Natural Language Processing in Patent Search
Intellectual Property Management
Apr 5, 2026
NLP enhances patent prior-art searches with semantic search, embeddings, NER, and LLM claim analysis to boost accuracy and cut search time.

Natural Language Processing (NLP) is transforming how patents are searched and analyzed. Traditional keyword-based searches often miss relevant results due to inconsistent terminology across patents. NLP solves this by understanding the meaning behind words, enabling more accurate and efficient searches. Here's what you need to know:
Why It Matters: Keyword searches miss 20–40% of relevant prior art due to vocabulary mismatches. NLP bridges this gap by recognizing semantic relationships between terms.
Key Techniques: NLP uses tokenization, Named Entity Recognition (NER), semantic embeddings, and large language models to process complex patent language and identify conceptually related documents.
Efficiency Gains: Top-tier AI patent tools reduce time spent on patent searches by up to 80%, saving firms significant time and costs.
Applications: NLP powers semantic searches, automatic patent classification, and claim analysis, enhancing accuracy and retrieval speed.
Challenges: Patent language complexity, domain-specific training needs, and scalability issues remain hurdles for NLP systems.
NLP is reshaping patent management by improving accuracy, reducing search times, and enabling cross-lingual searches. As tools evolve, they promise to make patent professionals’ work faster and more precise.
How Is AI Improving Patent Prior Art Searches? - Trademark and Patent Law Experts
Core NLP Techniques for Patent Search
Patent searches have evolved significantly, moving beyond simple word matching to a deeper understanding of concepts. This shift is powered by three key NLP techniques: tokenization with NER, semantic search with embeddings, and large language models. Together, these tools enable a more nuanced and efficient approach to uncovering relevant patents.
Tokenization and Named Entity Recognition
Tokenization breaks down patent text into smaller units like words, stems, or n-grams. This ensures that variations of a term, such as "car" and "cars", are included in search results.
Named Entity Recognition (NER) takes this further by categorizing critical elements in patents - like inventors, assignees, technical terms, dates, and locations. Unlike traditional keyword indexing, which treats all words equally, NER assigns tokens into predefined categories such as "Inventor" or "Assignee." This approach drastically reduces false positives by resolving name variations and contextual ambiguities.
The impact? One prominent Am Law 100 firm reported an 80% reduction in time spent on complex patent searches - cutting 100 billable hours down to just 20 - after implementing AI-driven tools. These AI-enabled patent analysis platforms streamline complex workflows for novelty and validity searches. Additionally, mapping patents into specific field categories (up to 226 distinct fields) allows for more precise filtering and retrieval.
While tokenization and NER lay the groundwork, semantic search techniques take it a step further by capturing the deeper meanings embedded in patent language.
Semantic Search with Embeddings and Transformer Models
Semantic embeddings represent patent documents and search queries as multi-dimensional mathematical vectors. This enables systems to identify conceptual similarities, even when different inventors use varied terminology to describe the same idea. For instance, terms like "Datenverarbeitung" and "data processing" can be equated, breaking down language barriers.
Transformer models like BERT, paired with algorithms such as KNN, allow patent searches to move beyond exact word matches. Unlike traditional Boolean searches, which are precise but often miss synonyms or related terms, semantic search improves recall by uncovering patents that are conceptually related.
This approach ensures that patents are retrieved based on their deeper meaning, not just the exact phrasing used.
Large Language Models for Claim Analysis
Large language models (LLMs) take patent analysis to another level, particularly when it comes to claims. These models break down claims into structural, legal, and semantic components, ensuring completeness and flagging any inconsistencies in language.
LLMs also create embeddings that encapsulate the meaning of claims, enabling search systems to recognize terms like "self-driving cars" even when the query uses "autonomous vehicle." For example, PatentScore, powered by GPT-4o-mini, achieved a Pearson correlation of r = 0.819 with human annotations. Research also shows that analyzing claims in the context of the full patent description yields more accurate results than relying solely on abstracts, which often lack technical detail.
The efficiency gains are substantial. Drafting a single patent application typically takes 30 to 40 hours of expert work and costs between $5,000 and $15,000. By integrating generative AI patent drafting tools for real-time prior art searches, some biotechnology companies have reported saving 10 to 15 hours per application.
These advanced NLP techniques - tokenization with NER, semantic embeddings, and LLMs - are revolutionizing patent searches, enabling more accurate and efficient identification of prior art.
