aware, but computationally heavy and less efficient for large datasets.
SBERT: Optimized for sentence-level tasks, balancing efficiency and accuracy.
PaECTER: Incorporates citation data for enhanced similarity analysis in patents.
Quick Comparison:
Model | Strengths | Weaknesses |
|---|---|---|
Word2Vec | Fast, low-cost, interpretable | Fixed vocabulary, limited context |
Doc2Vec | Document-level focus, scalable | Struggles with ambiguous language |
BERT | Contextual understanding, dynamic | High resource demand, slower |
SBERT | Efficient for large datasets, accurate | Relies on fine-tuning quality |
PaECTER | Uses citation data, precise | Requires domain-specific datasets |
Domain-specific models like Patent SBERT-adapt-ub and PaECTER outperform general-purpose models for patent tasks by addressing the unique challenges of patent language. These models are particularly useful for tasks like semantic search, classification, and clustering.
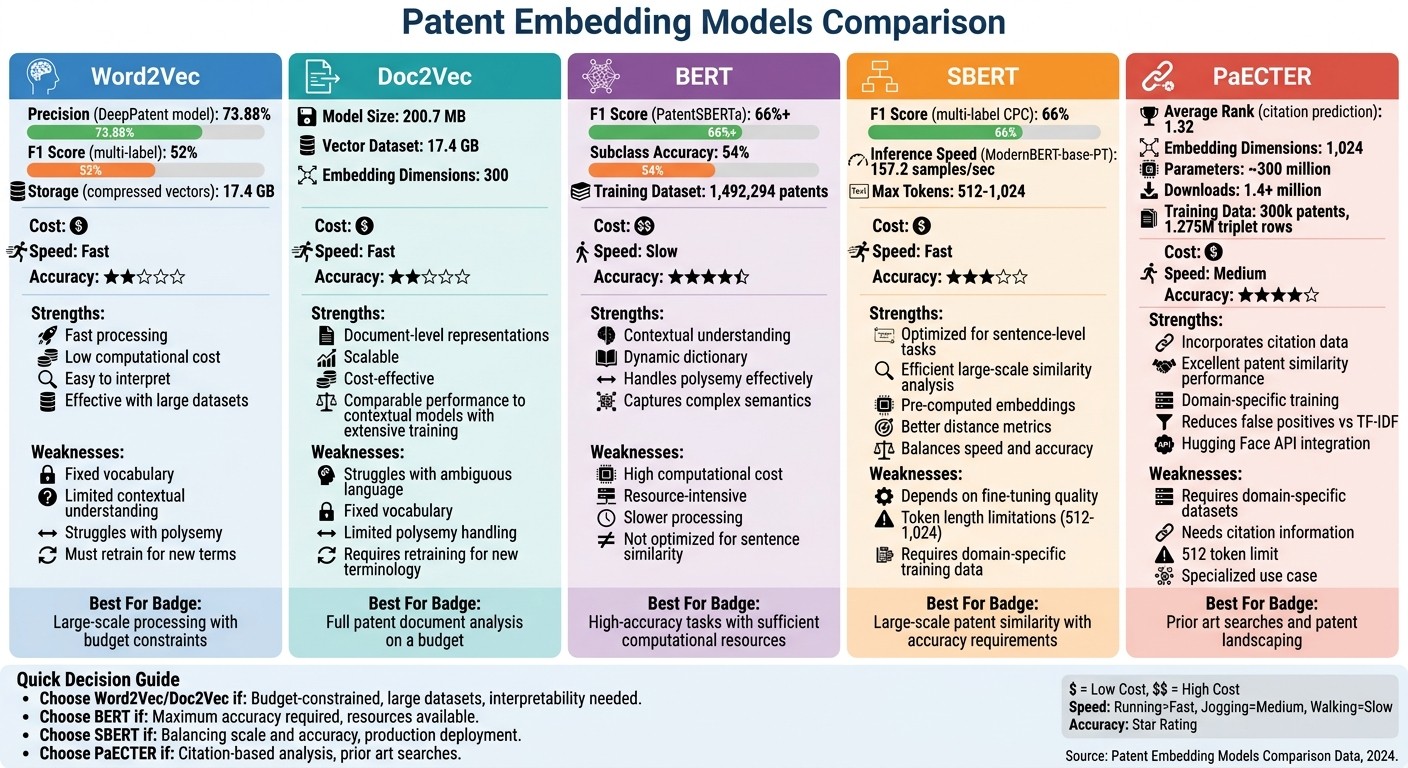
Patent Embedding Models Comparison: Performance Metrics and Trade-offs
OpenAI vs. Open-source Embedding Model Showdown
1. Word2Vec
Word2Vec maps words into a high-dimensional vector space, where the proximity between vectors reflects semantic and syntactic relationships. Unlike contextual models, it generates fixed word representations, which limits its ability to capture the nuanced context often found in patent language. While this simplicity makes it computationally efficient, it also constrains its performance when dealing with the specialized and ever-changing vocabulary of patents.
