Emerging Tech Forecasting with Patent Data
Intellectual Property Management
Apr 9, 2026
Patent filings analyzed with AI provide early, actionable signals of emerging technologies when data is cleaned, clustered, and modeled.
Patent data is a goldmine for predicting future technologies. By analyzing patent filings, companies can identify untapped opportunities, track competitor advancements, and allocate R&D resources more effectively. Here's what you need to know:
Patents reveal early innovation: Filings often precede product launches by years, offering insights into emerging trends before they hit the market.
AI enhances analysis: Tools like NLP and machine learning process complex patent data, identify trends, and highlight areas with minimal competition.
Key metrics for forecasting: Metrics like Technology Improvement Rate (TIR), patent velocity, and forward citations help evaluate innovation speed and market potential.
Applications in AI, quantum computing, and biotech: Patent trends show rapid growth in AI ethics, quantum error correction, and CRISPR-based therapies.
Preparing Patent Data for Analysis
Collecting Patent Datasets
The backbone of any reliable technology forecast is high-quality patent data, often sourced using the top patent tools for IP professionals. Your forecasting model is only as good as the data it’s built on. For U.S. patent analysis, the USPTO Open Data Portal (ODP) at data.uspto.gov offers bulk downloads, an API, and a query builder to access patent records.
A standout resource is PatentsView, a USPTO initiative that applies AI and machine learning to make raw patent records more accessible and research-ready. According to the USPTO:
PatentsView is a USPTO database that applies artificial intelligence algorithms to enhance U.S. patent data, converting complex raw records into accessible, research-grade datasets for dissemination, visualization, and analysis.
PatentsView provides access to over 40 years of longitudinal patent data and is transitioning to the Open Data Portal for long-term availability. For accurate forecasting, prioritize the "disambiguated" datasets from PatentsView, which resolve inconsistencies in inventor and applicant names found in raw XML data. For example, the Artificial Intelligence Patent Dataset (AIPD 2023) identifies AI-related inventions within 15.4 million U.S. patents published between 1976 and 2023. To track emerging technologies, include Pre-Grant Publication (PGPub) datasets, which highlight trends before patents are officially granted.
Cleaning and Standardizing Data
Raw patent data can be messy, and early cleaning is essential to avoid errors later. Begin with tokenization (breaking text into smaller units) and case normalization (converting text to lowercase). This ensures terms like "Drone", "drone", and "DRONE" are treated as the same entity. Removing stop words (common, non-technical terms like "and" or "the") also helps. For instance, removing stop words reduced a U.S. patent title dataset from 60.8 million rows to 44 million.
Using lemmatization - which converts words into their base forms (e.g., "methods" and "method" both become "method") - is more precise than stemming. This technique is crucial for accurate aggregation and network visualization. Additionally, patent family grouping consolidates filings of the same invention across different jurisdictions into a single "family", which avoids overcounting and false signals of market saturation. Similarly, kind code collapsing ensures that different document stages (e.g., U.S. A1 for applications and B2 for grants) are recognized as part of the same patent. Adjustments are also necessary for pre-2001 USPTO data, where kind codes were either absent or inconsistently applied.
Alias matching is another key step. This process links variations of company names (e.g., "Apple Inc." vs. "Apple Computer") and inventor names to create a complete picture of ownership and collaboration. As PowerPatent warns:
Your automation is only as smart as your data. If duplicates are flooding your system, your alerts will be off, your analytics will misfire, and your dashboards will mislead.
When working with dates, the priority date should take precedence over the publication date. As Paul Oldham, author of the WIPO Open Source Patent Analytics Manual, explains:
The priority date is important... in economic analysis the priority date is the date that is closest to the investment in research and development and therefore the most important.
Once the data is cleaned and standardized, structuring it thoughtfully ensures it’s ready for analysis.
Structuring Data for Analysis
With cleaned data in hand, organizing it properly is key to identifying technology trends. Follow a "tidy data" approach, where each variable is a column and each observation is a row. This method keeps unique document identifiers (like patent_id) intact throughout processing, making it easier to link text data with metadata such as dates and classifications. Since patent data from different jurisdictions (USPTO, EPO, WIPO) comes in varying XML formats, an ETL (Extract, Transform, Load) process is essential to unify these into a single data model that includes dates, assignees, classifications, and relationships.
