Standardized IP Data Formats for SEP Analytics
Intellectual Property Management
Dec 17, 2025
Standardized IP formats unify SSO declarations, patent records, and litigation to speed SEP essentiality scoring, licensing decisions, and U.S.-focused analytics.

Standardized IP data formats simplify the complex world of Standard-Essential Patents (SEPs) by unifying fragmented data sources like SSO declarations, patent office records, and litigation details. This approach helps patent professionals streamline tasks such as portfolio valuation, licensing negotiations, and essentiality scoring. Here's why it matters:
Challenges with SEP Data: Inconsistent formats, over-declaration, and disconnected records make analysis time-consuming and error-prone.
Solution: Standardized schemas, normalized fields (e.g., patent numbers, company names), and machine-readable formats (e.g., JSON, XML) integrate data into a single, reliable framework.
Benefits: Faster insights, reduced errors, and AI-ready datasets for predicting essentiality, benchmarking portfolios, and modeling licensing scenarios.
For U.S.-based teams, this means less manual work, improved decision-making, and stronger outcomes in licensing and litigation. Platforms like Patently leverage standardized data to deliver actionable analytics, enabling professionals to focus on strategy rather than cleanup.
Core Elements of Standardized IP Data for SEP Analytics
Key Entities and Identifiers for Standardization
To build a reliable foundation for SEP analytics, it’s essential to start with consistent representation of core entities. Patent families play a pivotal role here, grouping equivalent patents from different jurisdictions - like a U.S. patent paired with its European counterpart or national phases - using identifiers such as INPADOC or DOCDB families. This grouping avoids double-counting when the same invention is declared multiple times across various patent offices. For instance, if an SSO declaration lists the same invention under different patent numbers or jurisdictions, family IDs ensure accurate deduplication. A practical example: Nokia's active 5G SEP portfolio for RAN 1 in the U.S. includes 385 active patents organized into 338 simple families.
Corporate name normalization is another crucial step. By employing AI-driven tools for entity resolution, variations like "Qualcomm Inc." and "Qualcomm Incorporated" can be merged into a single entity. This process also accounts for historical name changes, subsidiaries, and ownership shifts due to mergers or acquisitions - key for U.S. teams tracking corporate restructuring. Similarly, standardizing SSO-specific data elements, such as declaration IDs, standard release versions (e.g., 5G NR Rel-15), technical specification references (e.g., 3GPP TS 38.211), declaration dates, and essentiality status, ensures uniformity across records.
Jurisdictional harmonization is another layer of standardization. This involves converting local patent numbers into international formats (e.g., transforming CN202310123456 into its WO equivalent) and aligning grant statuses across patent offices like the USPTO, EPO, and CNIPA. For teams focused on U.S. operations, prioritizing USPTO data while maintaining visibility into global equivalents ensures accurate counts of enforceable rights. These measures lay the groundwork for unifying fragmented datasets into a cohesive whole.
Standardization Operations and Processes
Transforming fragmented data into a standardized format often starts with parsing unstructured sources, such as SSO PDFs or inconsistent XML files. OCR technology can digitize scanned documents, while regex tools extract patent numbers and link declarations to their corresponding metadata.
Patent numbers themselves are standardized (e.g., converting US-2023-0123456 into a consistent format) to enable reliable matching. Standards references are aligned to map patent claims to specific sections of technical specifications, producing metrics like "TS Relevancy" and "Claim Scope Support." These scores help predict essentiality and address over-declaration by pinpointing which patents align most closely with the relevant standards.
Benefits of Standardized Data for AI-Driven Analytics
Once data is standardized, it becomes a powerful resource for advanced AI analytics. Clean, consistent datasets enable tools like Patently to leverage Vector AI for semantic search, allowing precise retrieval of patents based on technical concepts rather than just keywords. This approach also enhances essentiality scoring, as AI models trained on normalized claims and technical specifications can more effectively filter out irrelevant or over-declared patents.
