Predictive Models for Patent Tech Clusters
Intellectual Property Management
Jun 13, 2026
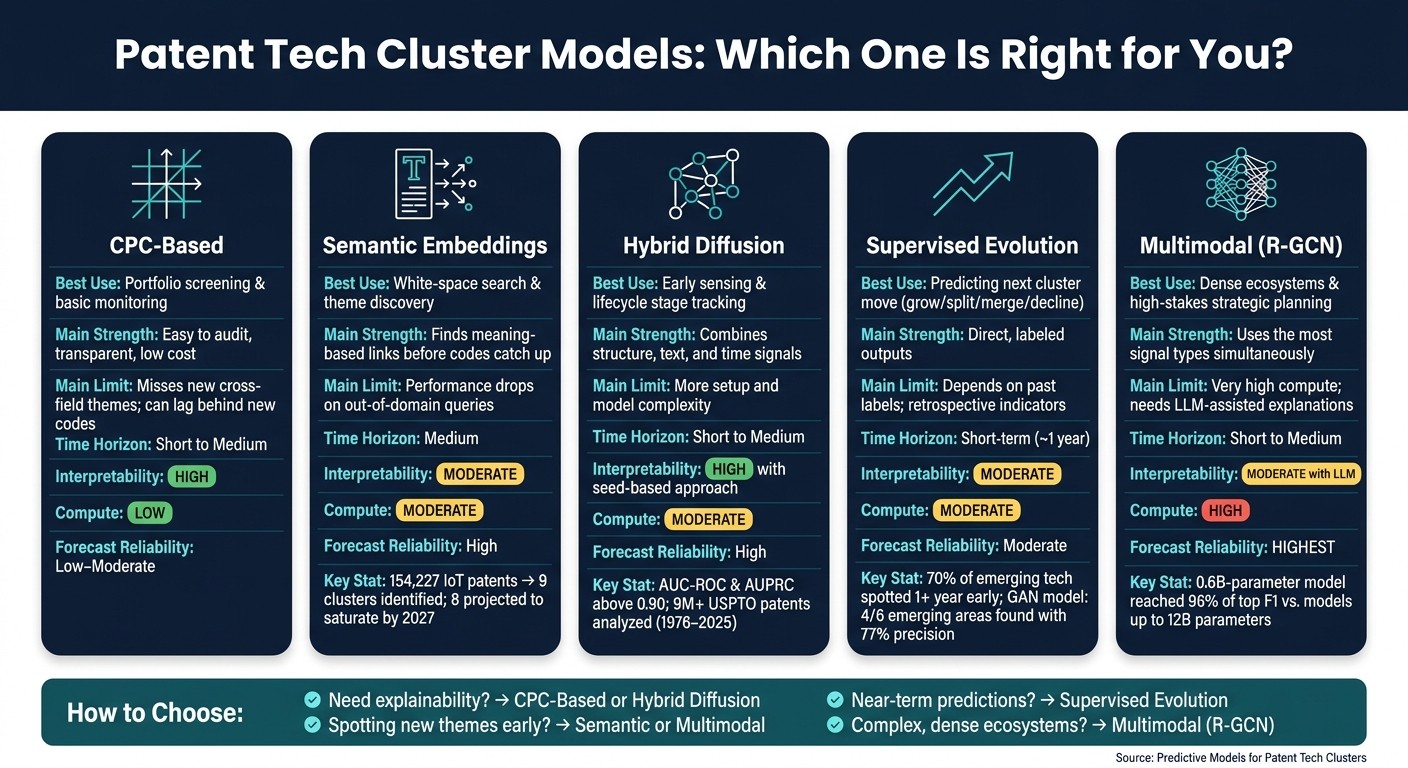
No single model wins: use CPC for explainability, semantic/hybrid for early weak signals, supervised for reliable 1-year cluster forecasts.

If I need to forecast patent tech clusters, I would not rely on one model alone. The article’s core point is simple: CPC-based methods are a starting point, semantic models find new themes sooner, hybrid and multimodal models do better at early cross-field shifts, and supervised models work best for short-term next-step predictions.
Here’s the short version in plain English:
CPC-based clustering is the baseline. It is easy to check and low cost, but it can lag when new themes do not fit old codes.
Semantic embedding models group patents by meaning in titles, abstracts, and claims. They are better at spotting new combinations before code systems catch up.
Hybrid diffusion models mix text, citations, and time signals. In the article, these models stand out for early sensing and cluster stage tracking.
Supervised models predict direct outcomes like growth, decline, splits, or merges. They tend to focus on about 1 year ahead.
Multimodal models combine text, citations, metadata, and inventor or assignee links. They usually give the strongest forecast output in dense patent landscapes, but they need more compute.
