Large Language Models in Patent Search
Intellectual Property Management
May 18, 2026
LLMs transform patent search by using semantic retrieval and claim-level analysis, boosting recall and speed while requiring human oversight.

Patent searches are no longer just about matching keywords. With over 3.55 million global patent applications filed in 2023, the sheer volume of data makes manual reviews impractical. Large Language Models (LLMs), like GPT-4 and LLaMA, are stepping in to simplify this process by interpreting the meaning behind words rather than relying on exact matches. This shift addresses challenges like vocabulary mismatches and speeds up tasks like prior art searches, claim drafting, and Freedom-to-Operate (FTO) reviews.
Key Takeaways:
Semantic Search: LLMs analyze concepts, not just text, improving recall rates by up to 40% compared to keyword searches.
Efficiency: Tasks like claim mapping and novelty assessments are completed in minutes, saving thousands of dollars in legal costs.
Customization: Fine-tuned LLMs handle complex patent language and machine translations better than general-purpose models.
Limitations: Risks include hallucinations, inconsistent outputs, and data privacy concerns when using consumer-facing AI tools.
Quick Comparison: Traditional vs. LLM-Based Patent Search
Feature | Traditional Search | LLM-Based Search |
|---|---|---|
Search Basis | Exact keyword matching | Conceptual and contextual |
Handling Synonyms | Manual | Automatic |
Recall | Lower (misses 20–40%) | Higher |
Query Input | Boolean operators | Natural language |
Processing Speed | Slower | Faster |
LLMs are reshaping patent workflows, but they’re not perfect. Human oversight remains critical to verify outputs and address risks like hallucinations or data breaches. By combining AI tools with expert judgment, teams can achieve faster, more reliable results while navigating the complexities of patent law.

Traditional vs. LLM-Based Patent Search: Key Differences & Stats
Core Capabilities of LLMs for Patent Search
Understanding Patent Language
Patent documents are written in a highly specialized style, blending legal precision with dense technical details. To navigate this complexity, LLMs transform patent text - such as titles, abstracts, and claims - into high-dimensional numerical vectors through a process called vectorization. This method captures the meaning behind the words, not just the words themselves. For context, the average patent description contains over 11,000 tokens. Advanced models like GPT-4 and Llama-3.1 can now process up to 128,000 tokens in a single pass, making it possible to analyze entire patent documents at once.
One standout feature of LLMs is their ability to be fine-tuned with patent-specific data. This customization enables them to handle the repetitive phrasing, hypothetical examples, and rigid legal structures that are common in patents. While general-purpose models might stumble over this specialized "patent speak", fine-tuned models achieve a much higher degree of accuracy.
Semantic Search and Contextual Retrieval
Traditional keyword searches often fall short because they depend on exact word matches. If an inventor uses different terminology than what's found in prior art, these searches can miss critical documents. LLM-powered semantic search solves this issue by comparing the conceptual meaning of documents using techniques like cosine similarity. For example, a search for "drone" could retrieve patents referring to "unmanned aerial rotorcraft" because the concepts align in vector space. Studies suggest conventional keyword searches can overlook 20–40% of relevant patents, whereas semantic search excels at uncovering conceptually related documents.
Here’s a quick comparison:
Feature | Traditional Keyword Search | LLM-Based Semantic Search |
|---|---|---|
Search Basis | Exact word/string matching | Conceptual and contextual meaning |
Synonym Handling | Manual (requires listing all variations) | Automatic (understands related terms) |
Recall | Lower (misses 20–40% of relevant documents) | Higher (captures related concepts) |
Query Type | Boolean operators and rigid syntax | Natural language queries |
Speed | Slower (often needs manual tweaks) | Fast (results in seconds) |
Many professionals now blend vector-based retrieval with Boolean filters, like CPC/IPC classifications or date ranges, to balance broad recall with precision. For instance, in October 2024, Laurence Brown, an IP expert, used Patently's Vector AI tool - powered by Elastic's Search AI and vector search - to sift through 82 million patent families. In under five minutes, he identified 300 relevant Sony applications.
This semantic capability also lays the groundwork for automating tasks like claim summarization and drafting.