Cosine Similarity Accuracy
Word2Vec's accuracy in patent similarity tasks depends heavily on the size and quality of the training data. For example, the DeepPatent model, which used a Word2Vec Skip-gram architecture paired with a Convolutional Neural Network and trained on 2 million USPTO patents, achieved a precision of 73.88%. Another study trained Word2Vec on around 48 million EPO patent abstracts (spanning 1980–2017) using a TF-IDF weighted bag-of-words approach, achieving an F1 score of 52% in multi-label classification. These findings highlight that, with large and domain-specific datasets, Word2Vec can still perform competitively compared to more advanced models. Beyond accuracy, its computational efficiency remains a major draw.
Computation Time
Compared to transformer-based models like BERT or SBERT, Word2Vec is far less demanding in terms of computational resources. Its fixed vector representations make it highly scalable for processing large volumes of patent documents. Once embeddings are generated, calculating similarity across vast datasets becomes straightforward, relying on simple vector operations like cosine similarity. For example, US utility patent vectors can require 27 GB of space, with compressed versions reduced to 17.4 GB. While this efficiency is ideal for handling large datasets, it comes at the expense of flexibility in addressing new terminology.
Domain Adaptation
Despite its strengths in accuracy and efficiency, Word2Vec struggles to adapt to the evolving language of patents. Its fixed vocabulary, set during training, means the model must be retrained entirely to account for new terms. Researchers Grazia Sveva Ascione and Valerio Sterzi emphasize this challenge:
This problem [polysemy] is especially significant when looking at patent data, because patent text is characterized by specific technical, legal and often new jargon, where a single technology might be associated to a variety of uses and a single use to a variety of technologies.
That said, Word2Vec offers advantages such as lower training costs and greater interpretability compared to transformer-based models.
2. Doc2Vec
Doc2Vec builds on the foundation laid by Word2Vec, moving beyond word-level context to capture document-level meaning. This makes it particularly useful for creating richer representations of patents. Unlike Word2Vec, which focuses on words, Doc2Vec represents entire documents as fixed-length vectors. It retains the efficiency of Word2Vec while extending its capabilities, making similarity calculations between patents more effective.
Cosine Similarity Accuracy
In 2020, Whalen et al. trained a Doc2Vec model using the Distributed Bag of Words (DBOW) algorithm on USPTO utility patent data spanning 1976 to 2019. This process involved 10 training epochs to produce 300-dimensional embeddings for both patent descriptions and independent claims. In research, Doc2Vec often acts as a baseline for comparison against more advanced contextual models like BERT and SBERT. To evaluate its accuracy, researchers frequently use cases of patent interferences - instances where claims overlap - as a ground-truth indicator of high similarity. The next step is to consider how it performs computationally compared to transformer-based models.
Computation Time
Doc2Vec is significantly more efficient in terms of computational resources compared to transformer-based approaches. For example, the trained Doc2Vec model for U.S. patent data is approximately 200.7 MB, while the vectors for the entire utility patent dataset take up 17.4 GB. This efficiency makes it feasible to process millions of patent pairs and generate "most-similar" patent lists. As Grazia Sveva Ascione and Valerio Sterzi observed:
large static models performances are still comparable to contextual ones when trained on extensive data; thus, we believe that the superiority in the performance of contextual embeddings may not be related to the actual architecture but rather to the way the training phase is performed.