Benefits of NLP in Patent Search
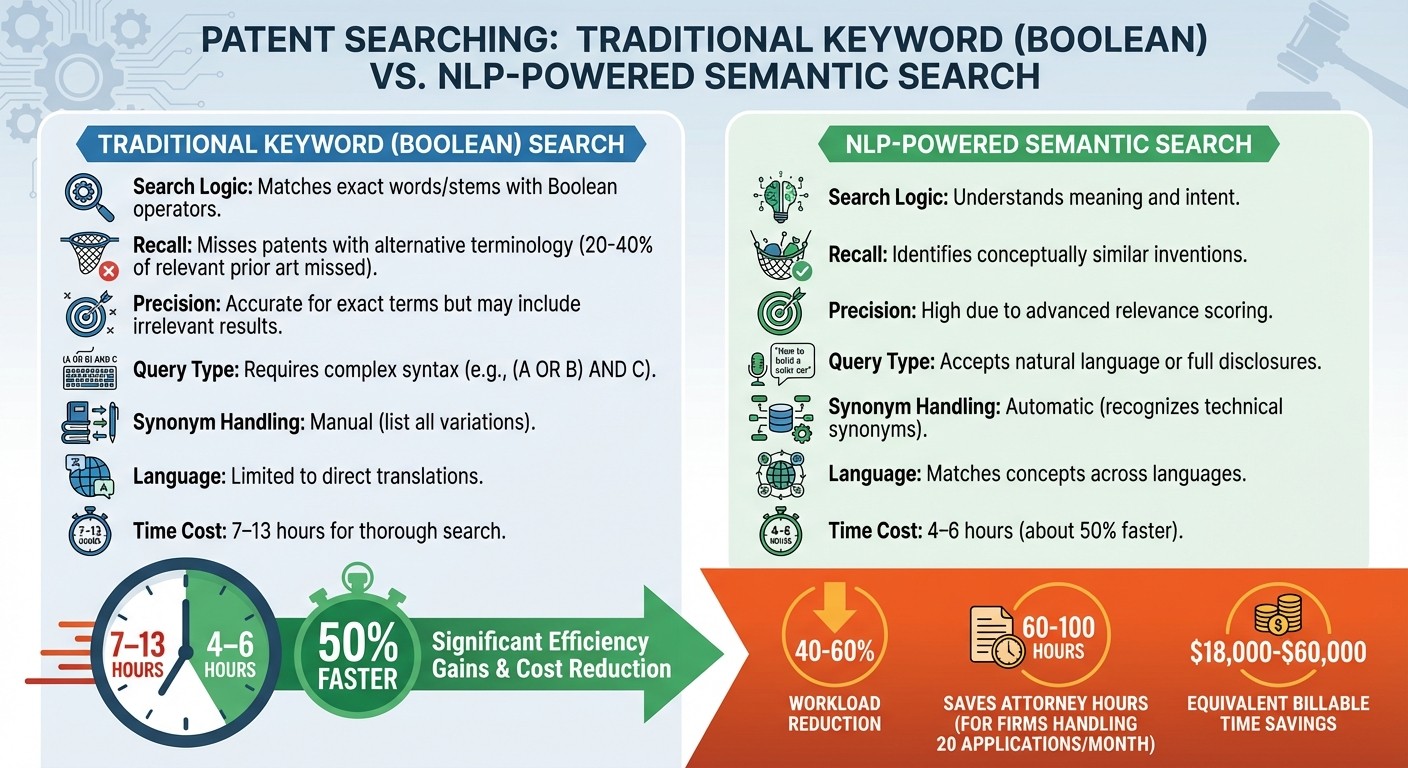
Traditional vs NLP-Powered Patent Search: Key Differences and Efficiency Gains
NLP is reshaping patent search by introducing tools that go beyond traditional methods, making the process faster and more precise.
Better Accuracy and Semantic Understanding
One of NLP's biggest strengths is its ability to focus on meaning rather than just matching words. Techniques like semantic embeddings and transformer models allow it to recognize concepts, even when different terms are used. For instance, a traditional keyword search might miss the connection between "autonomous vehicle" and "self-directed mobile platform", but NLP identifies these as conceptually the same. This is a big deal because keyword-based searches can overlook 20% to 40% of relevant prior art simply due to variations in terminology.