Claim Summarization and Drafting Support
LLMs can automatically summarize independent claims, pinpoint key elements, and map out dependencies between claims. This helps clarify how dependent claims build on independent ones, making it especially useful for risk assessments where understanding claim scope is critical.
Research indicates LLMs are adept at drafting initial independent claims but face challenges when generating dependent claims. However, they excel in handling machine-translated patents, which often contain non-standard wording. Traditional rule-based tools struggle in these cases, but LLMs adapt with ease.
"The LLM approach is particularly useful when dealing with machine translations. It's impossible to hard-code every possible wording... LLMs handle these variations far better." - Patent.dev
LLMs also shine in rare or emerging technology areas, often referred to as the "long tail."
"LLMs achieve relatively higher performance on infrequent subclasses, often associated with early stage, cross domain, or weakly institutionalised technologies." - Lorenzo Emer et al.
This makes them especially valuable in fast-evolving or niche fields where patent language hasn’t yet standardized.
Practical Applications of LLMs in Patent Workflows
Prior Art and Invalidity Searches
LLMs are changing how prior art searches are conducted. Instead of just providing ranked lists of documents, these models now create synthesized novelty assessments, complete with claim-level evidence mapping and detailed rationale for their conclusions.
One key development is claim-element decomposition. Rather than treating a claim as a single block, LLMs break it down into individual elements and search for prior art relevant to each component. This is crucial because a single document might not fully anticipate a claim, but a combination of references could. LLMs can automatically suggest these combinations for obviousness (§ 103) arguments, evaluate their strength, and provide explanations for the "motivation to combine."
"Systems that return ranked document lists are being superseded by systems that generate novelty assessments, draft claim language, and produce prosecution-ready reports - the shift from retrieval to generation is the defining transition of 2024–2026." - PatSnap
For example, IBM's 2025 U.S. patent on "Validation of Novelty with Artificial Intelligence and Heuristics" demonstrates this trend. It uses techniques like particle swarm optimization and topic modeling within NLP pipelines, allowing LLMs to produce novelty reports that explain their conclusions rather than just surfacing documents. This approach naturally extends into more intricate tasks, like Freedom to Operate (FTO) analysis.
Freedom to Operate (FTO) Analysis
FTO analysis, historically one of the most resource-intensive tasks in patent work, is now being streamlined with AI. Traditional FTO opinions from outside counsel can cost anywhere from $50,000 to $100,000, but AI-powered workflows are reducing those costs significantly. Tasks that previously took 100 hours can now be completed in just 20, saving $20,000–$30,000 per claim chart.
The primary improvement comes from element-by-element claim mapping. LLMs analyze product descriptions, technical documents, or even PDFs and generate detailed claim charts that map product features to third-party patent claims. These charts often use visual tools like color-coded confidence indicators (Disclosed, Suggested, or None) to rank risk levels, enabling attorneys to focus on high-priority areas instead of starting from scratch.
LLMs also excel at interpreting machine-translated foreign patents, which have historically been a challenge. For instance, when a Korean or Chinese patent uses unconventional phrasing like "according to paragraph 1" to indicate claim dependencies, traditional algorithms often fail. LLMs, however, adapt to these variations with ease. By running an initial internal investigation using AI tools, companies can narrow the scope of legal work before engaging outside counsel, keeping expenses under control.
Patent Drafting and Prosecution Support
LLMs are proving invaluable in patent drafting and prosecution, functioning as both writing assistants and quality control tools. A typical patent application involves over 200 noun phrase introductions that must align with more than 500 subsequent references. While manual proofreading of a 25-claim application can take 30–60 minutes, AI completes these checks in seconds.
These models are particularly effective at verifying antecedent bases and ensuring proper dependencies after claim revisions, significantly cutting down proofreading time. They also cross-reference specifications to ensure claim terminology matches the detailed description and drawings, reducing the risk of errors caused by cognitive fatigue, especially in later claims.
"The attorney who uses AI proofreading does not do less work - they do better work." - PatentSolve Team
During prosecution, LLMs help maintain consistency when claims are restructured in response to office actions. This prevents "amendment traps", where dependency references mistakenly point to canceled claims. A recommended approach is to let AI handle all mechanical checks in a two-pass workflow. This frees up attorneys to concentrate on strategic decisions and legal judgment - areas where human expertise still holds the upper hand.