Integrating classification codes with text data - using International Patent Classification (IPC) or Cooperative Patent Classification (CPC) codes - helps focus text mining efforts. This reduces irrelevant data, like distinguishing "pipeline pigs" in engineering from "pigs" in biology. Applying Term Frequency-Inverse Document Frequency (TF-IDF) highlights unique terms within specific technology subclasses, which sharpens predictive models. Be mindful of kind codes (e.g., A1 for applications, B1 for grants) to differentiate between requests for protection and granted rights.
Data Category | Key Fields for Structuring | Purpose in Forecasting |
|---|---|---|
Bibliographic | Title, Abstract, IPC/CPC Codes | Identifying technology domains and core concepts |
Temporal | Priority Date, Publication Date | Establishing timelines for R&D investment vs. market entry |
Relational | Citations (Forward/Backward), Families | Mapping technology influence and competitive impact |
Legal Status | Grant, Lapse, Expiration | Determining the current "freedom to operate" and technology maturity |
Blockchain Patent Trends Nobody is Talking About
AI Methods for Patent Data Analysis
AI transforms structured patent data into actionable insights. By leveraging natural language processing (NLP), machine learning, and predictive analytics, organizations can uncover rising technologies, track competitor investments, and identify emerging innovation clusters.
Natural Language Processing (NLP)
NLP turns unstructured patent text into searchable and meaningful data. Techniques like topic modeling (e.g., Latent Dirichlet Allocation or LDA) extract themes from large patent collections. This helps cluster related inventions and uncover trends that simple keyword searches might miss. For instance, instead of manually reviewing thousands of patents on AI accelerators, LDA can automatically group patents around themes like neural network architectures or GPU designs.
Named Entity Recognition (NER) is another NLP tool that identifies key elements in patent text, such as company names, inventors, and technical terms. This makes it easier to track how specific players navigate various technology domains. Meanwhile, semantic search goes beyond matching keywords to understand the context and meaning behind text, enabling more accurate searches for prior art even when different terminology is used. Domain-specific NLP models, like Patent‐BERT or ChemBERT, achieve high accuracy (85–92%) for specialized tasks such as drug-entity recognition.
NLP also supports novelty detection, which measures how unique a patent is compared to existing prior art. This helps differentiate between incremental improvements and groundbreaking innovations that could signal major technology shifts. These NLP capabilities, when combined with machine learning, provide deeper insights into patent trends.
Machine Learning Models
Machine learning uncovers patterns in patent data that might otherwise go unnoticed. Supervised learning models are commonly used to classify patents into predefined technology categories or predict the likelihood of a patent being granted based on prior art analysis. These models rely on labeled datasets, making them effective for categorization tasks.
In contrast, unsupervised learning models group patents without relying on predefined labels. This approach reveals hidden innovation clusters and identifies "white spaces" where patent activity is minimal. For example, during the mid-2010s, NVIDIA's surge in patent filings related to GPU architectures and AI accelerators provided early signals of their data center revenue growth, which materialized two to three years later. Analysis of citation-weighted patent growth across jurisdictions like the U.S., EU, and China played a crucial role in this forecast.
Advanced techniques like deep learning and computer vision expand the scope of analysis. Deep learning can identify intricate patterns within massive datasets, while computer vision models analyze patent figures and technical drawings, offering a more complete view of innovation beyond text. Additionally, knowledge graphs map relationships between patents, technologies, and inventors, helping to visualize competitive landscapes and track how ideas flow across organizations.
Predictive Analytics
Predictive analytics transforms patent data into a tool for anticipating future developments. These models analyze filing trends, citation networks, and litigation histories to forecast patent activity and estimate valuations. In biotechnology, for instance, unsupervised clustering has been used to identify "low-competition chemical space", pinpointing new R&D opportunities.