For example, Clarivate experts analyzed over 70,000 SEPs spanning technologies like 4G, 5G, Wi‑Fi 6, video codecs, and EV charging using these standardized methods. The resulting insights significantly improve tasks like competitor benchmarking, identifying high-value SEPs, and modeling licensing scenarios. Tools such as SEP OmniLytics integrate metrics like TS Relevancy and Claim Scope Support to rank essentiality, offering a multidimensional view of SEPs, pooled patents, litigation data, and standards contributions. For U.S. teams involved in licensing negotiations or litigation preparation, this streamlined data means less time spent reconciling inconsistencies and more time making informed, analytics-driven decisions.
Case Study: Harmonizing SSO Declarations and Patent Office Data
Initial Data Challenges
A leading telecommunications company faced a daunting task: analyzing its 5G and Wi-Fi 6 SEP portfolio across ETSI and IEEE declarations from 2010 to 2024. The data itself posed a significant challenge. ETSI declarations came in inconsistent CSV and XML formats, while IEEE relied on web forms and PDFs - some of which were scanned and required OCR just to extract basic details. The patent identifiers were equally messy, ranging from application numbers to truncated formats, demanding extensive manual cleanup to align with USPTO records.
Corporate names added another layer of complexity. The same company appeared under variations like "Qualcomm Inc.", "Qualcomm Incorporated", and even subsidiary names across different SSO databases and patent registries. Without a unified party identifier, consolidating portfolio data or comparing competitor positions was nearly impossible. Making matters worse, SSO data lacked any connection to legal status. Analysts had no way to determine whether declared assets were granted, expired, or abandoned without conducting separate searches through the USPTO, EPO, and CNIPA.
Manual efforts to reconcile these records were time-consuming and unreliable. Teams spent weeks writing scripts to clean up data, only for those scripts to fail when new data dumps introduced unexpected formats. Over-declaration further muddied the waters, making it hard to pinpoint enforceable U.S. patents. This fragmentation slowed analytics, made them unreliable, and rendered large-scale licensing and litigation preparation impractical.
These hurdles highlighted the pressing need for a standardized approach to managing this data.
Standardization Process
To tackle these issues, the team developed a multi-step data standardization pipeline. First, they used custom parsers and OCR tools to pull metadata, patent numbers, and standard references from ETSI, IEEE, and other SSO sources into a staging area. From there, patent number normalization began. This involved applying rule-based transformations to fix missing country codes, remove formatting errors, correct common transposition mistakes, and map local SSO formats to standardized USPTO and EPO formats.
For corporate names, the team employed fuzzy matching, corporate hierarchy data, and mapping tables to harmonize assignee names across databases. Declarations were then linked to patent office records through a two-step process: deterministic matching for normalized numbers and probabilistic matching - using details like priority dates and applicants - for ambiguous cases. Standards references were also mapped to a structured taxonomy (e.g., converting "5G NR, Rel-15" into a controlled identifier), allowing for consistent aggregation across SSOs.
Quality checks ensured accuracy. Any unmatched or conflicting records were flagged for expert review, and the resulting corrections were fed back into the normalization rules and mapping tables. This iterative process boosted match rates from an initial 60–70% with raw SSO data to over 90–95%, with any remaining uncertainties clearly labeled.
Results and Insights
The standardization process revolutionized the team's ability to analyze their data. Analysts could now generate detailed cross-tabs of declared 5G SEPs, breaking them down by assignee, U.S. grant status, and 3GPP release - all in a single query. For the first time, they could identify which competitors held the most active U.S. rights for specific standards. They could also categorize declaration counts into granted versus pending, U.S. versus non-U.S., and single versus multi-family groups, providing a clear picture of enforceable rights.
For portfolio owners, this unified view uncovered hidden opportunities. Previously overlooked granted family members in the U.S., derived from older or incomplete declarations, were identified as potential candidates for licensing or enforcement. U.S. counsel and licensing teams further enriched their strategies by correlating the harmonized SEP dataset with U.S. litigation and PTAB data. This helped pinpoint declared families with contested validity or heavy assertion histories, sharpening valuation and negotiation efforts.