NLP achieves this by converting patent text into multi-dimensional vectors that capture the underlying meaning, enabling it to find related documents without relying on exact word matches. It also adapts to changes in language over time, bridging the gap between modern queries and older patents that might use outdated terminology. With over 70% of patent applications filed outside the U.S., NLP's ability to connect terms across languages is crucial. For example, it can link the German term "Datenverarbeitung" to the English "data processing" by understanding their conceptual similarity.
Moving Beyond Keyword Limitations
NLP also eliminates the need for clunky Boolean syntax, making the search process much more user-friendly. Traditional searches require users to carefully construct queries using operators like AND, OR, and NOT, as well as manually include every possible synonym. NLP, on the other hand, allows users to input natural language queries, such as "Find patents about AI systems that improve industrial process efficiency", or even paste an entire invention disclosure into the search tool.
"The semantic approach understands intent without requiring perfect operator syntax or exhaustive keyword variations." - PatentScanAI
This ease of use saves significant time. A thorough prior art search using traditional methods can take anywhere from 7 to 13 hours. By leveraging semantic AI, the workload is reduced by 40% to 60%, cutting the time down to just 4 to 6 hours. For firms handling 20 applications a month, this translates to saving 60 to 100 attorney hours - equivalent to $18,000 to $60,000 in billable time.
Traditional Search vs NLP-Based Search Comparison
Feature | Traditional Keyword (Boolean) Search | NLP-Powered Semantic Search |
|---|---|---|
Search Logic | Matches exact words/stems with Boolean operators | Understands meaning and intent |
Recall | Misses patents with alternative terminology | Identifies conceptually similar inventions |
Precision | Accurate for exact terms but may include irrelevant results | High due to advanced relevance scoring |
Query Type | Requires complex syntax (e.g., | Accepts natural language or full disclosures |
Synonym Handling | Manual (list all variations) | Automatic (recognizes technical synonyms) |
Language | Limited to direct translations | Matches concepts across languages |
Time Cost | 7–13 hours for thorough search | 4–6 hours (about 50% faster) |
Applications and Use Cases
NLP plays a critical role in modern patent research, supporting tasks like classification, citation analysis, and much more. Let's explore some of the key applications in this field.
Patent Classification and Retrieval
One of the standout uses of NLP is its ability to automatically categorize patents into specific technology fields. By analyzing linguistic patterns in patent claims, models like XG Boost and Transformer-based architectures assign classification codes such as WIPO or CPC categories. For instance, an XG Boost model applied to patent claims achieved 87.1% accuracy for chemistry patents and 78.9% for electrical engineering patents.
This innovation has drastically reduced the need for manual classification. The USPTO, which previously spent $95 million over five years on manual classification services, introduced an AI-powered auto-classification tool in December 2020. This tool assigns Cooperative Patent Classification (CPC) codes almost instantly upon submission, streamlining the process significantly. Beyond just classification, these models also power semantic search for tasks like novelty detection.
Semantic Search and Novelty Detection
Semantic search has transformed how prior art is identified, focusing on understanding concepts instead of just matching keywords. Tools like Patently's Vector AI, built on Elastic's Search AI platform, manage an impressive database of over 82 million patent families and 135 million individual patents. Using vector embeddings, the system can identify conceptually similar documents, even when terminology differs.
An IP professional demonstrated the system’s efficiency, retrieving 300 relevant results in less than five minutes.
Jerome Spaargaren, Founder and Director of Patently, highlighted its importance: "Vector AI... has positioned Patently as one of the most innovative platforms for semantic patent search and is core to our technology stack".
Citation and Information Extraction
NLP also simplifies the extraction of structured data from dense patent texts. By leveraging tools like Named Entity Recognition (NER) and Information Extraction (IE), it can pull out key details such as citations, technical specifications, inventors, companies, and dates. Advanced language models like GPT-4 and Llama-3.1, with their ability to process up to 128,000 tokens, can handle entire patent documents effectively.
Patently’s platform takes this a step further by using vector search to uncover intricate data relationships, delivering real-time insights.
Andrew Crothers, Creative Director at Patently, described its value: "With Elastic, it's like having a patent attorney with decades of experience guiding every search".
Challenges and Limitations of NLP in Patent Search
While NLP has reshaped patent search, the field still faces significant obstacles due to the unique nature of patent documents. Recognizing these challenges is key to understanding what AI can realistically achieve in this specialized domain.