Machine learning classifiers can also evaluate the likelihood of a patent being granted by analyzing application quality and the density of prior art. More sophisticated models predict "Loss of Exclusivity" (LOE) dates by assessing the probability of litigation challenges and the outcomes of generic competitors. A notable example is Pfizer's $43 billion acquisition of Seagen in December 2023, where Seagen's Antibody-Drug Conjugate (ADC) patent portfolio - covering linkers, payloads, and conjugation sites - was a key valuation factor.
Predictive tools also spot emerging trends by tracking rapid changes in filing momentum and assignee concentration within specific technology clusters. As PowerPatent highlights:
Predictive models can provide insights into future trends, patent value, and potential legal issues
Building Technology Forecasting Models
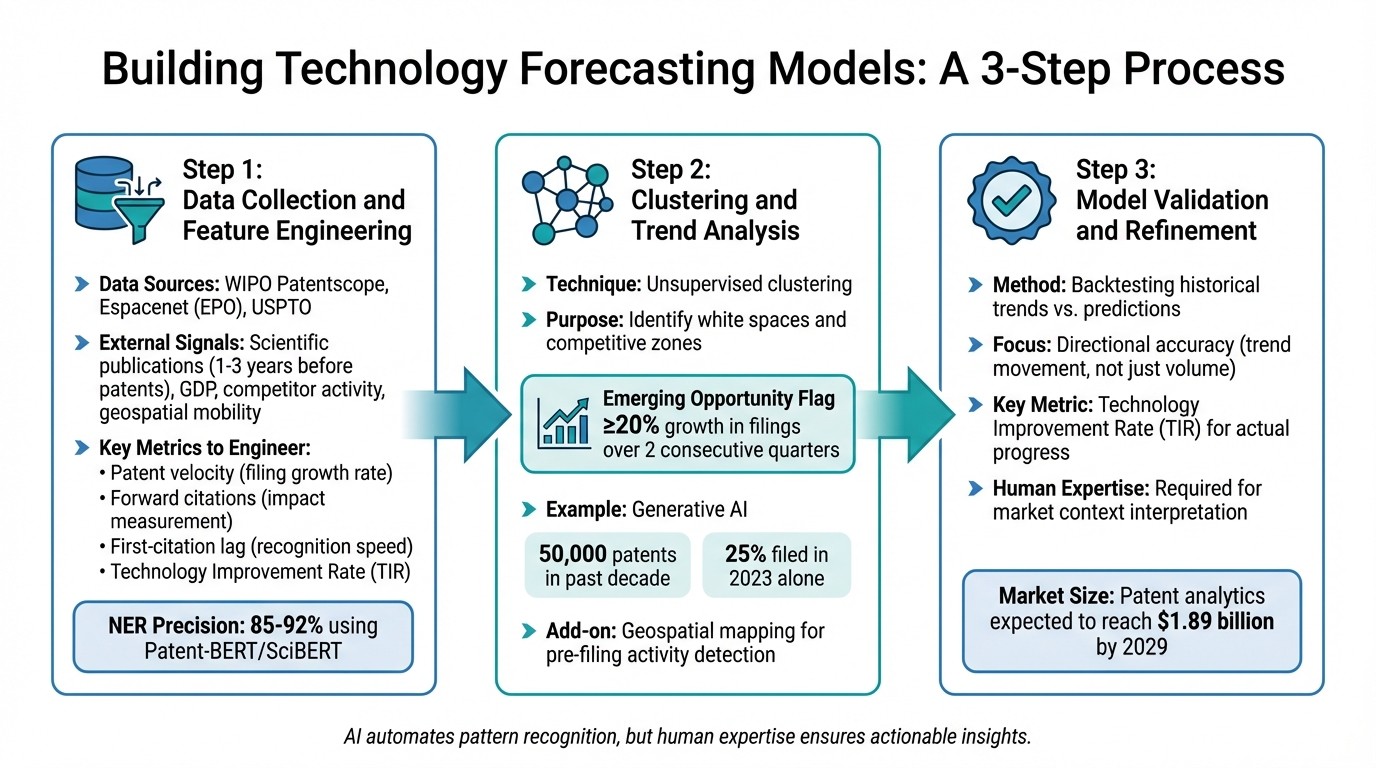
3-Step Patent Data Forecasting Model: From Collection to Validation
Turning patent data into a reliable forecasting model involves a systematic process. It starts with collecting raw data, moves through identifying patterns, and ends with validation. This process transforms patent filings into insights that can predict future technology trends.
