Patent Clustering Metrics: Precision, Recall, F1
Intellectual Property Management
Feb 18, 2026
Clear guide to precision, recall and F1 in patent clustering—definitions, trade-offs, examples and when to prioritize each metric for legal and research use.

Patent clustering organizes patents into groups based on shared features, helping with tasks like searches, classification, and innovation tracking. To measure how well these groups are formed, three key metrics are used:
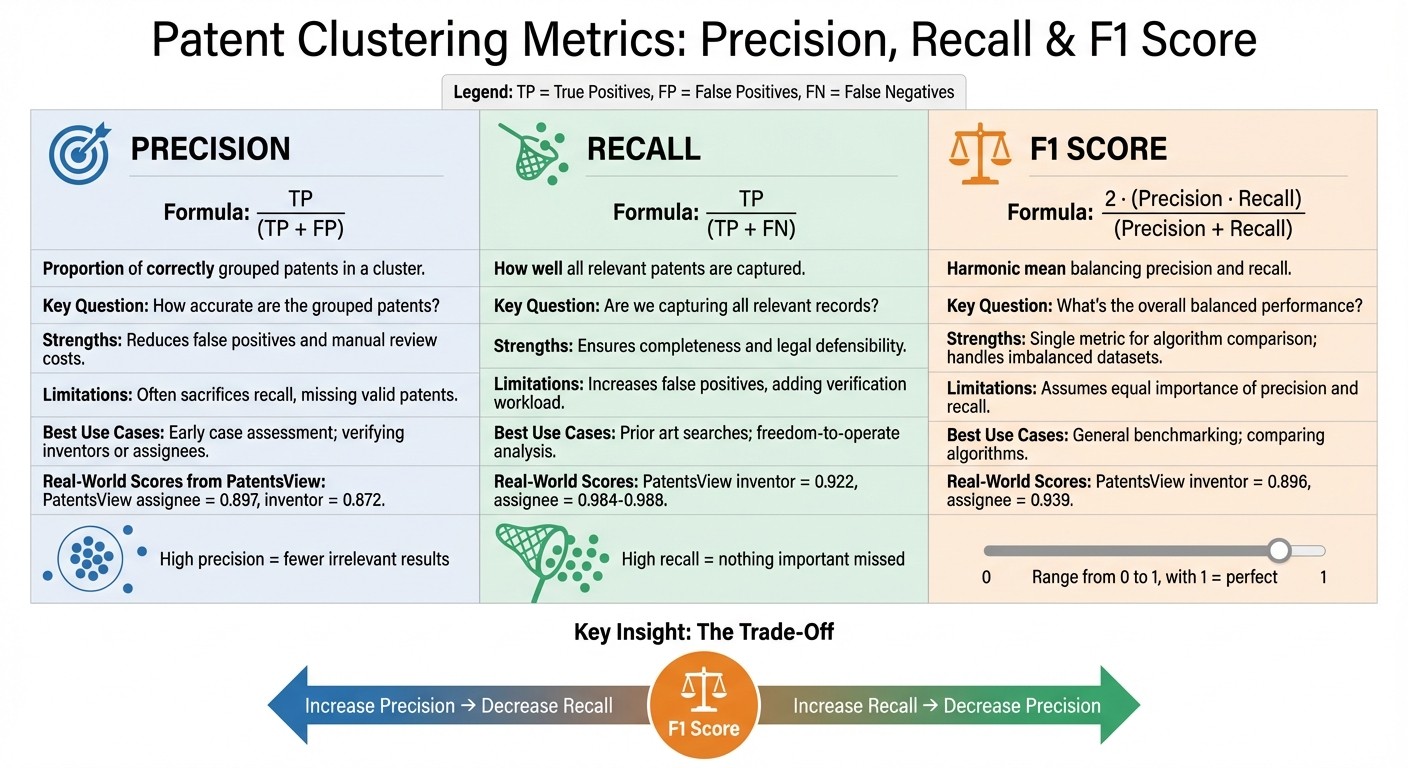
Precision: Measures accuracy by calculating the proportion of correctly grouped patents. High precision reduces irrelevant results but may leave out some relevant ones.
Recall: Focuses on completeness by identifying all relevant patents. High recall ensures nothing important is missed but may include unrelated patents.
F1 Score: Balances precision and recall, offering a single value to evaluate performance. It's useful for comparing algorithms but assumes equal importance for precision and recall.
Each metric has strengths and trade-offs, making them suitable for different tasks like legal research, prior art searches using top patent tools, or algorithm benchmarking.
Patent Clustering Metrics: Precision vs Recall vs F1 Score Comparison
1. Precision
Definition
Precision refers to the proportion of correctly grouped patent records within a specific cluster. It’s calculated using the formula:
Precision = TP / (TP + FP)
Here, TP (True Positives) represents patents correctly grouped together, while FP (False Positives) refers to patents incorrectly included in the cluster. A high precision score indicates that the patents grouped together are genuinely related.
