How Deep Neural Networks Analyze Patent Claims
Intellectual Property Management
Jun 19, 2026
DNNs turn structured patent claims into actionable, explainable legal insights through claim-aware preprocessing and task-specific workflows.

Patent-claim AI works best when it treats claims as legal text, not just text data. From start to finish, the process comes down to four jobs: clean the claim without losing legal meaning, encode the language in context, tie the model to one clear patent task, and check the output before anyone relies on it.
Here’s the short version in plain English:
I start by cleaning and structuring claims so numbering, dependencies, and terms like comprising and wherein stay intact.
I then use a patent-tuned neural model to read claim language in context, not as isolated keywords.
I match the model to one job at a time, such as:
I check results against legal ground truth, such as examiner-cited references or manually tagged limitations.
I review outputs with explainability tools because legal teams need to know why a claim was flagged.
I retrain the system when patent language shifts over time.
A few facts stand out:
In one cited example, a neural model matched Google’s PageRank patent to the same main prior-art reference later used by the USPTO examiner.
In a study of 14,000 U.S. patent claims, 73% of indefiniteness reasons involved missing or unclear antecedent basis and unclear definitions.
For classification work, common checks include F1-score and accuracy.
Bottom line: I would not judge this kind of system by model scores alone. I would judge it by whether it keeps legal terms intact, maps to the right patent task, and gives attorneys output they can inspect line by line.
That’s the core idea the article develops in more detail.
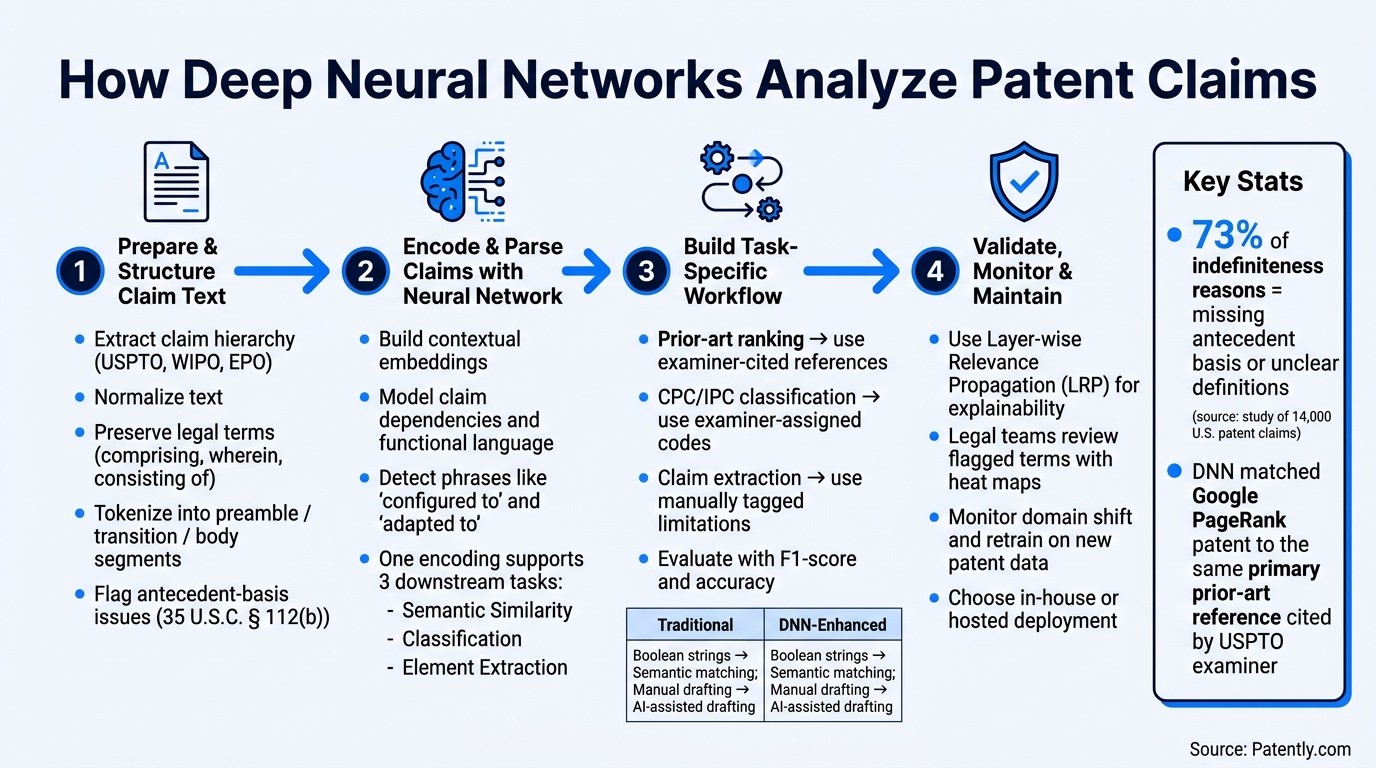
How Deep Neural Networks Analyze Patent Claims: 4-Step Workflow
Step 1: Prepare and Structure Claim Text for Model Input
Preprocessing turns raw claims into model-ready text without stripping out legal meaning. Before a deep neural network can work with a claim, the text has to be collected, cleaned up, and put into a consistent format.