However, this computational efficiency comes at the cost of flexibility and adaptability.
Domain Adaptation
Doc2Vec offers an advantage over Word2Vec by capturing the semantics of entire documents, but it still faces limitations in adapting to new domains. Like Word2Vec, it struggles with polysemy - situations where a single word has multiple meanings depending on context. This issue is particularly pronounced in patent texts, which are often dense with technical and legal terminology. Another challenge is its reliance on a fixed vocabulary established during training. Introducing new terminology requires retraining the entire model.
Despite these drawbacks, Doc2Vec remains cost-effective and interpretable. A 2022 case study by Jeon, Ahn, Kim, and Lee applied Doc2Vec alongside a Local Outlier Factor method to analyze 1,877 medical imaging technology patents. The study found that patents identified as novel often had a higher technological impact. However, its static nature continues to limit its adaptability to evolving datasets and vocabularies.
3. BERT
BERT (Bidirectional Encoder Representations from Transformers) stands out by creating word embeddings that shift based on the surrounding text. This means the same word can take on different vector representations depending on its context. For patent analysis, this is a game-changer since technical terms often have varying meanings across different technological fields. This contextual flexibility makes BERT particularly useful, especially when assessing its performance in accuracy, speed, and adaptability to specific domains.
Cosine Similarity Accuracy
When it comes to cosine similarity, BERT demonstrates an ability to capture the subtle meanings embedded in patent language. Domain-specific models like Bert-for-patents consistently rank high in patent similarity tasks due to specialized fine-tuning. For instance, PatentSBERTa - a model fine-tuned on patent data - achieves impressive results, with F1 scores exceeding 66% and subclass accuracy reaching 54%. These results are validated using CPC (Cooperative Patent Classification) class overlaps.
In October 2021, researchers Hamid Bekamiri, Daniel S. Hain, and Roman Jurowetzki from Aalborg University introduced PatentSBERTa. This hybrid model combines an augmented SBERT (Sentence-BERT) architecture with fine-tuning on patent claims. It uses a K-Nearest Neighbors (KNN) framework to predict multiple CPC classes across a dataset of 1,492,294 patents.
Computation Time
Processing large patent datasets with traditional BERT models can be computationally demanding. While BERT excels in capturing complex semantic relationships, calculating similarities across millions of patents is resource-intensive using its standard architecture. SBERT, however, addresses this issue by enabling pre-computation of embeddings, significantly speeding up similarity calculations. Although BERT-based models require more computational power compared to static models, the improved performance often outweighs the additional costs.
Domain Adaptation
BERT's ability to adapt to specific domains is where it truly shines in patent analysis. By fine-tuning on patent-specific data, BERT overcomes the limitations of static models, which often fail to keep up with constantly changing terminology. General-purpose BERT models, which aren't trained on dense technical and legal language, tend to underperform in patent-related tasks. Targeted models like Patent SBERT-adapt-ub show how training on patent corpora can lead to significant improvements. However, challenges remain, as performance can vary across different patent classes and sections. This variability means researchers must carefully fine-tune models for their specific datasets.
Another hurdle in domain adaptation is the lack of curated Semantic Textual Similarity (STS) benchmark datasets created by domain experts. This makes validating models more complex and highlights the need for improved resources in this area.
4. SBERT (Sentence-BERT)
SBERT tackles one of BERT's major challenges: computational inefficiency. Traditional BERT requires comparing every possible patent pair using a cross-encoder, which becomes overwhelming with large datasets. SBERT, on the other hand, generates fixed-size sentence embeddings that can be compared directly using cosine similarity. This shift in architecture allows SBERT to scale efficiently by precomputing embeddings, making it ideal for analyzing patent-to-patent similarity across extensive datasets.
Cosine Similarity Accuracy
When fine-tuned on patent-specific data, SBERT consistently delivers better results than general-purpose models. For example, Patent SBERT-adapt-ub has demonstrated exceptional performance in evaluating 133 "patent interferences".