The harmonized dataset also delivered a continuous, portfolio-level dashboard. Rights holders could monitor declared SEPs, their global families, and U.S. status all in one place. They could track which ETSI or IEEE families had matured into granted U.S. patents, segment assets by lifecycle stage (e.g., pending, granted, near-expiry), and link active U.S. SEPs to deployed standards in devices and infrastructure. This streamlined royalty forecasting and enforcement planning, offering realistic estimates of royalty bases and licensing ranges - all backed by standardized, reliable data that eliminated weeks of manual work.
GSLC Tim Pohlmann Welcome Remarks - SEP determination using AI
Case Study: Semantics-Based SEP Essentiality Scoring
This case study dives into how AI-driven semantic matching refines essentiality scoring, building on earlier insights into standardized data.
Challenges in Essentiality Scoring
A prominent U.S. semiconductor company encountered a familiar issue: over-declaration. Their 5G portfolio contained thousands of declared SEPs, but it was unclear which patents were genuinely essential to the standard. ETSI's IPR Policy encourages broad declarations to avoid overlooking potentially essential patents, but this often results in noisy datasets where many declared SEPs lack true essentiality. The company needed a way to pinpoint their most valuable SEPs for licensing and enforcement.
The complexity of the data made this task even harder. Standards documents were scattered across various technical specifications, each with multiple versions and inconsistent terminology. Meanwhile, patent documents included independent claims, dependent claims, and detailed descriptions across continuations and divisionals. Without a solid method to link specific patent claims to corresponding standard clauses, manual claim charting became an expensive and time-consuming endeavor. These hurdles highlighted the need for a standardized semantic pipeline to systematically connect patent claims with technical specifications.
How Standardized Data Improves Essentiality Scoring
To tackle these challenges, the team built a standardized data pipeline powered by AI semantic matching. They started by normalizing patent text, tagging independent and dependent claims, and breaking down key sections of descriptions. Standards documents were segmented into granular units - like clauses, subclauses, and figures - and technical terminology was unified across different document versions.
Metadata harmonization played a crucial role. Fields such as technology generation (e.g., LTE, 5G NR, Wi-Fi 6), working group, release number, and date were standardized. This alignment allowed the AI model to differentiate features accurately, such as distinguishing a 5G RAN1 radio feature from a 5G core feature in both patents and technical specifications. This consistency enabled the semantic model to make precise comparisons.
Expert mappings provided high-quality training labels. Standardized linkage data was then used to create "hard negatives", such as patents from unrelated technology areas or standards releases that predated a patent's priority date. Preliminary keyword mapping and Claim Scope Support scores helped assign coarse essentiality labels (e.g., high, medium, or low essentiality likelihood) to patents without full claim charts.
One analysis of Nokia's 5G SEP portfolio for RAN 1 in the U.S. applied this method to rank 385 active patents across 338 simple families. The semantic model identified subgroups with high Claim Scope Support but only partial TS Relevancy, allowing the team to focus on targeted essentiality reviews. This approach filtered out noise and highlighted the most promising SEPs for enforcement.
This streamlined process laid the groundwork for actionable workflows, which are explored further in the next section.
Applications of Essentiality Scoring
The essentiality scores enabled repeatable workflows built on the data harmonization processes described earlier. For portfolio prioritization, the U.S. patent owner ranked patent families by combining essentiality scores with factors like grant status, U.S. coverage, and remaining term. This strategy directed claim-charting and continuation efforts toward the most valuable SEPs, minimizing wasted resources on lower-priority families.
In outbound licensing, high-scoring patents - those aligned with specific standards or releases implemented in target products - were bundled into licensing programs. These programs leveraged explainable AI evidence, such as top-matching clauses, similarity scores, and links to expert mappings in the standardized dataset. This transparency helped streamline and accelerate negotiation processes.