Complexity of Patent Language
Patent documents are intentionally written in a highly complex and technical style, often straying far from everyday language. Inventors and attorneys frequently use different terms for the same concept - for example, one patent might say "automobile brake system", while another opts for "vehicular deceleration apparatus." This inconsistency in terminology can cause traditional searches to miss 20–40% of relevant prior art, posing a considerable challenge for NLP tools.
Patents also define terms in unique ways, making even advanced NLP models struggle to interpret them. Lekang Jiang from the University of Cambridge highlights this issue:
"The patent language focuses more on precision and accuracy than on readability".
Another hurdle is the sheer size of patent documents, with the average description exceeding 11,000 tokens. These texts often include intricate legal clauses and hypothetical experiments, which can confuse models trained on standard datasets. For example, NLP systems may mistakenly treat "prophetic" experiments (hypothetical scenarios) as factual data.
These challenges underline the importance of training NLP models specifically on patent-related data.
Domain-Specific Training Requirements
General-purpose NLP models often fall short in patent analysis because they lack exposure to the specialized vocabulary and legal nuances of patent documents. As PatentScanAI explains:
"The vocabulary mismatch problem is perhaps the most significant challenge. Inventors and patent attorneys often describe the same technical concept using completely different terminology".
Specialized training can make a noticeable difference. In October 2025, researchers Amirhossein Yousefiramandi and Ciarán Cooney from Clarivate introduced ModernBERT-base-PT, a model trained on a curated dataset of 64 million patents (31.6 billion tokens). This model achieved an F1 score of 0.814 on the WIPOEC dataset, outperforming the general ModernBERT-base, which scored 0.786. It also delivered faster inference speeds, processing 157.2 samples per second, compared to 44.0 samples per second for older PatentBERT models.
Preparing the training corpus is a critical step. Techniques like removing irrelevant text and applying fuzzy deduplication can reduce the dataset size by over 30%, improving model efficiency. Additionally, custom tokenizers designed for patent language prevent technical terms from being broken into meaningless fragments, boosting performance further.
However, scaling these systems introduces another set of challenges.
Evaluation and Scalability Issues
Handling a global patent database of over 130 million documents requires immense computational power and efficient data organization. Complicating matters, more than 70% of patent applications are filed outside the U.S., meaning models must navigate cross-linguistic semantic relationships that don’t always translate cleanly.
Transparency is another issue. Many NLP models operate as "black boxes", making it hard for legal professionals to understand why certain patents are flagged as relevant. This lack of interpretability can undermine trust in AI-powered tools.
Another major challenge is the absence of standardized benchmarks. Researchers at the University of Cambridge emphasize:
"The lack of benchmark tests, such as reference datasets and established metrics, hinders performance evaluation and comparison across different methods".
Without clear metrics or reference datasets, it's tough to measure improvements or compare different NLP approaches. Additionally, restricted access to bulk patent data - due to paywalls or limitations imposed by patent offices - further complicates efforts to train and evaluate these models effectively.
Overcoming these hurdles is essential for improving the accuracy and reliability of NLP-driven patent searches, paving the way for future advancements in the field.
Future Trends in NLP for Patent Management
The coming decade promises to reshape how patent professionals utilize NLP technology, revolutionizing everything from drafting to portfolio management strategies.
Generative AI for Patent Drafting
Generative AI is already making waves in patent application drafting. Tools like PatentGPT and PatentGPT-J are specifically designed to handle the technical and legal complexities of patent language. Unlike general-purpose language models, these tools are tailored to meet the precise needs of the intellectual property domain.
The productivity boost is clear. For example, a biotechnology company reported saving 10 to 15 hours per patent application by incorporating AI-assisted drafting into their processes.
"We saw a notable decrease in the time spent on routine drafting tasks. That meant we could focus more on strategy and high-value legal work instead of repetitive writing", shared the President of a leading IP law firm.
The technology itself has advanced significantly. Models like Llama-3.1 and Gemini 1.5 now support context windows of up to 128,000 tokens. This capability allows them to process entire patent applications - often exceeding 11,000 tokens - in a single pass, ensuring continuity and accuracy across lengthy technical descriptions.
Multimodal NLP and Advanced Analytics
The future of patent analysis goes beyond text. Multimodal NLP combines text processing with tools like CLIP and GPT-4V, enabling the analysis of patent drawings, chemical structures, and technical diagrams alongside written descriptions. This is especially valuable in industries like mechanical engineering and pharmaceuticals, where visual data plays a critical role.