Limitations and Risks of LLMs in Patent Search
Technical Limitations
While large language models (LLMs) have impressive capabilities, they come with inherent flaws that pose challenges in the highly precise field of patent work. One of the most concerning issues is their tendency to "hallucinate", or generate responses that sound convincing but are entirely fabricated. For instance, GPT-3 produces incorrect or nonsensical responses about 15% of the time. In patent work, where even a single mistake can derail a prosecution strategy, such errors are far from trivial.
Another limitation is the drop in performance when drafting dependent claims. While LLMs can craft a solid independent claim, they often struggle with maintaining technical coherence and properly linking features in dependent claims. Surprisingly, patent-specific LLMs have shown weaker performance compared to general-purpose models like GPT-4 in expert evaluations.
Consistency is yet another hurdle. A study comparing seven AI-based patent search tools revealed that 90% of the references identified were unique to each system. Only 20 out of 225 references appeared in the results of more than one tool. Charles Eldering aptly summarized the challenge:
"The real question is not whether AI can search patents, but whether it can make different people see the same prior art when faced with the same claim."
This lack of overlap highlights the importance of carefully reviewing outputs from any single system. Beyond these technical challenges, concerns around data security and validation further complicate the adoption of LLMs in patent workflows.
Data Privacy and Confidentiality
In addition to technical issues, using LLMs in patent work raises significant concerns about data privacy. Feeding invention disclosures into an LLM could lead to the permanent loss of trade secret protection if proprietary information ends up on public platforms. Unlike a data breach, which might be addressed with legal remedies, public disclosure irreversibly destroys trade secret status.
To mitigate risks, avoid using consumer-facing chatbots for patent-related tasks. Enterprise API solutions from providers like OpenAI and Anthropic explicitly exclude customer inputs from model training. However, other providers, such as Cohere, may retain rights to use input data for service improvements. Carefully review vendor contracts for "Input Usage Rights" before onboarding any system. For highly sensitive disclosures, consider deploying on-premise or private cloud solutions with Role-Based Access Controls (RBAC).
"When using a public LLM or an LLM not confined to a secure workspace, practitioners should be careful not to include confidential or otherwise non-public information to avoid inadvertent disclosure - including the risk of being incorporated into the model's training." - Nicholas Martin, Of Counsel, Greenberg Traurig
The Role of Human Oversight
Even when LLMs deliver strong results, rigorous human oversight remains essential. Automated metrics like BLEU and ROUGE, commonly used to assess quality, are not always reliable for patent content. For example, a study of 400 LLM-generated claims found that ROUGE-L had a negative correlation (r = -0.159) with expert annotations, indicating that a high automated score doesn’t necessarily mean high-quality output.
LLMs should be viewed as tools for initial drafts and retrieval tasks, not as replacements for expert judgment. While AI can assist with tasks such as query expansion and preliminary drafting, critical steps like shortlist review, claim interpretation, and strategic decision-making must remain in human hands. As one research team put it:
"Doxa should be framed as augmented patent reasoning, not replacement thinking. That is the honest and stronger position."
Recognizing these limitations emphasizes the importance of a collaborative approach where human expertise complements AI capabilities in patent search workflows.
How to Implement LLMs in Patent Search Workflows
How to Evaluate LLM-Based Tools
When evaluating tools powered by large language models (LLMs) for patent searches, focus on three main factors: comprehensive coverage, semantic search quality, and security standards. A solid tool should cover over 150 global patent authorities, including key ones like USPTO, EPO, and CNIPA. It should also adhere to high security benchmarks, such as SOC 2 Type II compliance and ISO 27001 certification. Semantic search capabilities are critical, as they can deliver 30–60% more relevant prior art compared to traditional Boolean searches.
Before committing to a tool, test its capabilities through a five-query benchmark. This should include:
A straightforward natural language query
A cross-domain concept search
A foreign language query
A detailed claim-element search
A broad landscape exploration
Patently is an example of a platform that integrates AI-driven semantic search (via its Vector AI) with collaborative project management tools, ensuring sensitive data remains securely managed.