During FRAND discussions, both parties relied on comparable metrics, such as the number of high- and medium-essentiality families per standard, jurisdiction (including U.S. grants), and product feature. Unlike inflated raw declaration counts, semantic scores based on standardized mappings provided clear, claim-level narratives. These narratives detailed which specific clauses and features a portfolio covered and how it stacked up against competitors. Every score and mapping was traceable to stable identifiers and expert-reviewed samples, ensuring that the evidence could hold up under scrutiny from opposing experts and courts.
Platforms like Patently integrate these workflows into dashboards and deal pipelines tailored for U.S.-based teams. These tools allow users to monitor essentiality-weighted portfolio strength, track their share of a standard across successive releases, and benchmark against competitors. All of this is powered by standardized data, eliminating the need for weeks of manual reconciliation.
Implementation Considerations for Standardized IP Data
Fragmented vs Standardized SEP Data: Impact on Analytics Performance
Data Governance and Quality Assurance
To ensure accuracy and reliability, start by establishing a clear data governance framework. This should include a formal charter and defined RACI matrices that outline responsibilities across legal, IP analytics, and IT teams. Schedule quarterly meetings to review updates from standards organizations, policy changes, and any corporate developments.
Regular data normalization is critical. Use standardized dictionaries to unify assignee and inventor names, and update legal statuses monthly - or weekly for high-priority technologies. Track corporate groupings by monitoring parent entities and historical mergers or acquisitions to ensure Standard Essential Patent (SEP) counts reflect current ownership. Automated rules can help flag inconsistencies, such as overlapping grant dates or duplicate declarations, while periodic human audits catch errors that automation might overlook.
Maintain a detailed change log for standards updates, policy revisions, and significant judicial rulings. This ensures your data stays current while preserving historical context. Your data model should also include versioned links between patents and specific standards documents. This way, when a standard is revised, related mappings and essentiality assessments can be updated seamlessly. For corporate groupings, algorithmic checks can identify anomalies - like sudden spikes in SEP counts or mismatches between declarations and patent office data - while expert reviews validate ownership after mergers or acquisitions and confirm licensing rights for declared SEPs.
Once governance and quality assurance are in place, technical systems must adapt to U.S. reporting needs.
Technical Customization for U.S.-Based Teams
For teams operating in the U.S., data systems should align with local conventions while maintaining global applicability. Store dates in the ISO format but display them as MM/DD/YYYY in U.S. reports. Similarly, monetary values should be shown in U.S. dollars ($), with conversion timestamps included when necessary. Ensure compatibility with both imperial and metric units, so technical standards remain traceable.
It's also essential to capture U.S.-specific legal events. This includes tracking proceedings from the Patent Trial and Appeal Board (PTAB), investigations by the International Trade Commission (ITC), and federal court litigation milestones. These events should be linked to SEP families and standards to support risk assessments and valuation analyses. To streamline updates, integrate a standardized SEP repository via APIs with core IP systems. This enables automatic updates for declarations, legal changes, and corporate groupings. Key attributes like essentiality scores and standard mappings should be easily accessible through user-friendly dashboards. Platforms such as Patently can serve as the front end, leveraging standardized SEP data as the backend source.
With these technical customizations in place, the advantages of standardized data over fragmented approaches become evident.