"Patent SBERT-adapt-ub, the domain adaptation of the pretrained Sentence Transformer architecture proposed in this research, outperforms the current state-of-the-art in patent similarity." - Grazia Sveva Ascione and Valerio Sterzi, Bordeaux School of Economics
Unlike static embedding models that rely on fixed vocabularies, SBERT adapts to evolving terminology and the specialized language often used by patent attorneys to define intricate concepts. This adaptability not only improves accuracy but also enhances processing speed.
Computation Time
SBERT strikes a balance between precision and efficiency. While static models like Word2Vec are less expensive to train, SBERT optimizes similarity calculations by generating sentence embeddings just once. These embeddings can then be compared using cosine similarity, eliminating the need for repeated full BERT inference for every patent pair.
For instance, in 2024, ModernBERT-base-PT - a domain-adapted encoder trained on 64 million patents - achieved an inference throughput of 157.2 samples per second, significantly outperforming PatentBERT's 44.0 samples per second. This speed makes SBERT a practical choice for domain-specific fine-tuning.
Domain Adaptation
Domain adaptation customizes SBERT for patent analysis. The most effective method involves fine-tuning the model on triplets of patents: an anchor patent, a positive example (sharing the same Cooperative Patent Classification or CPC code), and a negative example (from a different CPC code).
Advanced techniques like TSDAE (Sequential Denoising Auto-Encoder) and GPL (Generative Pseudo-Labeling) can further enhance performance by 8 to 10 percentage points. However, working with patents presents unique challenges. For instance, patent descriptions often exceed 11,000 tokens - far beyond the 512 or 1,024 token limits of most transformer models. Additionally, the lack of robust benchmark datasets makes validation more challenging compared to other fields.
5. PaECTER

PaECTER (Patent Embeddings using Citation-informed TransformERs) takes a specialized approach to patent similarity by incorporating citation data for added depth. This document-level encoder, fine-tuned from BERT for Patents, uses examiner-added citation information to understand the legal and technical connections identified by patent examiners. This unique training makes it especially useful for tasks like prior art searches and patent landscaping.
Cosine Similarity Accuracy
PaECTER creates 1,024-dimensional dense embeddings, and its performance in citation prediction tests is impressive. It achieved an average rank of 1.32 when tasked with identifying the most similar patent among 25 distractors. This result outpaces BERT for Patents and general-purpose models like E5, GTE, and BGE. These metrics highlight its reliability for patent similarity tasks.
Computation Time
With around 300 million parameters, PaECTER balances accuracy with practical usability. It supports a maximum sequence length of 512 tokens and integrates seamlessly with the sentence-transformers library. Additionally, it’s available through Hugging Face's Inference API, enabling large-scale deployment without heavy local infrastructure. By October 2024, the model had been downloaded over 1.4 million times, showcasing its growing popularity.
"We are pleased that PaECTER's performance has been validated by the NBER study, which shows its strengths in patent similarity analysis and confirms its role as a reliable tool for those working in the field of innovation and intellectual property."
Mainak Ghosh, Developer of PaECTER
Domain Adaptation
PaECTER's adaptability stems from its training methodology. It was trained on 300,000 EPO/PCT patents and 1.275 million rows of triplet data, which included focal, positive, and negative citations. This citation-based training goes beyond traditional text pre-training by capturing the semantic relationships identified by examiners. A National Bureau of Economic Research study also highlighted PaECTER's ability to reduce false positives compared to older models like TF-IDF, all while improving overall efficiency.
Pros and Cons
Different models bring their own sets of strengths and weaknesses when it comes to patent similarity tasks. Static models like Word2Vec and Doc2Vec stand out for their low training costs and ease of interpretation. But these models rely on fixed dictionaries, which makes them less effective in dealing with the polysemy often found in patent language - where technical terms can carry multiple meanings depending on the context.
On the other hand, BERT creates contextualized representations that excel at managing ambiguous terminology and capturing intricate semantic relationships. The downside? It’s computationally demanding and not inherently designed for sentence-level similarity tasks. SBERT addresses this by adapting BERT for sentence-level tasks, achieving an F1 score of 66% in multi-label CPC classification - far surpassing Word2Vec's 52%. These performance differences highlight the balance between computational efficiency and adaptability to domain-specific nuances in patent similarity.
