How to Choose a Patent Quality Scoring System
Intellectual Property Management
Jun 14, 2026
Match scoring models to your decision goals, test methods and data, then pilot and back-test to enable keep/license/enforce/drop decisions.

The best patent scoring system is the one that helps me make a clear decision: keep, license, enforce, or drop. If a score cannot support one of those calls, it is just a number.
When I compare top patent tools, I focus on four things:
What decision the score supports
What the score measures: legal strength, technical impact, commercial fit, and workflow fit
How the score is built: rules, citation data, blended models, or AI-based models
Whether the tool fits my team: data coverage, exports, access controls, and review process
The article’s main point is simple: start with the business use case, then test the method, data, and workflow before rollout. It also points to a few hard checks that matter, like normalized weights that total 100%, reviews every 6 to 12 months, and a pilot that compares scores against past licensing, sales, or litigation outcomes.
Patent Quality Scoring Models Compared: Which One Fits Your Decision?
Evaluation of inventions with IPscore 3.0
Quick comparison
What I need to check | What I look for |
|---|---|
Decision fit | Pruning, licensing, enforcement, or prosecution |
Score design | One score for triage or sub-scores for legal, technical, and commercial review |
Model type | Rule-based, bibliometric, composite, or AI/ML |
Data quality | Family data, legal status, jurisdiction coverage, and citation timing |
Team fit | API access, exports, comments, RBAC, audit logs, and status updates |
Proof it works | Pilot results and back-testing against past outcomes |
One detail stands out: the article treats patent scoring as a decision tool first, not a reporting tool. That framing is what makes the whole process work.
1. Define Your Patent Quality Objectives Before Comparing Systems
Before you compare systems, get clear on what decision the score needs to support. Are you using it for pruning, licensing, enforcement, or prosecution? That one choice shapes the whole model: what you score, how much each factor matters, and where you set the cutoffs that trigger action. Put simply, your objective decides which quality dimensions belong in the score.
1.1 Choose the Quality Dimensions That Matter for Your Portfolio
Not every portfolio should be judged the same way. A patent score might reflect legal strength, technical significance, commercial value, and workflow fit. Your mix depends on what you're trying to do. In some cases, legal durability matters most. In others, claim structure, time left before expiration, or geographic relevance may carry more weight.
Some systems assign different weights to citations, age, claim structure, and family size. Use those weights as a starting point, not a rulebook.
Once you've picked the dimensions, tie each one to the decision in front of you.
1.2 Map Your Strategy to Specific Scoring Use Cases
Each business goal should lead to a different scoring use case. If you're pruning a portfolio, a broad quality threshold may be enough to cut the bottom 50% to 80% of assets fast. Licensing analysis may put more emphasis on patent age and citation data. Patents that are about 8–12 years from the priority date can carry strong licensing value when enough term is still left. And if market alignment is part of the picture, you may need a separate layer for geographic relevance.
Each use case should point to a clear action:
keep
license
enforce
abandon
This is where cross-functional input matters. R&D can weigh in on technical relevance. Sales can speak to market fit. Finance can pressure-test cost and ROI. If you skip that step, the model can end up reflecting one team's view and not much else.
After that, decide if you need one score or several.
1.3 Decide on Score Structure, Scope, and Weighting Rules
A single composite score works well for high-level triage, especially when you want to sort patents into tiers before a deeper review. But when the decision needs more nuance, separate sub-scores for legal, technical, and commercial quality often make more sense.
You should also decide whether to score individual patents or entire families. Family-level scoring can use metrics like INPADOC publication counts to show geographic breadth and follow-on investment more clearly. Write the scoring rules down in plain language, and keep weights normalized to 100%. Review those weights every 6 to 12 months as priorities shift.
The next step is to test whether the system's method and data can support those rules.
2. Build a Checklist for Methodology, Data, and Workflow Fit
Once your goals are set, the next step is simple: see whether the system’s scoring logic, source data, and workflow controls can actually support them. This checklist helps you confirm that the platform can carry out the scoring rules you’ve already mapped out.
2.1 Review Scoring Methodology and Indicator Transparency
You should be able to see how each score is built.
A good system should show clear sub-scores and let you adjust the weights to match your goals, whether that means a certain risk threshold or a target geography. For example, it’s better if the platform lets you tune factor weights within a set range, such as 10% to 60% per factor, instead of forcing you into a fixed black-box model.