Extract Claim Hierarchy and Normalize Text
Claims from USPTO, WIPO, and EPO records often show up in messy formats. You might see single-line text, Jepson claim structures, or other layout quirks. The first job is to normalize the text while keeping claim numbering and dependency links intact.
That means preserving claim transitions and qualifiers such as comprising, consisting of, wherein, and substantially. Those terms do a lot of legal work, so you can't smooth them over just to make the text easier to read. Preprocessing should also flag antecedent-basis issues under 35 U.S.C. § 112(b).
Tokenize and Segment Claims into Usable Parts
Once the hierarchy is cleaned up, the next step is tokenization. Split claims into words or subwords so the model keeps technical terms while dropping formatting noise.
Then segment each claim into its main parts:
preamble
transition
body
This split helps separate broad scope from specific limitations. It also sets up later dependency parsing and functional-language detection under 35 U.S.C. § 112(f).
Use Patent-Specific Language Models Where Possible
Patent-trained or patent-adapted BERT-style models tend to fit claim language better because they learn technical terms and legal markers in context. The same preprocessing rules also help with semantic search. Patently's Vector AI uses claim-focused semantic matching to surface conceptually similar claims even when the wording changes.
That structured input gives the network the context it needs to parse dependencies and limitations in the next step.
With claims normalized and segmented, the model can encode structure and meaning in Step 2.
Step 2: How Deep Neural Networks Encode and Parse Patent Claims
After tokenization, the model builds contextual embeddings that keep claim meaning, structure, and claim modifiers intact. Once the claims are encoded, the model can separate structure from meaning and send the results into task-specific analysis.
Build Contextual Representations of Claim Language
The model reads each token in context, so meaning stays intact even across long claim text.
Model Claim Structure, Dependencies, and Functional Language
Next, the model detects structure, dependencies, antecedent basis, and functional language in independent and dependent claims. It can also flag phrases such as "configured to" and "adapted to" for careful review.
Apply Task-Specific Parsing for Search, Classification, and Extraction
For patent professionals, one encoding can support search, classification, and extraction. The same encoded representation supports three downstream tasks:
Task | What the Model Does | Practical Output |
|---|---|---|
Semantic similarity for prior art | Compares encoded claim elements against known art | Ranked list of similar claims |
Classification | Maps the representation to a technology label | Automated class assignment |
Element extraction | Identifies technical components and legal phrases | Structured claim element list |
In a June 2020 JDB IP demo, sentence encoders on Google's PageRank patent ranked Ishikawa et al. as the top reference, matching the examiner's primary citation. The model surfaced functional text in the reference, showing how DNNs can support prior-art analysis.
These outputs feed the workflow design in Step 3.
Step 3: Build a Claim Analysis Workflow for Patent Professionals
Turn encoded claim outputs into a workflow that matches the job at hand: prior-art search, CPC tagging, or claim-element extraction. The first step is simple but easy to get wrong. Pair each task with one label set and one evaluation target.
Define the Objective and Label the Right Signals
Use the label source that matches the legal task.
For prior-art ranking, use examiner-cited references.
For classification, use examiner-assigned CPC/IPC codes.
For extraction, use manually tagged claim limitations.
CPC classification sorts patents into specific technology groups and usually relies on existing examiner-assigned CPC or IPC codes as labels, often at the 4-digit level. Claim element extraction breaks claims into elements and subelements, using manually tagged claim limitations or structured ground-truth claim charts.
This is where many patent AI projects go off track. If the ground truth doesn't match legal meaning, the model will learn the wrong thing. And once that happens, even decent model performance can be misleading.
Train, Fine-Tune, and Evaluate the Model
Model choice matters, especially with long claims. Older CNNs and RNN/LSTMs tend to struggle with long-range dependencies in claim language. Transformer-based models handle those dependencies better.
For evaluation, use historical prosecution data when you can. It gives you a better picture of how the model performs in the kind of work patent teams deal with every day. For classification tasks such as IPC/CPC tagging, F1-score and accuracy are useful checks.
Connect Outputs to Search, Drafting, and SEP Workflows
After the model passes validation, plug each output into the patent task it supports.