A few numbers from the article make the tradeoffs clear:
A 2025 IoT study used 154,227 patents and found 9 clusters, with 8 projected to saturate by 2027
A 2026 R-GCN study ran on 9 million+ USPTO patents from 1976 to 2025
Hybrid hypergraph models posted AUC-ROC and AUPRC above 0.90
One citation-based model spotted 70% of emerging areas at least 1 year early
A GAN-based model found 4 of 6 emerging areas early with 77% precision
A 0.6B-parameter embedding model reached 96% of the top F1 score from models up to 12B parameters
What I take away from the article is this:
If you want something easy to explain, start with CPC-based or seed-based hybrid methods. If you want to spot new cluster formation sooner, look at semantic, hybrid, or multimodal models. And if you need direct near-term predictions, use supervised models.
Patent Tech Cluster Models: Which One Is Right for You?
NODES 2024 - Building Knowledge Graphs with LLMs from USPTO Patent Data
Quick Comparison
Model family | Best use | Main strength | Main limit | Time horizon |
|---|---|---|---|---|
CPC-based | Portfolio screening, basic monitoring | Easy to audit | Misses new cross-field themes | Short to medium |
Semantic embeddings | White-space search, theme discovery | Finds meaning-based links | Can slip outside training domain | Medium |
Hybrid diffusion | Early sensing, stage tracking | Mixes structure, text, and time | More setup and model complexity | Short to medium |
Supervised evolution | Predicting next cluster move | Direct outputs like split/merge/grow | Depends on past labels | Short-term |
Multimodal | Dense ecosystems, high-stakes planning | Uses the most signal types at once | High compute and harder review | Short to medium |
So if I had to reduce the article to one sentence, it would be this: the right model depends on whether I care most about explainability, early weak-signal detection, short-term prediction, or full-ecosystem forecasting.
1. CPC-Based Clustering with Indicator Screening
CPC-based clustering groups patents by Cooperative Patent Classification (CPC) codes to define technology domains. It works best as a baseline model, not the final word in forecasting. From there, analysts can add citation vectors, where each dimension tracks citations from a CPC subcategory.
Data Inputs
Use bibliographic, timing, citation, family, and legal-status data to show a cluster’s maturity and momentum. That makes CPC clustering a strong starting point, but only when new activity still lines up with existing codes.
Interpretability
CPC clusters are easy to audit because each group maps to a formal code. That makes them useful for portfolio screening and trend monitoring. The catch is at the edges. CPC updates can lag behind shifts in technology, and new cross-domain themes often don’t fit neatly into pre-set categories.
Forecast Horizon and Weak-Signal Detection
CPC-based models are best for short-to-medium forecast horizons. Long-range patent forecasting gets harder when regulation changes or breakthroughs reshape the field.
For weak-signal detection, analysts usually watch a small set of screening signals:
Cross-category citations: patents cited outside their own CPC area
Co-classification shifts: patents starting to appear across different code combinations
Filing acceleration: a pickup in applications that can hint at new activity
Taken together, these signals can spot new recombinations before they show up in filing volume and can show how technology domains interact.
One citation-based clustering study did exactly that. Researchers predicted the emergence of what later became USPTO Class 442 in 1991, years before the class was officially formed in 1997.
When cluster boundaries start to blur, semantic models tend to pick up the shift sooner.
2. Semantic Clustering with Embeddings
When CPC codes fall behind new patent combinations, embeddings can spot the shift sooner. Instead of leaning on CPC labels, semantic clustering groups patents by their text: titles, abstracts, and claims. Each patent is turned into an embedding, and patents with similar meaning sit close together in vector space. That makes this approach useful when new tech starts to outgrow the code system.
Data Inputs
For patent embedding tasks, the strongest text view is the Title + Abstract + Claims (TAC) combination. Model choice also matters. Larger models often do better on retrieval, while smaller ones can cluster more efficiently on some benchmarks. There’s a catch, though: embedding performance can drop hard on out-of-domain queries.
Interpretability
Semantic clusters are built around what a technology does, not just how it has been classified. That usually makes the labels easier to read and explain. To make them clearer still, newer frameworks add human-in-the-loop layers with Large Language Models (LLMs). These layers give post-hoc explanations for cluster labels and domain summaries.
Forecast Horizon and Weak-Signal Detection
That semantic view can also support forward-looking cluster forecasts. A 2025 study of 154,227 IoT patents used BERT embeddings and k-means to identify nine clusters and projected saturation for eight of them by 2027.
When text patterns start to lose strength, network and diffusion signals matter more.
3. Hybrid Diffusion-and-Cluster Models
When CPC-based or text-only models miss recombination across fields, hybrid models help evaluate forecast accuracy and fill the gap. They combine diffusion signals with cluster structure to follow a technology through its lifecycle stage. This matters most when a cluster is just starting to form across fields and still doesn't show up clearly in codes or text alone.
