Neural Networks for Patent Trend Prediction
Intellectual Property Management
Dec 18, 2025
Neural networks (MLPs, RNNs, GNNs) analyze patent filings, citations, and time-series data to forecast technology trends and improve IP workflows.

Neural networks are reshaping how patent trends are predicted. They analyze historical patent data to forecast technological growth, helping businesses make smarter R&D and investment decisions. By using different architectures like MLPs, RNNs, and GNNs, these models process structured data, track trends over time, and identify influential patents through citation networks. Here's what you need to know:
MLPs handle structured data like patent filing counts and classifications.
RNNs analyze time-series data, predicting how trends evolve.
GNNs map relationships in citation networks to spot impactful patents.
Data preparation is key - patent details like titles, abstracts, and citation links must be carefully curated. Training involves fine-tuning hyperparameters and evaluating models with metrics like accuracy and RMSLE. Tools like Patently's AI-powered analytics enhance predictions, making patent workflows more efficient.
Neural networks simplify complex patent landscapes, offering insights that drive innovation and competitiveness. However, combining AI with human expertise ensures reliable and actionable results.
Neural Network Architectures for Patent Trend Prediction
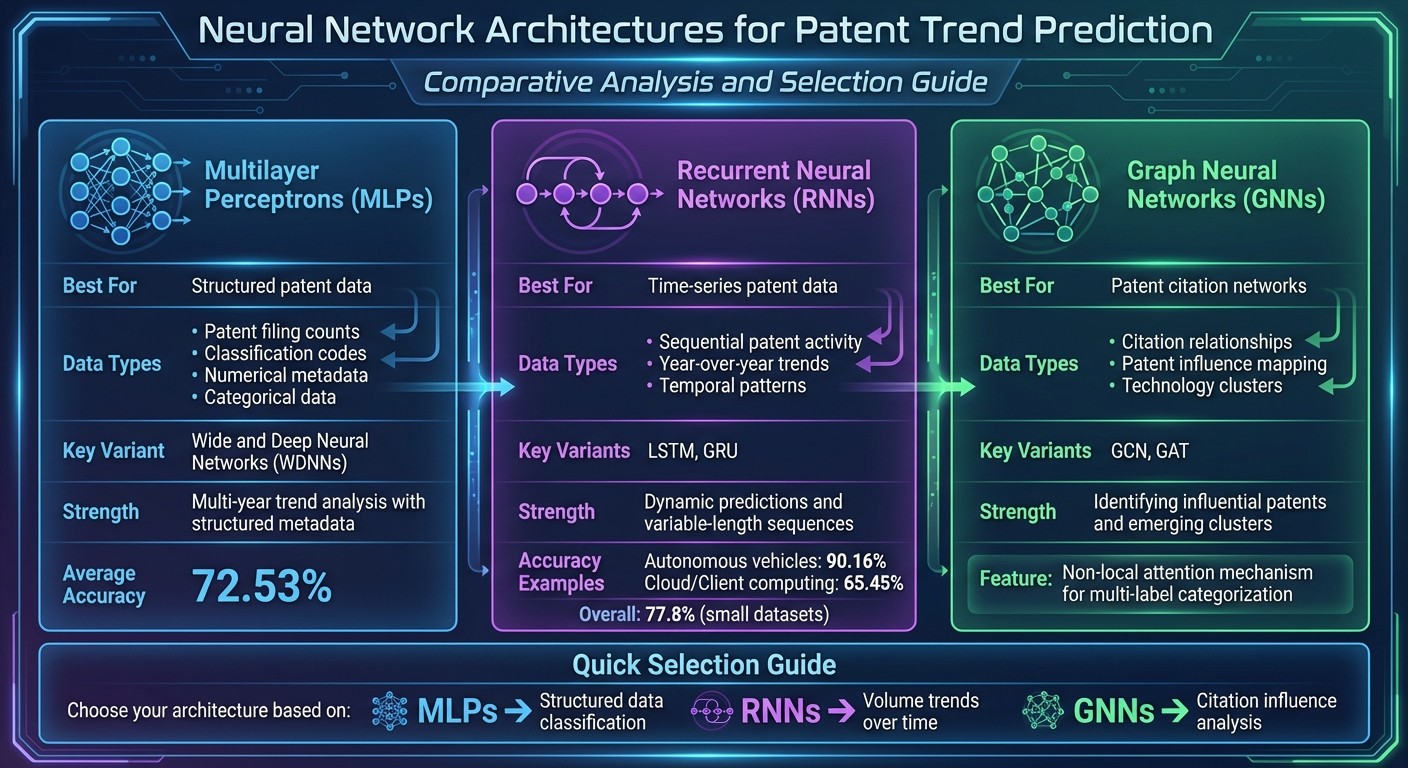
Neural Network Architectures for Patent Trend Prediction Comparison
Neural networks analyze patent data in ways tailored to different data types, making them versatile tools for predicting trends. For instance, Multilayer Perceptrons (MLPs) handle structured data like filing counts and classification codes. Recurrent Neural Networks (RNNs) excel at identifying patterns over time, tracking how patent activity changes year by year. Meanwhile, Graph Neural Networks (GNNs) map relationships between patents through citation networks, uncovering how innovations build on one another.