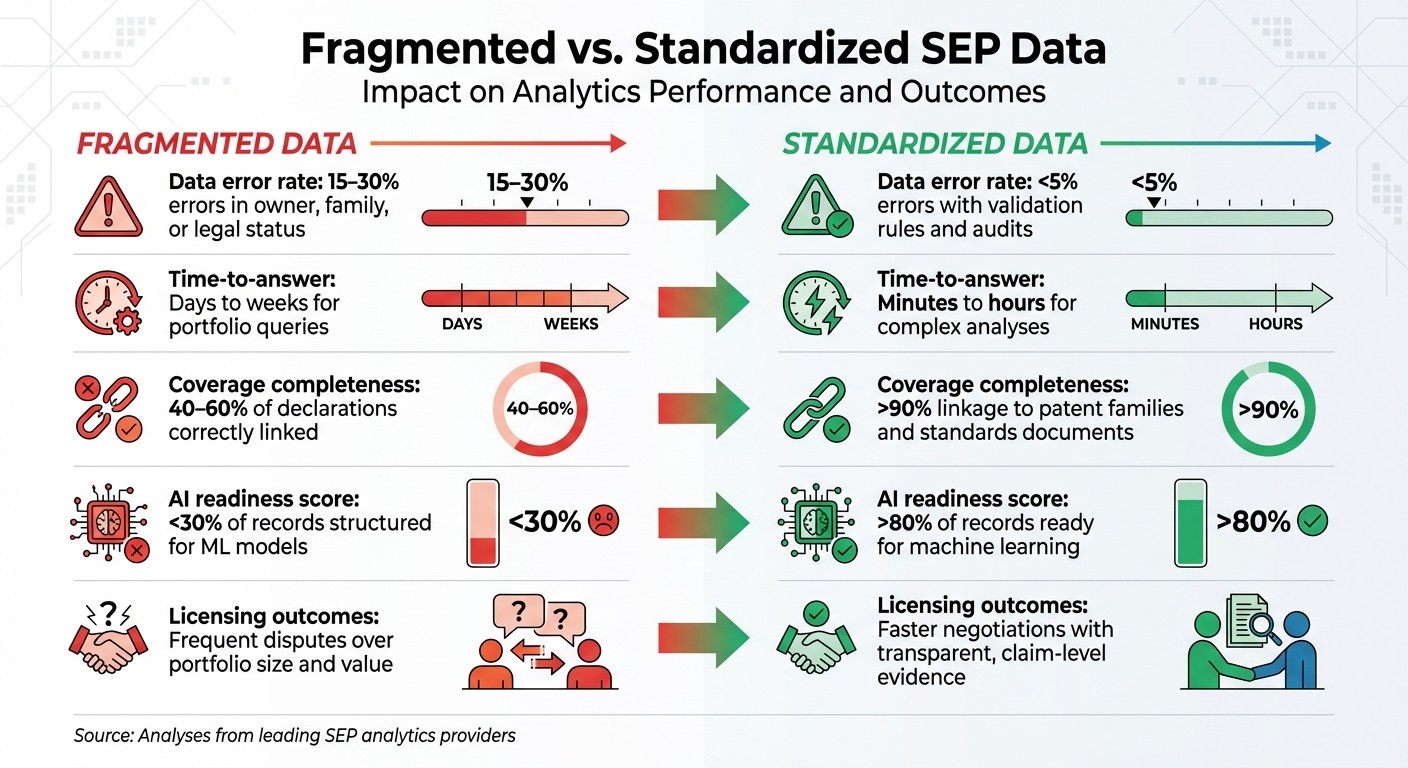
Comparing Fragmented vs. Standardized Data
Fragmented SEP data often leads to issues like double-counting, misattributions, and incorrect legal statuses. These problems usually require manual consolidation, often through spreadsheets, which increases error rates and limits the depth of analysis. Such setups tend to focus on basic counts rather than deeper insights like essentiality, enforceability, or economic value.
On the other hand, standardized datasets create a unified view by linking patents, standards organization data, litigation records, and licensing information. This enables advanced analytics, such as essentiality scoring, technical relevance assessments, and rankings based on claim scope. Improved data governance and tailored systems reduce errors and make the data more suitable for AI-driven models. This type of normalized, interconnected data supports predictive analytics for essentiality, portfolio valuation, and counterparty risk assessment.