The table below provides a concise comparison of the pros and cons for each embedding model:
Model Name | Pros | Cons |
|---|---|---|
Word2Vec | Low training cost; easy to interpret; identifies syntactic patterns; effective with large datasets. | Relies on a fixed dictionary; struggles with polysemy. |
Doc2Vec | Produces document-level representations; suitable for analyzing full patent texts. | Limited context sensitivity; ineffective with ambiguous technical jargon. |
BERT | Contextualized outputs; handles polysemy; dynamic dictionary; captures complex semantics. | High computational cost; less suited for direct sentence-level similarity without modifications. |
SBERT | Tailored for sentence-level tasks; efficient for large-scale similarity analysis; delivers better distance metrics. | Heavily reliant on the quality of training and fine-tuning. |
Patent-Specific (PaECTER / PatentSBERTa) | Excels in patent similarity; understands domain-specific jargon; achieves high CPC classification accuracy. | Needs well-labeled domain-specific data for effective training. |
This breakdown highlights the trade-offs between simplicity, computational demand, and domain-specific performance for each model.
Conclusion
From our analysis, some clear insights emerge for improving patent similarity analysis. Domain-adapted models consistently outperform generic embeddings when applied to patent-specific tasks. Among these, the patembed model family and Patent SBERT-adapt-ub stand out as top performers, thanks to their ability to interpret technical jargon and navigate legal ambiguities effectively. For instance, in October 2025, researchers Iliass Ayaou and Denis Cavallucci introduced the patembed-base model, which achieved a 0.494 V-measure on the MTEB BigPatentClustering.v2 benchmark - breaking the previous record of 0.445. This success stemmed from multi-task training on a massive dataset of 2.06 million examples across 15 tasks, including both retrieval and clustering.
As highlighted earlier, Patent SBERT-adapt-ub excels in capturing the intricate nuances of patents, far surpassing generic models like BERT or RoBERTa. The key takeaway here? Choose domain-adapted models when precision is critical. These specialized tools are far better equipped to interpret the unique context and language of patent claims.
Additionally, semantic search tools powered by these advanced embeddings offer a major upgrade over traditional keyword-based systems. For example, Patently's Vector AI platform demonstrates how transformer-based models can go beyond exact text matches. It links related ideas - like "autonomous vehicle" and "self-driving car" - without requiring manual synonym lists. The platform also supports natural language queries, eliminating the need for complex Boolean strings. Features like cross-linguistic matching and claim-level relevance scoring further streamline the process, enabling patent professionals to identify overlapping technical features in seconds rather than hours.
The adoption of multi-task learning and instruction tuning is driving the evolution of patent embeddings. Models like patembed-large, which can process up to 4,096 tokens, are particularly suited for handling longer patent sections while maintaining high accuracy in tasks such as retrieval, classification, and clustering. By integrating these domain-specific models, crafting natural language queries, and leveraging advanced patent search platforms, professionals can achieve higher accuracy and efficiency in their patent analysis workflows.
FAQs
Which embedding model is best for large-scale patent similarity search?
The Patent SBERT-adapt-ub, a domain-specific version of the pretrained Sentence Transformer, stands out as the top model for large-scale patent similarity searches. It surpasses other advanced models, especially in tasks like detecting patent interference cases. While large static models can deliver decent results in certain contexts, the specialized SBERT-based model provides greater accuracy, making it the go-to option for these applications.
How much does domain-specific fine-tuning improve patent similarity results?
Fine-tuning models specifically for patent data can lead to much better results when assessing patent similarity. Models like Patent SBERT-adapt, which are trained on patent-specific language, excel because they understand the technical and specialized terminology unique to patents.
In fact, research indicates that these fine-tuned models can boost accuracy by around 17% compared to general-purpose models. This improvement makes them a powerful tool for delivering precise and reliable similarity assessments in the patent space.
What patent text should I embed (claims, abstract, or description)?
When deciding what text to embed - claims, abstract, or description - it all comes down to your goals and the level of precision required. Claims are typically a go-to for similarity tasks because they focus on the key inventive elements and are central to how examiners evaluate overlaps. That said, embedding the abstract or description can also work well, especially when using advanced tools like Patent SBERT. The best option will depend on your particular use case and the strengths of your chosen model.