Real-Time Patent Data Sync: How It Works
Intellectual Property Management
Feb 27, 2026
How CDC, sync engines, APIs and cloud tools enable instant, accurate patent data updates, conflict resolution, and real-time portfolio insights.

Real-time patent data sync ensures that updates from global patent offices are reflected across systems almost instantly. It eliminates delays caused by traditional batch updates and manual processes, providing patent professionals with accurate and up-to-date information in seconds. This system relies on APIs, event-driven architectures, and technologies like Change Data Capture (CDC) to detect, transmit, and synchronize changes efficiently.
Key Takeaways:
Speed: Updates occur in milliseconds to seconds, compared to hours or days with older methods.
Accuracy: Prevents errors from manual entry and ensures consistent data across platforms.
Core Technologies: Synchronization engines, CDC mechanisms, APIs, and cloud integration tools.
Benefits: Reduces time spent on manual searches by up to 70% using top patent tools, enabling teams to focus on strategic tasks.
Challenges: Integrating with global patent offices, handling rate limits, and resolving data conflicts.
For patent professionals managing large portfolios, real-time sync delivers faster insights into competitor filings, legal events, and technology trends, streamlining decision-making and reducing operational risks.
Core Components of Real-Time Patent Data Sync Systems
Synchronization Engine
The synchronization engine is the heart of the system, ensuring data stays consistent across all platforms in your tech stack. Instead of relying on custom scripts for data movement, this engine works declaratively: you define what data to sync, and the engine takes care of the rest.
Today's engines support multi-directional synchronization, which means they can update data across multiple systems simultaneously. They also handle mismatches by applying rules-based logic to resolve conflicts automatically - no manual effort required. Syncari, for instance, holds a patent for a multi-directional sync technology capable of managing thousands of real-time data streams at once.
"With some kind of sync engine, you, as the developer, should be able to ignore everything related to moving data between servers and clients. You should only have to care about and build out your business logic." - Adam Nyberg, Software Engineer
The engine also combats "data drift" - a problem that arises when systems evolve independently and data starts to misalign. Intelligent connectors in the engine understand the unique schemas of patent databases and adjust automatically when a patent office updates its data structure, preventing downstream issues.
Once the synchronization engine orchestrates the process, it relies on precise data change detection to capture every update as it happens.
Data Change Detection Mechanisms
Change Data Capture (CDC) is the backbone of real-time data tracking. Instead of periodically scanning entire tables, CDC monitors the Write-Ahead Log (WAL) to detect every INSERT, UPDATE, and DELETE operation in real time. This approach slashes data latency from hours to milliseconds while keeping the primary database's performance intact.
Tools like Apache Kafka process these change events, which are fed by connectors such as Debezium, and hold them for distribution to other systems. Thanks to these mechanisms, modern patent platforms now provide access to over 207 million patent records and 2.7 billion legal data points in near real time.
To avoid log overflow and ensure smooth event processing, it’s crucial to design sink operations as idempotent. For example, using SQL commands like "ON CONFLICT DO UPDATE" prevents duplicate data if a network failure causes the same event to be processed multiple times.
Once changes are captured, APIs and cloud integration tools ensure the updates are distributed across systems, maintaining consistency.
APIs and Cloud Integration
APIs play a key role in connecting global patent offices with enterprise systems. RESTful APIs act as the bridge, enabling seamless data exchange. Key sources include the USPTO Open Data Portal (ODP) APIs, which provide access to PTAB data, enriched citations, office action text, and patent assignment searches. Similarly, the EPO Open Patent Services (OPS) delivers INPADOC published, legal, and family data. The USPTO is in the process of migrating its legacy Developer Hub APIs to the new ODP, with completion expected by early 2026.
For more complex workflows, Integration Platform as a Service (iPaaS) tools like MuleSoft Anypoint, Workato, and Azure Data Factory are invaluable. These platforms orchestrate data flows between cloud-based and on-premises systems, ensuring updates from external patent offices are reflected across your entire infrastructure. This helps maintain a single source of truth for patent data.