Step 1: Data Collection and Feature Engineering
The first step is gathering patent metadata from sources like WIPO Patentscope, Espacenet (EPO), and USPTO. To improve model accuracy, incorporate external signals. For example, scientific publications often precede patent filings by 1–3 years, and economic indicators like GDP, competitor activity, and geospatial mobility around research hubs can highlight innovation hotspots before patent applications surge.
Once the data is collected, it needs to be cleaned and standardized. This includes normalizing assignee names to account for mergers or subsidiaries, and aligning dates, classifications, and legal statuses across jurisdictions. From here, features are engineered to capture innovation dynamics. Key metrics include:
Patent velocity: Tracks the growth rate of filings.
Forward citations: Measures a patent's impact.
First-citation lag: Indicates how quickly a patent gains recognition.
Technology Improvement Rate (TIR): Combines cycle time and knowledge flow to assess performance trends. For instance, TIR revealed SSDs' market potential years before they overtook HDDs.
To extract technical details like chemical compounds or gene targets, domain-specific transformer models such as Patent-BERT or SciBERT are highly effective, achieving 85–92% precision in Named Entity Recognition (NER) tasks. This step bridges raw data with accurate forecasting, laying the groundwork for dependable predictions.
Step 2: Clustering and Trend Analysis
After data preparation, clustering techniques come into play. Unsupervised clustering groups patents by shared concepts and meanings, helping identify "white spaces" (areas with untapped innovation potential) and competitive zones. Emerging opportunities can be flagged when a field shows ≥20% growth in patent filings over two consecutive quarters.
Cross-industry patenting often signals the formation of new ecosystems. For example, when automotive companies file patents in AI and battery chemistry, it suggests a convergence of technologies. Adding geospatial mapping to the mix provides an extra layer of insight, as mobility data around research facilities can highlight activity before patent filings occur. A good example is the generative AI boom - over 50,000 patents were filed in the past decade, with 25% of them filed in 2023 alone. Clustering analysis could have identified this trend early.
Step 3: Model Validation and Refinement
Once trends and clusters are identified, the next step is validating the model to ensure accurate predictions. One effective method is backtesting: compare historical patent filing trends with the model's predictions. Splitting data into training and testing sets helps verify consistency across time and regions.
Validation should focus on directional accuracy - ensuring the model predicts not just the volume of filings but the movement of trends. TIR is particularly useful here, as it measures actual technological progress rather than just the number of filings.
While AI tools automate much of the pattern recognition process, human expertise remains vital. Analysts interpret results and refine forecasts based on market context, ensuring that the insights are actionable and relevant. With the patent analytics market expected to hit $1.89 billion by 2029, driven by AI-powered tools, the importance of rigorous validation cannot be overstated.
Applications in Emerging Technologies
Forecasting models turn patent data into practical insights, especially in rapidly evolving fields. By examining trends in patent filings, citation networks, and overlapping technologies, businesses can identify risks and opportunities before they become apparent in the larger market.
AI and Quantum Computing Trends
Patent data highlights a shift in AI innovation over time. Before 2016, patents primarily focused on specialized tools like neuromorphic computing. Post-2016, the focus shifted to integrated generative frameworks and API-based systems, with multi-modal capabilities taking center stage by 2021.
Geographic patterns also tell an interesting story. China leads the world in AI patent applications, accounting for over 70% of filings, with more than 60% centered on AI chips and semiconductors. Meanwhile, U.S. filings for deep learning and neural networks have grown by 300% in the last decade. Patents related to AI ethics, bias detection, and explainability have multiplied fivefold in just five years.
Quantum computing follows a different growth pattern. Patent filings in this area began to accelerate around 2013, doubling roughly every 1.4 years. Early patents were broad, focusing on foundational quantum principles. As the field matured, filings became more specific, covering areas like qubit implementation, error correction, and "Quantum Computing as a Service" models. Cross-disciplinary innovation is on the rise too, with quantum AI-related patents increasing tenfold in the past decade. These patents often target applications in drug discovery, financial modeling, and cybersecurity.