Data Inputs
Hybrid models bring together citation networks, co-classification data, and embeddings so they can track both topical similarity and cross-field influence. They also use citation vectors to spot cross-field patents, or non-assortative patents, as signals of recombination.
Interpretability
These hybrid graph models can be harder to read at a glance. To make them easier to use, LLM layers can add post-hoc labels to latent clusters and summarize emerging domains.
Forecast Horizon and Weak-Signal Detection
This is where hybrid models stand out: early sensing.
A 2026 study applied an R-GCN framework to more than 9 million USPTO patents filed from 1976 to 2025. The model tracked how one focal semiconductor patent seeded a solar-energy opportunity space. The authors argue that mixing structural, semantic, and temporal signals turns early sensing into a managerial capability rather than a look-back exercise.
Performance is strong too. Hybrid hypergraph models that combine co-citation and co-classification features have posted AUC-ROC and AUPRC scores above 0.90. One detail stands out: co-citation features, which reflect implicit knowledge flow, tend to beat co-classification features alone when forecasting technology convergence.
Put simply, the main payoff is stage detection, not just clustering.
Lifecycle Stage | Key Indicator Signal | Model Component |
|---|---|---|
Emerging | Strong influence of seed patents; cross-field citations | Citation Vectors / R-GCNs |
Accelerating | Sustained growth in multi-tech convergence; filing growth | Hypergraph Evolution |
Maturing | Probability shift in stage transition; high absorption | |
Declining | Reduced citation reach; flat semantic patterns | Diffusion Vectors |
When you need explicit labels for cluster movement, not just latent structure, supervised models add that next layer.
4. Supervised Models for Cluster Evolution
If hybrid models spot new structure, supervised models take the next step: they turn that structure into a direct prediction about what happens next.
In practice, supervised models treat patent-cluster forecasting like a classification or sequence-labeling task. They learn from labeled past outcomes and predict whether a cluster will grow, shrink, split, merge, or shift into another state in the next year.
Data Inputs
These models usually pull from a mix of patent tools and signals, including citation counts, CPC/USPTO classes, abstracts, assignee type, and time-series data. Citation vectors add another layer by showing cross-category citation patterns as model features.
Training labels usually come from expert seed patents, past reclassifications, and citation-based heuristics.
Interpretability
Different model types pick up different patterns. MLPs tend to learn simpler feature relationships. CNNs are good at local sequences. Transformers such as BERT can read broader context, but they’re harder to audit.
That trade-off matters. A model might make stronger predictions, but if no one can trace why it made them, review becomes tougher. SHAP or Gini importance can help show which features drove each prediction.
Forecast Horizon and Weak-Signal Detection
Most supervised models are built for short-term forecasting, often about one year ahead. That makes sense: cluster behavior can shift fast, and near-term predictions are usually easier to test against later outcomes.
The results here are worth noting. One citation-based model identified 70% of emerging technologies at least a year before formal recognition.
A GAN-augmented deep network identified 4 of 6 emerging technologies from the 2017 hype cycle one year early, with 77% precision.
Model Type | Primary Input | Forecast Horizon | Key Output |
|---|---|---|---|
LSTM-CRF | 10 patent indicators | Annual transitions | Next-state probability |
Citation Vector | Cross-category citations | Short-term | Cluster splitting/merging |
GAN + Deep Classifier | Augmented patent data | ~1 year ahead | Emerging technology identification |
Seed-patent landscaping | Seed patents + abstracts | Real-time/historical | Cluster boundary discovery |
When a single feature set falls short, multimodal models combine text, citation, and network signals.
5. Multimodal Patent Landscape Models
When fixed labels stop doing the job, multimodal models look at several signals at once to infer cluster movement more directly. In patent analysis, that usually means combining text, citations, metadata, and inventor or assignee networks to forecast cluster formation when CPC codes miss cross-domain links. The big design decision comes down to one thing: how those signals get fused.
Data Inputs
These models pull in semantic embeddings, citation patterns, CPC/IPC codes, assignee type, jurisdiction, and inventor or assignee collaboration graphs. R-GCNs can trace emerging technology areas at scale. Each input helps with forecasting in a different way.
Feature Type | Data Inputs | Role in Forecasting |
|---|---|---|
Semantic | Title, Abstract, Claims (BERT/SBERTa) | Captures shared function and conceptual shifts |
Relational | Citations, Co-citations | Maps implicit knowledge flow and convergence signals |
Structural | Inventor/Assignee networks | Detects inventor and assignee network context and emerging collaborations |
Metadata | CPC/IPC codes, Assignee type, Jurisdiction | Grounds predictions in formal taxonomies and actor context |
Interpretability
For interpretability, teams often use LLM-assisted explanations to name or describe clusters, then pair that with SHAP or Gini scores to show which features shaped the model’s output . That mix helps make the results easier to inspect instead of leaving them as a black box.