When choosing a patent data provider, look for those offering RESTful APIs that can easily integrate with BI tools like Power BI, Tableau, Snowflake, and Databricks. To secure sensitive intellectual property data, implement multi-factor authentication (MFA) and use granular API credentials. Additionally, configure synchronization engines with flexible polling intervals or automated triggers to strike the right balance between real-time accuracy and server performance.
Building real-time data sync solutions with Remix
How Real-Time Patent Data Sync Works
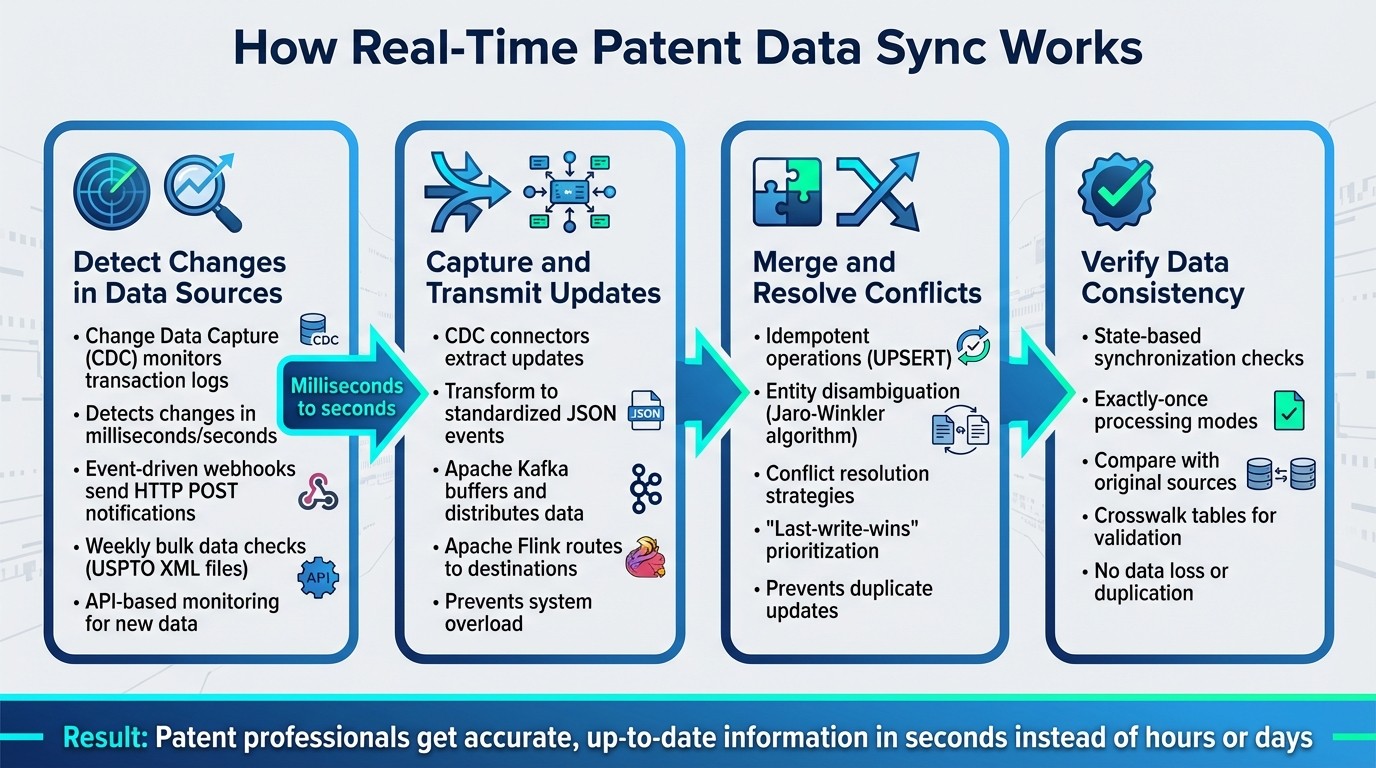
Real-Time Patent Data Synchronization: 4-Step Process Flow
Real-time patent data synchronization is a four-step process designed to keep patent professionals working with the freshest information possible. Each step builds on the last, ensuring updates flow seamlessly from source databases to target systems.