Look closely at how the system weighs things like citations, age, claim structure, and family breadth. It should also flag claim-drafting risks, including means-plus-function language, divided infringement, and weak specification support.
Once that scoring logic makes sense, shift your attention to the data underneath it. If the inputs are thin or stale, the score won’t mean much.
2.2 Check Data Coverage, Update Cycles, and Legal Status Depth
A score is only as good as the data behind it. Start with jurisdiction coverage and family breadth. Check for INPADOC publication counts, and make sure the system tracks major international filings such as PCT, EP, JP, and CN. If your portfolio relies on pending rights, confirm that it also accounts for continuations or divisionals, since those can help preserve room to maneuver as markets change.
You’ll also want to confirm that forward citations are age-normalized and discounted during the first three years after publication. That matters because early citation counts can paint a distorted picture.
Also check whether the system separates published records from granted records in major jurisdictions. An issued EP, JP, or CN patent can point to more follow-on investment than a published filing by itself.
After that, move from data quality to day-to-day use. The system may score patents well on paper, but can your team review, share, and act on that work without friction?
2.3 Confirm Integration, Exports, and Collaboration Controls
Before you commit, verify the workflow basics:
Workflow Category | Features to Verify |
|---|---|
Integration | REST APIs, webhooks, IP management system (IPMS) compatibility |
Exports | CSV, Excel, PDF, branded Word reports |
Collaboration | Shared workspaces, commenting, real-time updates |
Security and Admin | SSO, role-based access control (RBAC), audit logs, ethical walls |
Automation | Automatic status updates, counsel notifications |
For U.S. legal teams, role-based permissions and audit trails matter for governance. You need a clear record of who changed a score, when they changed it, and why.
A strong system should bring access controls, collaboration, export options, and semantic search into the same workflow.
3. Compare Scoring Models and Platform Capabilities
Once you've checked a system's method, data, and workflow controls, the next step is simpler: does the scoring model match the decision you're trying to make? Not every model works for every job.
3.1 Match the Scoring Approach to the Decision You Need to Make
Each scoring approach does a different kind of work.
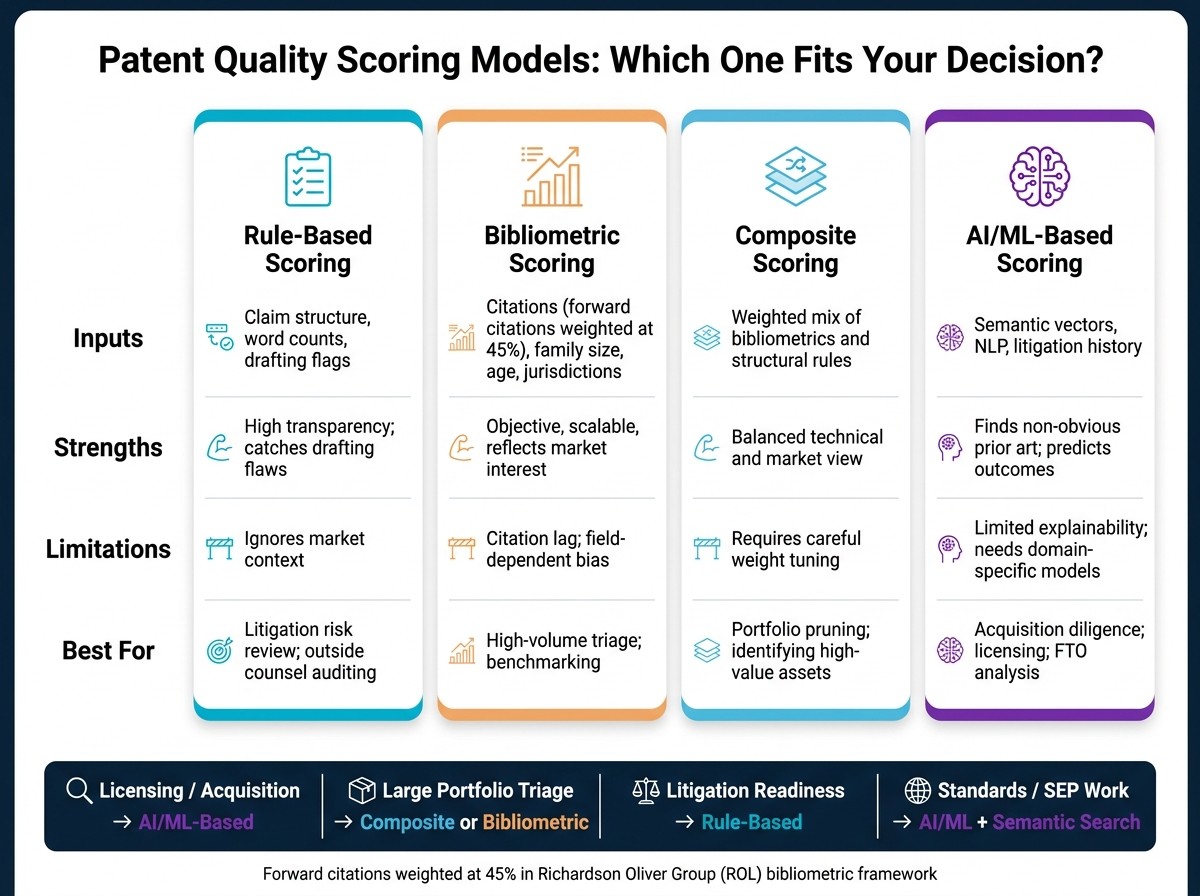
Rule-based scoring looks at the patent document itself. That includes things like claim length, drafting mistakes, and structural issues such as divided infringement risk. This approach works well for litigation readiness and outside counsel audits because it shows drafting weak spots in plain view.