"The race for quantum supremacy is not just scientific; it's a race for the most valuable intellectual property of the 21st century." - PatentPC
These developments in AI and quantum computing pave the way for major advancements in biotechnology and communications.
Biotechnology and Genomics Innovations
In biotechnology, patent forecasting transforms static legal data into actionable intelligence. R&D teams can examine competitor provisional applications early, identifying unclaimed chemical spaces through unsupervised clustering. This approach helps avoid potential intellectual property conflicts.
The stakes in this industry are enormous. The likelihood of a drug successfully moving from Phase I trials to regulatory approval is just 7.9%, with an average development cost of $2.6 billion per approved drug. Considering that 60–71% of Phase II trials fail, timely patent insights are critical for making informed investment decisions.
Patent trends also reveal shifts in biotechnology innovation. For example, CRISPR and gene editing patents have evolved from protecting molecular tools to covering specific therapeutic applications. Similarly, digital therapeutics - software-driven treatment protocols - have seen rapid growth. Medical AI patents, particularly in the U.S. and China, are growing at an annual rate of over 30%.
SEP Trends in Telecommunications
Standard-essential patents (SEPs) in telecommunications offer another area where forecasting proves invaluable. SEPs cover technologies necessary for implementing industry standards like 4G, 5G, and future network protocols. By analyzing patent filing volumes, participation in standards-setting organizations, and citation patterns among declared SEPs, companies can identify licensing opportunities and anticipate industry shifts.
The top five AI patent-filing countries - China, the U.S., Japan, South Korea, and Germany - account for over 90% of global AI patents. A similar concentration is seen in telecommunications SEPs. Tools like Patently provide specialized analytics to track SEP declarations, assess essentiality claims, and monitor licensing trends in real time. These capabilities are critical as network technologies evolve and new applications emerge.
Best Practices and Common Challenges
Once forecasting models are up and running, keeping them accurate and free from errors is no small task. Patent data is inherently messy - think inconsistent terminology, fragmented records across regions, and classification systems that differ globally. Tackling these challenges requires careful attention to detail and a solid process. By following best practices, you can reduce errors and limit algorithmic biases, ensuring that automated tools and expert oversight work hand in hand for reliable patent forecasting.
Model Accuracy and Explainability
AI models often reflect the biases present in the historical data they're trained on. That’s where Explainable AI (XAI) and human involvement come into play. These approaches help clarify why a model flags certain trends, like emerging technologies. For example, if a model highlights a particular innovation, you should identify the underlying patents, citations, or filing patterns driving that conclusion.
AI excels at processing massive volumes of patent data, spotting patterns, and flagging irregularities. But human experts are still essential for interpreting the broader legal and strategic implications of these findings. Interestingly, research shows that manual patent review quality drops after about 45 minutes of focused work. To counteract this, time-box review sessions and split complex tasks into multiple passes - for example, one session for structural review, another for technical accuracy, and a final one for cross-referencing.
Using Patently for Patent Forecasting
Specialized tools like Patently can help refine your forecasting process. For instance, Patently’s Vector AI semantic search addresses the issue of inconsistent terminology. Traditional keyword searches often miss patents when inventors use different terms for the same concept - like "wireless charging" versus "inductive power station." Semantic search, on the other hand, focuses on the technical meaning, helping to uncover relevant patents that might otherwise be overlooked.
Another standout feature is Patently’s SEP analytics, which is particularly useful for telecommunications forecasting. As technologies like 5G mature and the groundwork for 6G begins, these tools can track SEP declarations, assess essentiality claims, and monitor licensing trends in real time. For teams juggling multiple projects, Patently’s organizational features make it easier to manage workflows while maintaining proper access control.
Avoiding Data and Model Errors
"Patent proofreading is not grammar checking. A patent application can pass every spell-checker and grammar tool and still contain dozens of antecedent basis errors, broken dependency chains, and specification-claim mismatches." - PatentSolve
Errors in patent data can derail your analysis if not caught early. Common issues include broken dependency chains (where claims reference nonexistent parent claims), numbering gaps, and inconsistent classification. AI tools can handle many of these mechanical checks, like spotting sequential numbering problems or duplicate entries that might slip through manual reviews. However, always double-check dependency chains after renumbering, as this is a common source of errors.