Importance in Patent Clustering
Precision plays a key role in minimizing review costs. When precision is low, reviewers have to sift through a flood of irrelevant patents, leading to increased time and expenses. For tasks like patent entity disambiguation - determining which patents belong to the same inventor or assignee - high precision is critical to avoid false merges. For example, as of September 30, 2025, the PatentsView assignee disambiguation algorithm achieved a precision score of 0.897, while the inventor algorithm scored 0.872.
Strengths and Weaknesses
The main advantage of precision is its ability to ensure cluster accuracy, which is particularly valuable in high-stakes scenarios like litigation or e-discovery, where false positives can be costly. However, there’s a trade-off: focusing on high precision often makes clustering algorithms more cautious, grouping records only when there’s near-certainty of a match. This conservative approach can leave out valid patents that should be included. Moreover, in datasets where relevant patents are rare, precision can become unstable and less meaningful if evaluated in isolation. Balancing accuracy with inclusivity is a constant challenge.
Real-World Applications
In legal fields such as e-discovery, high precision is essential for making informed decisions early in the review process. Monitoring precision also acts as a safeguard against algorithmic errors. For instance, it helps teams quickly identify issues like cluster merging mistakes or classification drift, ensuring that workflows remain efficient and reliable. This makes precision a critical metric for maintaining the quality and cost-effectiveness of patent analysis.
Mastering precision provides a foundation for understanding other metrics like recall and the F1 score in patent clustering.
2. Recall
Definition
Recall measures how well relevant patent records are captured within a cluster. The formula is:
Recall = TP / (TP + FN)
Here, TP (True Positives) represents patents that are correctly grouped together, while FN (False Negatives) refers to patents that should have been included but were left out. Essentially, recall answers the question: "Are we capturing all the relevant records?"
Importance in Patent Clustering
Recall plays a critical role in research and litigation, where missing even a single relevant patent can lead to significant consequences. For tasks like entity disambiguation, high recall ensures that all patents linked to the same inventor or assignee are grouped together, avoiding fragmented portfolios. This makes recall a vital complement to precision, ensuring clusters are not only accurate but also comprehensive. Between September 2024 and September 2025, PatentsView's inventor disambiguation achieved a recall rate of 0.922, while assignee disambiguation reached impressive rates ranging from 0.984 to 0.988.
Strengths and Weaknesses
Recall is particularly valuable in scenarios where missing relevant data is costly, such as legal or technical research. It is especially effective for imbalanced datasets, where relevant patents form only a small portion of the total. However, recall can be misleading if over-clustering is used to boost the metric artificially. In such cases, while recall might hit 100%, precision suffers because unrelated records are grouped together . This reflects a trade-off: increasing recall often leads to a drop in precision, as capturing more relevant records can also pull in incorrect ones.
Real-World Applications
In e-discovery, recall is prioritized because legal teams aim to retrieve almost all responsive documents, not just a select few. For example, on March 31, 2025, a bug in PatentsView's codebase caused assignee precision to plummet to 0.428, even though recall stayed high at 0.988. This highlights an important point: high recall alone doesn’t guarantee high-quality clusters. It merely shows that the algorithm is capturing relevant records, even if unrelated ones slip in. To maintain effective patent analysis workflows, recall must be monitored alongside other metrics to balance completeness with accuracy. These considerations naturally transition into discussing the F1 Score, which evaluates the balance between precision and recall.
3. F1 Score
Definition
The F1 score is a metric that combines precision and recall into a single value, calculated as the harmonic mean of the two. Its formula is:
F1 = 2 · (Precision · Recall) / (Precision + Recall)
This score relies on True Positives (TP), False Positives (FP), and False Negatives (FN). It ranges from 0 to 1, with 1 representing perfect precision and recall. The harmonic mean is particularly sensitive to low values - so if either precision or recall is near zero, the F1 score will also be low. This makes it a helpful metric for ensuring balanced performance in various patent analysis tasks.
Importance in Patent Clustering
Precision and recall often pull in opposite directions, and the F1 score helps balance this tension. It prevents clusters from being too broad (low precision) or too fragmented (low recall). By doing so, the F1 score ensures that models capture relevant patents while minimizing irrelevant ones.
For instance, in September 2025, the F1 score for inventor disambiguation reached 0.896, while assignee disambiguation achieved 0.939. These metrics highlight how the F1 score reflects both accuracy and breadth in clustering efforts.
Strengths and Weaknesses
The F1 score is particularly useful for datasets where relevant patents are a small fraction of the total. Unlike simple accuracy - which can appear high when the majority class dominates - F1 measures performance across both positive and negative cases. It also provides a straightforward way to compare different clustering methods.