Bibliometric scoring looks at citation, family, and age data. In the Richardson Oliver Group (ROL) framework, forward citations get the highest weight at 45%, which makes them the clearest scalable signal of industry relevance.
Composite scoring mixes both methods in a weighted model. It's a good fit for large-scale portfolio triage before you spend more time and money on deeper review.
AI/ML-based scoring goes a step further. It uses semantic vectors, natural language processing, and litigation history to find non-obvious prior art and estimate outcomes. That can be useful, but there's a trade-off: these models often need domain-specific tuning and can be harder to explain.
Approach | Inputs Required | Strengths | Limitations | Typical Use Case |
|---|---|---|---|---|
Rule-Based | Claim structure, word counts, drafting flags | High transparency; catches drafting flaws | Ignores market context | Litigation risk review; outside counsel auditing |
Bibliometric | Citations, family size, age, jurisdictions | Objective; scalable; reflects market interest | Citation lag; field-dependent bias | High-volume triage; benchmarking |
Composite | Weighted mix of bibliometrics and structural rules | Balanced technical and market view | Requires careful weight tuning | Portfolio pruning; identifying high-value assets |
AI/ML-Based | Semantic vectors, NLP, litigation history | Finds non-obvious art; predicts outcomes | Limited explainability; needs domain-specific models | Acquisition diligence; licensing; FTO analysis |
In practice, the fit is pretty straightforward:
For licensing talks or acquisition diligence, AI/ML-based scoring can be useful.
For fast review across large portfolios, composite or bibliometric models are usually the better fit.
Once the scoring model lines up with the decision, the next thing to test is whether the platform fits how your team actually works.
3.2 Standalone Scoring Tools vs. Broader Patent Platforms
Pick a system that matches your team's process for review, search, reporting, and access control.
A standalone scoring tool can work well for small firms or niche researchers that want a fast, focused setup. A broader platform places scoring inside a larger workflow that may include search, drafting, collaboration, and project management. That kind of setup cuts down on handoffs between tools, which can save time and reduce friction.
The right choice comes down to one thing: do you need scoring by itself, or do you need scoring as part of a connected end-to-end process?
Workflow fit matters. But so does the quality of the evidence behind the score.
3.3 Review AI, Semantic Search, and SEP Analytics Where Relevant
When score quality depends on prior-art coverage and standards data, semantic search and SEP analytics matter.
Semantic search can find patents that are conceptually similar, even when keyword search misses them. That's especially helpful in validity reviews and FTO or novelty searching. It helps teams see around the blind spots that plain keyword matching can leave behind.
For teams working with standardized technologies, SEP analytics links assets to specific technical standards. That makes it easier to sort high-value standard-essential families and spot candidates for licensing outreach.
Patently combines Vector AI semantic search and SEP analytics in one workflow, which improves both the inputs behind the score and the outputs used for licensing and portfolio decisions.
4. Pilot, Validate, and Govern the System You Choose
After you compare models and platform features, don't roll anything out across the whole portfolio just yet. Start by testing the winner on your own patents first.