While AI summaries can save time, don’t rely on them entirely. Key details in patent claims might get lost. Instead, treat initial AI searches as a starting point to fine-tune your descriptions and search parameters. Keeping a search journal - a record of queries, filters, and results - can also improve your process. This audit trail not only supports due diligence but also helps refine future strategies.
Data Quality Issue | Identification Method | Mitigation Strategy |
|---|---|---|
Varying Terminology | Semantic search/NLP analysis | Use AI-powered semantic search to map concepts |
Broken Dependencies | Automated dependency validation | Confirm dependency chains post-renumbering |
Numbering Gaps | Sequential numbering checks | Automated numbering validation |
Conclusion
Key Takeaways
AI-powered patent data is changing the game in technology forecasting. No longer just static legal documents, patents are now dynamic tools for uncovering real-time insights into competitive and technological shifts as they happen. This evolution allows companies to move from reacting to trends to proactively monitoring them. The result? Businesses can anticipate market entries, pinpoint untapped opportunities, and steer R&D efforts well ahead of their competitors.
AI-driven natural language processing (NLP) tackles the challenges of traditional keyword-based searches, cutting through the dense technical language. Machine learning models have already shown impressive predictive accuracy, achieving 70% to 75% success rates in forecasting Patent Trial and Appeal Board (PTAB) institution decisions. By integrating patent data with scientific research, economic trends, and competitor filings, organizations can identify emerging trends up to three years before they even surface in patent applications.
The best outcomes come from a mix of AI's computational capabilities and human expertise. As DrugPatentWatch highlights:
AI does not replace the patent attorney, the IP strategist, or the drug development team. It removes the computational ceiling that has always constrained how much data those professionals can work with.
AI handles the heavy lifting of processing vast datasets, while human professionals bring the strategic and legal insights that machines can’t replicate. Together, they pave the way for a more advanced and proactive era of patent forecasting. This synergy is also transforming the preparation phase through generative AI patent drafting tools.
The Future of Patent-Based Forecasting
Patent analytics is shifting from static, one-time searches to dynamic, AI-powered dashboards. PowerPatent sums this up well:
A well-built landscape is more like a dashboard that keeps updating in real time, revealing the shape of your competitive and technological surroundings as they shift.
This real-time approach supports global, cross-lingual analysis of patent filings, minimizing the risk of costly errors in Freedom-to-Operate evaluations.
Looking ahead, quantum computing is set to transform the field by processing massive datasets and uncovering intricate relationships that current AI systems can’t yet handle. AI is already proving its worth in navigating complex patent landscapes in areas like quantum computing, biotechnology, and advanced materials. The organizations that embrace AI early in their R&D processes will gain a critical edge - avoiding missteps and identifying high-impact innovations before their rivals even see them coming.
FAQs
Which patent date should I use for forecasting - priority or publication?
The publication date is crucial for forecasting because it indicates when a patent application becomes publicly accessible. This timing offers valuable insights, helping you spot trends in developing technologies and make informed decisions.
How do I avoid double-counting the same invention across filings and kind codes?
To ensure accurate patent counts and avoid double-counting, it's crucial to understand how patent numbers are structured and to use patent family analysis. Patent numbers serve as identifiers for unique inventions, but they can sometimes be misleading if the same invention is filed in multiple jurisdictions or under different applications. This is where patent family analysis comes in - it groups related filings of the same invention, providing a clearer picture. These approaches help prevent inflated statistics caused by multiple filings or variations in kind codes.
What patent metrics best predict real tech progress versus just more filings?
Metrics like forward citations, claims breadth, and patent network strength are essential for gauging true technological advancement. Forward citations measure how much a patent impacts future developments, offering insight into its influence. Claims breadth and patent family size, on the other hand, emphasize the strategic value of a patent. When these metrics are paired with external data - like market trends or scientific research - they help pinpoint innovations that matter, rather than just tracking the sheer number of patent filings.