Predictive analytics is also gaining traction. Machine learning models now predict outcomes like Inter Partes Review institution rates and Patent Trial and Appeal Board (PTAB) decisions with 70% to 75% accuracy. For pharmaceutical companies, where a single compound patent can represent a net present value of $5 billion to $15 billion, these insights are transforming IP strategies from reactive to proactive.
Cross-lingual capabilities are another game-changer. Multilingual transformer models like BERT and XLM-RoBERTa can map global patent filings from databases like CNIPA (China) into a shared vector space. This enables unified patent searching for Freedom To Operate across jurisdictions, a critical feature given that over 70% of patent applications are filed outside the U.S..
These advancements pave the way for fully integrated platforms that streamline patent management from start to finish.
Integration with AI Platforms like Patently
The true potential of NLP emerges when integrated into comprehensive platforms that manage the entire patent lifecycle. Patently is a prime example, combining AI-assisted drafting via its Onardo tool with semantic search powered by Vector AI. This creates a seamless, end-to-end solution for patent professionals.
The benefits are tangible. A Director of IP & Litigation at a major cybersecurity firm used such an integrated platform to assess infringement risks internally, saving $20,000 to $50,000 per case by eliminating the need for external counsel. This trend highlights a shift from standalone tools to unified ecosystems that support everything from ideation to litigation within a single workflow.
"AI does not replace the patent attorney... It removes the computational ceiling that has always constrained how much data those professionals can work with".
Looking forward, Explainable AI (XAI) will likely take center stage. These systems provide human-readable explanations for their decisions, addressing regulatory transparency requirements like GDPR. By tackling the "black box" issue, XAI will ensure that AI remains both effective and accountable, tying together the many advancements transforming patent management today.
Conclusion
Natural language processing (NLP) has reshaped how patent searches and analyses are performed, moving the process far beyond simple keyword matching. By introducing semantic understanding, NLP bridges the vocabulary gap that often exists between inventors and examiners, significantly reducing the chances of missing relevant prior art during searches.
The impact on efficiency is striking. For example, a top Am Law 100 firm reported cutting search time by 80%, slashing 100 billable hours down to just 20. Similarly, a biotechnology company saved 10–15 hours per application thanks to these advancements.
Patent search technology continues to evolve at a rapid pace. Tools powered by vector embeddings, transformer models, and cross-lingual capabilities are redefining both accuracy and efficiency in this field. Platforms like Patently showcase this evolution by combining advanced semantic search with collaborative project management and AI-assisted drafting through Onardo. Impressively, these tools manage a database containing over 135 million individual patents.
"With Elastic, it's like having a patent attorney with decades of experience guiding every search", says Andrew Crothers, Creative Director at Patently.
The pressing question now is how quickly patent professionals will adopt these advanced NLP tools. This technology has moved beyond experimental phases; it’s now an essential part of managing the complexity and scale of modern patent portfolios.
FAQs
How does NLP find relevant prior art without exact keywords?
Natural language processing (NLP) transforms patent searches by focusing on the semantic meaning behind invention descriptions rather than sticking to exact keyword matches. This means it can recognize related inventions even when they’re described using different terms or industry-specific jargon.
With tools like large language models (LLMs), NLP can interpret complex queries and connect them to broader concepts. This approach makes searches more thorough and helps minimize the chances of overlooking important prior art.
What patent data should be indexed to get the best semantic search results?
To get the best results with semantic search, it's essential to index a wide range of patent data. This includes metadata like patent numbers and titles, as well as the full text content, such as descriptions, claims, and abstracts. The detailed claims and descriptions are especially important because NLP models need this rich context to interpret inventions effectively.
Adding synonyms, technical terms, and variations in terminology can further improve the AI's ability to understand and match concepts accurately. This approach ensures searches return results that are both precise and highly relevant.
How can patent teams trust and validate AI search results at scale?
Patent teams can build confidence in AI-driven search results by implementing strict validation methods. This includes ensuring results align with both legal and technical standards. Leveraging tools like semantic search powered by vector AI can boost relevance by grasping the meaning behind concepts, not just matching keywords. When paired with reproducible workflows, thorough quality checks, and established natural language processing practices, these approaches help maintain consistent accuracy and dependability, even when working with massive datasets.