However, the F1 score has limitations. It assumes equal importance for precision and recall, which might not suit every context. For example, in legal e-discovery, missing a relevant document could be far costlier than reviewing an irrelevant one, but the F1 score treats both errors equally. Additionally, it ignores True Negatives (TN), meaning the score remains unchanged even if the number of correctly excluded irrelevant documents varies.
"The F1 score is a much more comprehensive evaluation metric in comparison [to accuracy] since it maximizes two competing objectives - the precision and recall scores - simultaneously."
Rohit Kundu, Ph.D. Researcher, University of California, Riverside
Real-World Applications
The F1 score has proven its utility in real-world scenarios. For example, in March 2025, a bug in PatentsView caused large clusters in the assignee dataset to merge incorrectly. This reduced precision from 0.897 to 0.428, driving the F1 score down from 0.939 to 0.602. The sharp drop flagged the issue, which was resolved by June 2025, restoring the F1 score to 0.949.
When specific trade-offs between precision and recall are needed, the F-beta score offers a tailored approach. For instance, the F2 score prioritizes recall over precision, which is especially useful in scenarios like legal e-discovery, where missing a relevant document is more problematic than reviewing an irrelevant one. This flexibility makes F-beta scores valuable when error costs vary.
Precision, recall and F1-score
Comparing Strengths and Weaknesses
When examining the strengths and weaknesses of different metrics in patent clustering, it's clear that each serves a specific role. By understanding their trade-offs, you can make better decisions about which metric to prioritize based on your goals. For instance, precision is excellent at reducing false positives, ensuring that the groupings are accurate. This directly cuts down on the time and cost of manual expert reviews. However, the downside is that focusing too much on precision often lowers recall, which means some valid patents might get left out of the cluster.
On the flip side, recall prioritizes finding all relevant patents, which is crucial for comprehensive searches and legal defensibility. But the trade-off here is an increase in false positives, which can lead to more time spent on verification. This highlights a fundamental tension: improving one metric often comes at the expense of the other.
The F1 score tries to balance this by combining precision and recall into a single value using a harmonic mean. It's particularly useful for comparing algorithms, especially when dealing with imbalanced datasets where relevant patents are scarce. However, it assumes that precision and recall are equally important, which isn't always the case. For example, in legal scenarios like e-discovery, missing a relevant patent could be far more damaging than reviewing a few irrelevant ones.
Metric | Primary Strength | Primary Limitation | Best Use Case |
|---|---|---|---|
Precision | Reduces false positives and cuts manual review costs | Often sacrifices recall, missing valid patents | Early case assessment; verifying inventors or assignees |
Recall | Ensures completeness and legal defensibility | Increases false positives, adding to the verification workload | Prior art searches; freedom-to-operate analysis |
F1 Score | Offers a balanced metric for algorithm comparison | Assumes equal importance of precision and recall, which may not align with specific goals | General benchmarking; handling imbalanced datasets |
Conclusion
When assessing patent clustering metrics, it's important to align your choice with the specific demands of your task. Precision becomes critical in scenarios where errors carry a high cost, such as verifying inventor or assignee records. In these cases, ensuring that grouped patents genuinely belong together helps avoid costly mistakes. As Acccumulation on Data Science Stack Exchange pointed out, "Precision will be more important than recall when the cost of acting is high, but the cost of not acting is low".
On the other hand, Recall takes priority in tasks where missing relevant patents could lead to legal or financial consequences. For example, in prior art searches or freedom-to-operate analyses, capturing all relevant patents is more important than the extra effort required to review additional documents.
The F1 score, which balances precision and recall, is particularly helpful for comparing algorithms or working with imbalanced datasets. However, keep in mind that its equal weighting of both metrics might not align with the specific economic considerations of your project. Each metric plays a distinct role in tackling the diverse challenges of patent evaluation, and understanding these roles is key to making informed decisions.
FAQs
How do I choose between precision and recall for my patent task?
When deciding between precision and recall, it all comes down to your specific objectives. Precision prioritizes accuracy by reducing false positives, making it the go-to choice when avoiding irrelevant patents is critical. On the other hand, recall aims to capture all relevant patents, even if it means including some irrelevant ones - this is especially important for tasks like prior art searches. If you need a middle ground, the F1 score offers a way to balance both metrics effectively.
What’s a good way to set the right clustering threshold?
To determine the appropriate clustering threshold, take a systematic approach by examining clustering validation indices and how they apply to your specific use case. Studies indicate that combining these indices with automated threshold estimation methods - especially those that optimize certain metrics - can lead to more dependable results. This combination ensures that thresholds are not only grounded in theory but also customized to fit your requirements.
When should I use F1 vs an F-beta score?
When you need a balanced metric that considers both precision and recall, F1 is the go-to choice. This is particularly useful in scenarios with class imbalance, where one class significantly outweighs the other. On the other hand, F-beta provides flexibility if your focus leans more toward one metric over the other. Use it to emphasize precision when β < 1 or recall when β > 1, depending on the specific objectives of your patent clustering model.