The choice of architecture depends on the specific prediction goal and the type of data being analyzed. Use RNNs to explore volume trends, GNNs to assess citation influence, and MLPs for structured data classification. Let’s dive deeper, starting with MLPs.
Multilayer Perceptron (MLP) Applications
MLPs are particularly effective for working with structured patent data, leveraging interconnected layers of nodes to handle both classification and regression tasks. Wide and Deep Neural Networks (WDNNs) are an extension of MLPs, combining linear and deep models to process both numerical data (e.g., annual patent counts) and categorical data (e.g., technology classifications). This dual approach allows for robust forecasting of patent trends.
For example, WDNNs can predict patent counts for 2024 and then use that prediction as input to forecast 2025. This iterative process makes MLPs well-suited for multi-year trend analysis, especially when working with structured metadata.
Recurrent Neural Networks (RNNs) and LSTMs
RNNs are designed to handle sequential data, making them ideal for tracking how patent trends evolve over time. Variants like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) further enhance this capability. These models are particularly strong in dynamic predictions, where understanding temporal patterns is key.
In a 2020 study, researchers Marie Saade, Maroun Jneid, and Imad Saleh used RNNs to forecast patent growth in areas like Cloud/Client computing and autonomous vehicles. Using USPTO data up to 2016, the RNN achieved 90.16% accuracy for autonomous vehicles and 65.45% for Cloud/Client computing, outperforming WDNNs, which averaged 72.53% accuracy.
"RNNs process sequential inputs, enabling predictions over variable-length sequences."
One of the strengths of RNN-based models is their ability to adapt to different prediction timeframes using encoder-decoder architectures. GRUs, in particular, are well-suited for smaller datasets, which is often the case when analyzing emerging technologies with limited patent histories.
Graph Neural Networks (GNNs) for Patent Citations
GNNs stand out when it comes to analyzing relationships within patent citation networks. Each patent is treated as a node, and citations are represented as directed edges connecting these nodes. This structure allows GNNs to capture how patents influence one another.
In 2019, Pingjie Tang and colleagues from the University of Notre Dame and IBM Research developed a label attention model based on Graph Convolutional Networks (GCNs) for multi-label patent categorization. Their approach integrated document-word associations and word-word co-occurrences using a non-local attention mechanism. Testing on the CIRCA patent database, their model outperformed seven competitive baselines in precision and ranking metrics.
Graph Attention Networks (GATs) take this a step further by assigning different levels of importance to neighboring patents. This helps the model focus on the most relevant citations while updating a node's representation. Through message passing across layers, nodes share and aggregate insights, making GNNs invaluable for predicting which patents are likely to become highly cited or for spotting emerging technology clusters.
Understanding these architectures is a critical step toward preparing data and extracting features that align with specific prediction goals.
Data Preparation and Feature Engineering
When working with patent data for neural networks, the first step is to establish a clear retrieval strategy. This means pinpointing which patent details - like titles, abstracts, publication numbers, application dates, and classification codes - are most relevant to your research or prediction goals. Once these details are identified, you can create retrieval formulas to filter patents that align with your focus. After gathering the data, the next step is feature selection.
Feature selection plays a pivotal role in shaping your dataset. Essential elements such as publication numbers, IPC classification codes, applicants, and publication countries form the backbone of your analysis. Beyond these basics, uncovering relationships between patents - whether through technical classifications, citation links, ownership transfers, or collaborations - can provide valuable insights for predicting trends.