"A patent clearance decision based on one AI's results is essentially a gamble. Using two or more tools transforms that gamble into a calculated risk." - PowerPatent
Once you've identified the right tool, the next step is weaving it into your team's workflow.
How to Optimize Patent Team Workflows
Choosing the right LLM-based tool is just the beginning. To maximize its value, refine how your team approaches patent searches. Clarity is crucial when working with LLMs. Describe inventions in layers: start with a high-level explanation of its purpose, then dive into the technical details, and finally, outline any alternative approaches considered but not implemented. This layered approach helps the AI differentiate between the problem and the solution, which is important since patents often share similar problem statements but vary in their solutions.
Avoid relying on keyword lists. Instead, use full sentences and plain, widely understood language. Translate internal project names and proprietary terms into standard technical terms to improve the AI's understanding. Start with a test query, review the results, refine your description, and repeat until the results align with your needs.
A dual-mode workflow is particularly effective. Combine structured searches - using precise keywords, dates, and CPC classifications for known risks - with open-ended semantic searches to uncover conceptual overlaps and cross-industry insights. For instance, a search on drone vibration-dampening technology might surface relevant prior art from heavy machinery mounts, something a traditional keyword search might miss. Throughout this process, maintaining a detailed search journal is crucial. Not only does it provide an audit trail, but it’s also invaluable for due diligence and litigation.
Metrics for Measuring Success
To determine whether your workflow is hitting the mark, track key metrics like recall rates and time savings. A well-implemented AI workflow should achieve a recall rate of over 90% for known prior art in test datasets. Additionally, integrating these tools effectively can lead to significant time savings - around 10–15 hours per case and a reduction of approximately 20 hours of search time per attorney each month.
As highlighted by a research team:
"The operational principle is simple: retrieval first, selective deepening second, synthesis third. That is how you reduce hallucination risk, query cost, and human review fatigue at the same time." - PapersFlow
Understanding PatSeer's AI Patent Search: A Guide to LLM-Driven Technology
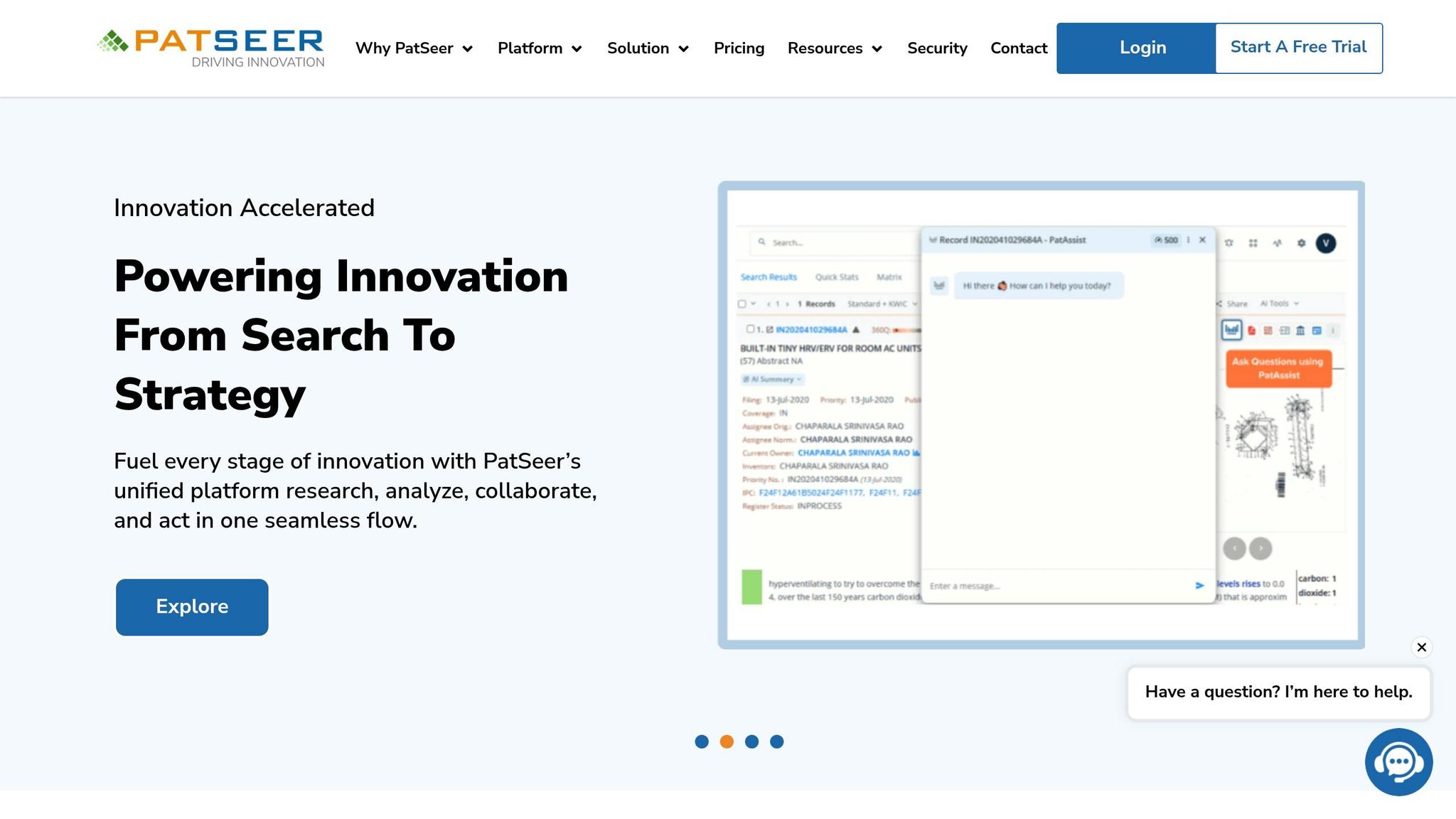
Conclusion
Large Language Models (LLMs) have reshaped the way patent searches are conducted. By going beyond simple keyword matching, these models can interpret technical intent and seamlessly integrate into drafting workflows. This shift can save time and improve efficiency by simplifying routine search tasks.