Here’s a comparison to illustrate the impact:
Metric | Fragmented Data | Standardized Data |
|---|---|---|
Data error rate | 15–30% errors in owner, family, or legal status | <5% errors with validation rules and audits |
Time-to-answer | Days to weeks for portfolio queries | Minutes to hours for complex analyses |
Coverage completeness | 40–60% of declarations correctly linked | >90% linkage to patent families and standards documents |
AI readiness score | <30% of records structured for ML models | >80% of records ready for machine learning |
Licensing outcomes | Frequent disputes over portfolio size and value | Faster negotiations with transparent, claim-level evidence |
Source: Analyses from leading SEP analytics providers.
Conclusion
Standardized IP data formats have transformed SEP analytics, shifting them from tedious manual processes to streamlined, data-driven strategies. By unifying patent office records, SSO declarations, standards documents, litigation data, and licensing information through consistent identifiers and normalized metadata, U.S.-based teams gain a reliable framework for precise portfolio valuations, effective licensing negotiations, and sharper competitive positioning.
The business benefits are clear. Companies adopting standardized data see marked improvements in data accuracy and operational efficiency. These enhancements lead to stronger licensing outcomes, backed by transparent, claim-level evidence rather than contested portfolio counts. For industries like 4G/5G, Wi‑Fi, codecs, and EV charging, standardized data supports critical tasks - tracking declared versus enforceable SEPs, verifying corporate ownership, and ensuring comprehensive geographic coverage - all essential for FRAND-aligned rate discussions.
With standardized data, advanced analytics become possible. Teams can conduct robust SEP landscaping and benchmarking, assess essentiality and strength using semantic similarity tools and claim chart evidence, apply dynamic over-declaration filters, and simulate portfolio revenues under various licensing scenarios - capabilities far beyond the scope of fragmented spreadsheets. These insights integrate seamlessly with workflow automation, boosting efficiency across the board.
Platforms like Patently take this a step further by embedding standardized SEP data into powerful, integrated workflows. Features like AI-assisted drafting tailored to specific standards, semantic search via Vector AI to map patents to standard sections, and SEP analytics modules that measure portfolio metrics and essentiality indicators empower U.S.-based teams to act decisively. Whether selecting patents for negotiations, prioritizing continuations, or identifying coverage gaps, these tools eliminate the need for manual data normalization. The result? A repeatable, strategic SEP capability that drives smarter decisions across legal, R&D, and business operations.
FAQs
How do standardized IP data formats benefit SEP analytics?
Standardized IP data formats play a crucial role in organizing and analyzing information related to Standard-Essential Patents (SEPs). By maintaining consistent data accuracy and structure, these formats simplify the process of evaluating ownership, geographic distribution, and the technological scope of SEPs.
This consistency leads to more dependable insights into SEP portfolios, enabling stakeholders to spot trends, assess the essentiality of patents, and craft well-informed licensing strategies. In essence, standardized formats improve the accuracy and efficiency of SEP analysis, paving the way for smarter decisions for both licensors and licensees.
What problems arise when SEP data isn't standardized?
When SEP data isn't standardized, businesses face a range of obstacles. For starters, pinpointing patent ownership and determining geographic coverage becomes a challenge, leading to unclear insights and complicating decision-making processes. Evaluating patent essentiality also turns into a more intricate task, heightening the chances of disputes and inefficiencies during licensing talks.
On top of that, inconsistent data formats can undermine the reliability of analytics, making it tougher to craft effective strategies and handle licensing workflows. Clear and standardized data is key to minimizing risks, ensuring transparency, and streamlining SEP analytics operations.
How does AI improve essentiality scoring for standard-essential patents (SEPs)?
AI plays a crucial role in assessing the importance of Standard Essential Patents (SEPs) by processing vast amounts of patent data quickly and with precision. It examines factors like patent ownership, geographic coverage, and relevance to specific technologies, offering a clearer picture of a patent’s significance and essentiality.
This analytical approach empowers stakeholders to make smarter decisions, simplify licensing discussions, and pinpoint critical patents tied to particular standards. By incorporating AI, the process becomes faster and more precise, ultimately saving time and delivering better results.