When extracting features from patent texts, one effective method is to break documents into fixed-length paragraphs for independent encoding. These paragraph-level features are then combined into a document-level representation using attention mechanisms. Titles and summaries often hold the key details of an innovation, making them particularly useful for this process.
For temporal data, grouping patents into time-series snapshots based on their publication year allows you to track how patent activity evolves over time. This sequence of network states can then be analyzed using models like RNNs, LSTMs, or BiLSTMs. BiLSTMs are especially beneficial because they can capture both past and future influences on current trends.
When dealing with multimodal data - such as text, numerical features, and citation networks - it's crucial to preprocess each type carefully. This ensures that the unique characteristics of each data type are preserved while maintaining compatibility with the neural network.
Building and Training Neural Network Models
After preparing your data and extracting features, the next step is creating a neural network capable of identifying meaningful patterns within patent data. Start by integrating the patent data into a database and calculating key metrics, like annual patent counts. For tasks involving temporal predictions, construct time-series snapshots to capture the evolution of patent relationships over time.
The choice of architecture plays a crucial role. For instance, an RNN model was trained with 1,000 iterations at a learning rate of 0.001, while the WDNN model required 10,000 iterations using the same learning rate.
"RNN achieves a better performance and accuracy and outperforms the WDNN in the context of small datasets"
Model Training and Hyperparameter Optimization
Once your data is ready, the next phase involves configuring and fine-tuning your model. This includes optimizing hyperparameters like learning rate, number of iterations, batch size, and layer configurations. Proper tuning is essential to prevent overfitting or underfitting and to improve accuracy when the model encounters unseen patent data.
Automated hyperparameter tuning can significantly streamline this process, reducing the number of iterations from 99 to just 17. For predicting patent trends, experiment with training parameters and adjust configurations based on observed results. Specific optimization techniques can be employed depending on the model: Adagrad works well for Wide and Deep Neural Networks when dealing with sparse patent data, while RMSProp is more effective for Recurrent Neural Networks, helping to accelerate gradient descent during training.
Evaluation Metrics for Patent Prediction Models
To evaluate the performance of your model, use metrics specifically designed for patent forecasting. For predicting patent growth, calculate accuracy by normalizing actual and predicted patent counts to a 0–100 scale. Then, find the absolute difference between these values and subtract the mean difference from 100%. For citation trajectory predictions, rely on metrics like Mean Absolute Logarithmic Error (MALE) and Root Mean Squared Logarithmic Error (RMSLE), where lower scores indicate better performance.
In practice, the PTNS model demonstrated measurable improvements. It reduced RMSLE by approximately 0.04 for new patents, 0.14 for grown patents, and 0.18 for random patents compared to baseline models.
Applications and Integration with AI Platforms
Once you've evaluated your neural network models, the next step is to integrate them into your patent workflows. Neural networks trained on large patent datasets can categorize patents, spot emerging trends, and predict future patent activity, making the entire process more efficient.
Using Patently's AI-Powered Tools
Patently's semantic search powered by Vector AI is a game-changer for applying neural network insights to patent analysis. Unlike typical keyword searches, semantic search digs deeper, uncovering concept-level relationships between patents. This helps identify technical patterns and track emerging trends. The platform's Forward and Backward citation browser complements this by showing how patent citations evolve over time. This feature is especially useful for validating neural network predictions and fine-tuning your models.
Patently also offers analytics tools that keep you updated on patent landscapes in real time. These tools track metrics identified by your neural networks as trend indicators. For example, if your predictive model detects a rise in patent filings in a specific tech area, these analytics allow you to explore details like assignee activity, geographic trends, and filing speed. By combining these insights, you create a feedback loop that continuously improves both your search strategies and predictive models.
With these tools in place, you can start weaving predictive models directly into your day-to-day patent workflows.
Integrating Predictive Models into Patent Workflows
Taking it a step further, predictive algorithms can be integrated into daily tasks to estimate patent issuance timelines, manage portfolios, and support better decision-making. For instance, when drafting patents, trend predictions can help you craft claims that are likely to hold future relevance. Similarly, when responding to Office Actions, predicted citation patterns can strengthen arguments for novelty and non-obviousness.