That said, they are not without their challenges. While efficient, LLMs still require careful human oversight. Risks like hallucinations, semantic drift, and data privacy concerns - especially in critical tasks like Freedom-to-Operate analyses - highlight the need for a balanced approach. A hybrid model works best: use AI for broad conceptual exploration, then rely on Boolean searches and human validation for precision.
For patent teams looking to embrace this method, platforms like Patently offer a comprehensive solution. Combining advanced Vector AI semantic search with AI-assisted drafting tools and collaborative project management, these tools help streamline workflows, moving away from manual, fragmented processes toward something faster and more reliable.
Ultimately, LLMs serve as an excellent starting point for analysis, but their findings must be rigorously reviewed to ensure accuracy and minimize legal risks.
FAQs
How does semantic search find prior art that keywords miss?
Semantic search works by focusing on the meaning of patent texts rather than sticking to exact keyword matches. Using advanced natural language processing (NLP) models, it translates text into numerical vectors that represent the core ideas and concepts.
This approach enables the system to uncover patents with similar ideas, even when they use different words or phrases. By tackling issues like vocabulary differences and language ambiguities, semantic search improves both accuracy and recall in identifying relevant prior art.
How can I use LLMs for FTO without risking confidentiality?
When conducting Freedom to Operate (FTO) analysis with large language models (LLMs), prioritizing data security is key. Choose AI tools that operate within secure environments, such as on-premises systems or private cloud setups, to keep your data protected from external access.
Before using any platform, check that it has robust privacy policies and strong security measures in place. And most importantly, avoid entering sensitive or confidential information into tools that are unsecured or connected to external systems. This simple step can significantly reduce the risk of compromising sensitive data.
What’s the best way to validate LLM search results for legal work?
To ensure the accuracy of LLM search results in legal work, it's essential to apply a structured evaluation framework, such as PatentScore. This framework examines outputs across three key areas: structural, semantic, and legal dimensions.
Testing AI tools against historical legal cases is another smart way to measure their reliability and precision. By benchmarking results against known outcomes, you can gauge how well the tool performs in real-world scenarios.
On top of that, practical steps like visually reviewing results and running regression tests with familiar cases can help verify the quality of the AI's outputs. These methods provide an extra layer of confidence before incorporating the results into critical legal decisions.