Workflow Stage | Traditional Workflow | DNN-Enhanced Workflow |
|---|---|---|
Prior art search | Boolean strings and manual synonym lists | Semantic query matching by concept and function |
Claim drafting | Manual drafting and review | generative AI patent drafting tools and consistency checks |
SEP review | Keyword mapping to standard documents | Embedding-based claim-to-standard alignment for 4G/5G |
Once the workflow is live, don't just let it run on autopilot. Review failure cases, legal edge cases, and drift before production use. After validation, monitor errors on new prosecution data and retrain when claim language shifts.
Step 4: Validate Results, Manage Risk, and Maintain the System
Once model outputs start driving search, drafting, or SEP analysis, you need to check that the results stay explainable and steady on new patent data. A model that looks good in testing can drift once it meets newer claims, different drafting habits, or shifts in legal standards.
Interpret Model Outputs for Legal Review
Attorneys need to know why a claim was flagged, not just that it was flagged.
Layer-wise Relevance Propagation (LRP) can point to the claim terms behind a classification and show which terms drove the result. In practice, that heat map gives reviewers something concrete to inspect. They can line up the flagged text with the examiner’s stated reason and see whether the model’s logic tracks with the legal issue at hand.
"Knowing that a claim is indefinite does not provide actionable information. Rather, understanding why it is indefinite is crucial." - Valentin Knappich, Bosch Center for AI
That point carries weight. In a study of 14,000 U.S. patent claims, missing or ambiguous antecedent bases and unclear definitions made up 73% of all indefiniteness reasons.
So the explanation layer isn’t just a nice extra. It helps legal teams review outputs in a way that makes sense, term by term, instead of treating the model like a black box.
These explanations help with review, but they also need to be watched over time as patent language changes.
Monitor Domain Shift and Retrain on New Patent Data
Retrain on recent patent data so the model reflects shifts in drafting patterns and legal standards.
Patent language doesn’t sit still. New filing habits show up, examiner phrasing changes, and claim style can drift over time. If the training data gets stale, performance can slip in quiet ways. That’s why retraining on newer patent data matters.
Choose Between In-House Deployment and a Hosted Platform
The final choice is operational: where the model runs and who maintains it.
In-house deployment gives maximum control over unpublished applications. That can matter a lot when confidentiality is non-negotiable.
Using top patent tools like Patently cuts maintenance work while supporting semantic search, drafting, project management, and SEP analytics. So the tradeoff is pretty simple: more control on one side, less upkeep on the other.
Conclusion: From Raw Claims to Actionable Analysis
This workflow takes claim text from raw parsing all the way to attorney-ready output. Deep neural networks can turn dense patent claims into usable analysis, but only when preprocessing, encoding, and validation are built for patent language.
That point hits hardest when you can check the model against actual patent references. In June 2020, a deep neural network matched Google's PageRank patent to Ishikawa, the same primary reference later cited by the USPTO Examiner. It also surfaced supporting passages inside the reference. That is limitation-level validation - the kind that gives attorneys something concrete to verify instead of a score they have to accept on faith.
The lesson is simple: output quality depends on the system around the model. Deep neural networks do their best work when the surrounding workflow is built for patent tasks. Patent-specific preprocessing, domain-aware evaluation, and regular retraining are the controls that make the system dependable in production. Patently centralizes semantic search, drafting, and SEP analytics for teams that want a hosted workflow.
FAQs
Why can’t patent claims be processed like ordinary text?
Patent claims aren't ordinary text. They're tightly structured legal tools with a clear hierarchy: a preamble, a transition phrase, and a body of limitations.
That structure matters a lot. In an independent claim, every limitation has to be present for infringement or anticipation. Miss just one element, and the legal outcome can change.
This is where general-purpose NLP models often stumble. They may miss claim boundaries, lose track of antecedent basis chains, or blur the line between functional language and claim elements that must be there.
Which patent tasks benefit most from deep neural networks?
Deep neural networks help patent teams handle hard, time-heavy work by using semantic analysis and pattern recognition.
Here’s where they help most:
Prior art searches: find references that match the idea behind an invention, not just the exact keywords
Claim drafting: help generate claim language and check support in the specification
Infringement and FTO analysis: break down claim limitations and map them to product features to gauge risk
That matters because patent work often turns into a needle-in-a-haystack problem. A keyword search might miss a document that uses different wording but describes the same core concept. Deep neural networks can help close that gap by looking at meaning, not just terms on the page.
The same logic applies to claims. During drafting, these systems can help spot whether a claim element has basis and whether the language lines up with the underlying disclosure. For infringement and FTO work, they can parse claims into smaller parts, then compare those parts against product features in a more structured way.
How do attorneys verify that a model’s output is reliable?
Attorneys verify AI-generated output through steady human review during both analysis and drafting. They do the final check to make sure each claim is backed by the specification, meets legal standards, and fits the company’s business strategy.
They also review consistency, confirm terminology, and manually tighten drafts for precision and accuracy. Platforms like Patently can help with this process through team features like shared comments and ratings.