However, the key to success lies in balancing automation with human expertise. While AI tools can speed up tasks like patent searches, clustering, and pattern recognition, they still need human oversight to ensure the insights are reliable. Start by defining clear business objectives - turn broad goals into specific, testable questions. Use automated classification for handling large datasets but rely on human review for critical clusters flagged by your neural network. This hybrid approach combines the efficiency of AI with the contextual judgment that only humans can provide.
Conclusion
Neural networks have reshaped how we approach patent trend prediction and portfolio management. These models are exceptional at handling tasks like data classification, regression analysis, and forecasting future trends based on historical patent data. Unlike traditional manual methods, neural networks can process massive amounts of complex patent information, uncovering patterns and insights that would otherwise remain hidden.
For instance, studies highlight that Recurrent Neural Networks (RNNs) achieve an impressive 77.8% accuracy, outperforming other models when working with smaller datasets. When it comes to forecasting forward patent citations, deep learning techniques consistently surpass traditional approaches like citation-lag distribution and Tobit regression. The inclusion of ex-post data further boosts their accuracy, proving the reliability of neural networks in patent forecasting tasks.
Patently offers tools that take this technology even further. Its semantic search, powered by Vector AI, moves beyond simple keyword matching to grasp concept-level relationships between patents. Paired with real-time analytics that monitor changes in the patent landscape and a Forward and Backward citation browser for validating predictions, it delivers a robust ecosystem for leveraging neural network-driven insights in practical patent work.
The real takeaway lies in striking the right balance. Neural networks can significantly enhance efficiency in patent searches, clustering, and pattern recognition. However, their full potential is realized when combined with human expertise. By setting clear objectives, using automated classification for large-scale data, and reserving critical decision-making for human judgment, organizations can harness the best of both worlds.
FAQs
How do neural networks enhance patent trend predictions compared to traditional methods?
Neural networks have transformed how we predict patent trends by uncovering intricate, non-linear patterns that traditional models often miss. These advanced systems can handle a wide range of complex, high-dimensional data - like citation trajectories, geographic information, and topic-specific insights - to produce forecasts that are far more detailed and accurate.
Take their ability to track temporal changes and variable relationships, for example. Neural networks can predict forward patent citations and identify emerging technology clusters with a level of precision that sets them apart. By leveraging these cutting-edge AI tools, Patently equips patent professionals to spot significant trends, anticipate where innovation is headed, and make smarter, data-driven decisions - leaving conventional methods in the dust.
How do different neural network architectures enhance patent trend analysis?
Neural network architectures have transformed patent trend analysis, offering much more than just basic keyword searches. Take variational autoencoders (VAEs), for instance - they generate dense vector embeddings from patent text. This allows for visualizing technology landscapes and comparing intellectual property portfolios in a way that’s far more intuitive and insightful. Similarly, recurrent neural networks (RNNs) shine when working with sequential data like patent filing histories. They’re particularly effective at predicting technology trends, even when the available data is limited. On the other hand, attention-based models excel at summarizing entire patent documents, making them highly accurate for multi-label classification tasks.
Another game-changer is the combination of generative adversarial networks (GANs) with supervised classifiers. By augmenting datasets with GANs, analysts can work around the issue of limited labeled patent data, leading to better predictions of emerging technologies. Platforms like Patently leverage these cutting-edge tools - such as RNN-driven trend models and VAE-powered semantic embeddings - to provide U.S. patent professionals with tailored, actionable insights.
How can businesses use neural networks to improve patent trend forecasting?
Businesses can tap into the power of neural networks to improve patent trend forecasting by weaving AI-driven predictions into their operational processes. These networks dig into historical patent data - like titles, abstracts, claims, and citation patterns - to forecast future trends, such as shifts in filing volumes, technology advancements, and citation patterns. Armed with these insights, teams can make smarter decisions at every stage of the patent lifecycle.
Take this as an example: an AI model can sift through patent data, make predictions, and seamlessly integrate the results into platforms like Patently. With this setup, users can filter portfolios based on growth potential, focus on high-impact inventions, and get alerts about strategic opportunities. Automating these steps gives businesses a real-time innovation radar, helping them fine-tune their filing strategies, allocate resources efficiently, and stay ahead in competitive analysis.
To keep predictions sharp, companies can feed real-world outcomes - like patent approvals or litigation events - back into the model. This feedback loop ensures the AI adapts to changing market conditions, enabling a forward-thinking, data-driven approach to managing patents.