Weak-Signal Detection
This is where multimodal models tend to shine. They can spot convergence signals that single-input models often miss. When co-citation and co-classification features are combined, convergence prediction improves, which makes these models a strong fit for early convergence screening.
Pros, Cons, and Best-Fit Use Cases
After looking at the five model families side by side, the next step is practical: which one fits your task, your data, and your need to explain the result? There’s no single winner in every case. The best choice depends on your forecast horizon, how much weak-signal detection matters, and how clearly you need to explain the output.
The main tradeoff is pretty simple: transparent models are easier to defend, while more complex models tend to predict better.
That tradeoff matters even more in fast-moving technology areas. Status-quo models can get old fast. Embedding models tend to work best on Title + Abstract + Claims, but their performance can drop hard when they’re used outside the domain they were trained on. In patent analysis, that’s a serious issue. A model trained in one technology area may look solid, then struggle when you apply it to a nearby field.
The table below turns those tradeoffs into plain use-case guidance.
Model Family | Pros | Cons | Interpretability | Computational Burden | Forecast Reliability | Best-Fit Scenario |
|---|---|---|---|---|---|---|
CPC-Based | Transparent, standardized, low cost | Splits related technologies across codes | High | Low | Low–Moderate | Portfolio prioritization; basic landscape monitoring |
Semantic Embedding | Finds hidden links; handles synonyms | Out-of-domain gaps; black-box outputs | Moderate | Moderate | High | White-space discovery; prior art search |
Hybrid Diffusion | High precision; emulates human curation at scale | Requires manual seed curation upfront | High (seed-based) | Moderate | High | Technology scouting; landscape monitoring |
Supervised Evolution | Good for link prediction and convergence signals | Relies on retrospective indicators | Moderate | Moderate | Moderate for short-horizon change detection | Convergence forecasting; link prediction |
Multimodal (R-GCN) | Highest reliability for complex ecosystems | Very high compute; needs LLM-assisted explanations | Moderate (with LLM) | High | Highest | Strategic investment; alliance strategy |
A simple way to read this table: if you need something easy to explain to stakeholders, CPC-Based and Hybrid Diffusion are usually safer bets. If the goal is to spot hidden relationships that a code-based view might miss, Semantic Embedding can do that job well. If you're tracking near-term shifts or links between fields, Supervised Evolution fits better. And if you're working in a dense, connected ecosystem where firms, patents, and partnerships all matter at once, Multimodal (R-GCN) gives you the strongest forecasting power, though it comes with a much heavier compute bill.
In other words, the “best” model depends less on abstract performance and more on the setting you’re in, the time horizon you care about, and how much explanation your audience will expect.
Conclusion
There’s no one-size-fits-all model for every patent-cluster job. The right pick depends on a few plain factors: how far out you need to forecast, how much explanation your team needs, how connected the tech landscape is, and how much compute you can spend.
In practice, relational models work well for competitive monitoring. Multimodal models make sense for industries that are starting to blend together. And semantic models are often the better fit for long-range signals that can show up before code-level convergence.
Model size isn’t the whole story either. Sometimes a smaller model, tuned well for the task, beats a larger model from a different family. In one case, a 0.6B-parameter embedding model reached 96% of the best classification F1 score achieved by models as large as 12B parameters.
Before deployment, backtest on historical USPTO-recognized classes before using the model to forecast future ones. Put simply: if a model can’t reconstruct the past, it’s not ready for the future. The best model is the one that gives you reliable, defensible answers within your constraints.
FAQs
Which patent cluster model should I start with?
It depends on your goals, but the Emerging Clusters Model is a strong place to start. It uses patent citation analysis to spot emerging technologies in near real time, which makes it useful for finding innovation trends early.
If you need more automation or want to predict where things are headed, automated patent landscaping and citation-network models can work well too. They’re especially helpful when you need analysis at scale and steady trend forecasting.
How far ahead can these models predict reliably?
These models generally predict patent technology clusters about one to two years ahead with solid accuracy.
Some methods do well in the short term. For example, ARIMA models have reached around 82% accuracy when forecasting technology growth within that same one- to two-year window.
How do I validate a patent cluster forecast before using it?
Validate it with backtesting: compare predictions against past patent filing trends using separate training and testing sets. Then check if the model gets the direction of the trend right, not just the total number of filings.
You should also test time-series behavior, such as unit roots, and run robustness checks by changing seed data or model parameters to see if the forecasted trends stay stable.