4.1 Run a Pilot on a Representative Subset of Patents
Use a sample that looks like your actual portfolio. That means pulling patents from different technologies, filing years, and business units. And don't water down the test. Use the same legal, technical, and commercial factors you expect to use in production.
Set clear pilot thresholds for keep, license, and drop decisions. If those lines are fuzzy, the pilot won't tell you much.
It also helps to bring in people from R&D, finance, and portfolio leadership to calibrate the pilot. Each group sees value a little differently, and that tension is useful here. Once the pilot is done, compare the results with what happened in practice.
4.2 Back-Test Scores Against Real Historical Outcomes
This is where the system has to prove itself.
Back-test the scores against historical outcomes. Did the patents with high scores show up in litigation? Were they part of the assets that got licensed or sold? Did the system also bring your top-value patents to the surface?
Use litigated patents and successfully licensed or sold assets as benchmarks. The Richardson Oliver Group (ROL) framework, for example, was built by analyzing millions of patents - including litigated and brokered assets - to identify which signals consistently predict market relevance. That's the kind of data-based footing you want to mirror in your own back-test.
When scores and outcomes don't line up, don't shrug and move on. Dig into the mismatch with attorneys and subject-matter experts. In many cases, the issue comes down to weighting. One factor may count too much, while another barely moves the score even though it should. Adjust the logic, then run the pilot again on the same subset to make sure the change holds up.
At this stage, scores are often most useful for one thing first: cutting obvious low-value patents.
Use what you learn here to lock in the scoring rules and the review cycle.
4.3 Set Governance, Documentation, and Review Cycles
Once the score goes live, governance is what keeps it tied to changing data and business goals. Write down the scoring logic, the weights you picked, the data sources feeding the model, and any known limits. That record matters. Sooner or later, someone will ask why a patent got a certain score.
Set a review schedule and stick with it. A practical cadence looks like this:
Review Type | Frequency | Focus |
|---|---|---|
Operational | Monthly | Cycle times, prosecution costs, budget variance, counsel performance |
Portfolio/Value | Quarterly | Renewal decisions, revenue contribution, patent utilization, data accuracy audits |
Strategic | Annually | Technology coverage, competitive benchmarks, weighting methodology updates |
Model Review | As needed | Score drift, data source changes, and outcome alignment |
Any time you revise weights or switch data sources, re-run the same subset.
Also track whether scores line up with outcomes like renewal decisions, revenue contribution, and licensing activity. If that link is weak, the model likely needs recalibration - not just cleaner documentation.
Conclusion: Choose a System That Fits Your Decisions, Data, and Team
After you set goals, check the data, compare models, and test the output, the last step is simple: pick the system that fits how your team actually makes decisions.
Go with the system your team can explain, defend, and use the same way every time. Focus on clear goals, portfolio-wide data coverage, and scoring logic that lines up with your main decisions.
Transparency matters most when someone asks, “Why did this score come out this way?” You should be able to trace every result back to the inputs and weights behind it.
Validation should stay cross-functional too. A model should reflect technical, commercial, and financial priorities, not just one team’s point of view.
Use pilot results and back-tests to check the model before it starts shaping high-stakes decisions. Then write down the logic and review it on a set schedule. That’s the bar: decision fit, data fit, and team fit.
The right system turns patent review into repeatable, trusted decision-making.
FAQs
How do I know which scoring model fits my goal?
First, get clear on your patent evaluation goal. Different scoring models focus on different things, like strategic value, technical merit, or business ROI.
Then pick a model that fits that goal. For example, use a weighted decision matrix if you want to rank patents for strategic priority. If you're trying to filter for high-value assets, lean on portfolio factors like citations, age, claim count, and family size.
From there, tailor the criteria and weights to fit your situation. Then test the model, see how it performs, and refine it on a regular basis.
Should I score single patents or whole families?
In most cases, it makes more sense to score whole patent families instead of single patents. A family usually gives you a broader view of strategic value, investment, overall strength, scope of protection, and geographic coverage.
That said, the best approach still depends on your organization’s goals and the context of the analysis. Family-level scoring usually gives decision-makers a broader basis for comparison.
What proves a patent quality score is reliable?
A patent quality score is reliable when it comes from a clear, objective, and repeatable process. People should be able to see how the score is calculated and how each part connects to patent value and validity.
It also helps to use multiple tested signals, such as forward citations, age, claim count, and family size. Those signals should be benchmarked, normalized, and explained in plain language so users can make informed decisions.