Step 1: Detect Changes in Data Sources
The process kicks off with systems constantly monitoring patent office databases and internal repositories for updates. Using Change Data Capture (CDC), transaction logs are scanned to pinpoint changes almost instantly, with delays measured in milliseconds or seconds - far faster than traditional batch processes.
Event-driven webhooks also play a role by sending HTTP POST notifications the moment specific events occur. For instance, a webhook might trigger when a document is flagged for an update or when a data ingestion task wraps up. Additionally, bulk data sources, like the USPTO's XML file releases, are checked weekly to ensure no updates are missed. API-based monitoring adds another layer, alerting systems as soon as new data becomes available.
"Change Data Capture (CDC) is a software design pattern that identifies and captures changes made to data in a database, then delivers those changes in real-time to downstream processes or systems." - Vinay Sharma
To ensure reliability, design sink operations with idempotency in mind, using tools like "ON CONFLICT" clauses to handle duplicate events caused by network retries. Security measures, such as HMAC-SHA256 signature verification and timestamp checks, are crucial to prevent replay attacks. Meanwhile, monitoring replication slot lag ensures the system keeps up with the volume of changes in the source database.
Once changes are identified, they are packaged and prepared for the next phase.
Step 2: Capture and Transmit Updates
After detecting changes, CDC connectors extract the updates and transform them into standardized JSON events. These events are then sent to message brokers like Apache Kafka, which act as intermediaries, buffering and distributing the data to downstream systems.
Stream processing engines, such as Apache Flink, consume these events and route them to their destinations - whether that's a search index, a cache, or a replica database. This setup prevents any single component from being overwhelmed while ensuring updates are quickly disseminated across the system.
To maintain data freshness, set up alerts for transmission delays. A schema registry is also essential for gracefully handling changes in database structures.
Step 3: Merge and Resolve Conflicts
Once updates are transmitted, they are integrated with existing data, and any conflicts are resolved. Idempotent operations, like UPSERT or "ON CONFLICT" clauses, prevent duplicate updates from corrupting the data.
For patent data, merging often involves entity disambiguation - connecting records that reference the same inventor or assignee, even if their names are inconsistent due to typos or variations. Algorithms like Jaro-Winkler are commonly used for this purpose. Conflict resolution strategies, such as "last-write-wins" or prioritizing a specific source system, help determine which update should take precedence.
Step 4: Verify Data Consistency
The final step ensures that the synchronized data matches its original sources. State-based synchronization checks that every system reflects the source data accurately. Exactly-once processing modes further guarantee that no data is lost or duplicated during the synchronization process.
To validate accuracy, systems compare synchronized records with the original sources. Supplementary tables, like persistent ID or crosswalk tables, are often created to facilitate end-user analysis. This step closes the loop, ensuring every update is accurately reflected across all connected systems.
Common Challenges in Real-Time Patent Data Sync
While the four-step synchronization process lays a solid groundwork, putting it into practice comes with its own set of challenges. These hurdles can affect system reliability and performance, making it crucial to address them effectively.
Integrating with Multiple Patent Offices Worldwide
Connecting with patent offices across the globe is no easy task. Each office has its own quirks, from inconsistent documentation to unique authentication methods. For instance, some require API keys with video verification, while others use intricate OAuth flows.
"The official swagger had type mismatches between the spec and actual API responses - numeric fields defined as strings, array types that should be objects, date format constraints on non-ISO timestamps" - Wolfgang Stark, Software Architect
Frequent API changes only add to the complexity. When the USPTO retired its Open Data Portal Beta through 2025, developers had to overhaul their integrations, adapt to new endpoints, and evaluate generative AI patent drafting tools. The USPTO ODP version 3.0, launched on November 21, 2025, introduced 19 new API endpoints for Patent Trial and Appeal Board data, requiring even more effort.
To tackle these issues, maintaining accurate OpenAPI specs through live endpoint testing is critical. Continuous integration test suites that monitor patent office APIs can catch breaking changes early, minimizing disruptions.
Scaling for Large Patent Portfolios
Managing synchronization for portfolios with thousands - or even millions - of patents demands careful planning. Many patent search APIs come with strict rate limits. For example, PatentsView allows only 45 requests per minute, while USPTO TSDR updates are capped at 60 requests per minute [[20]](https://search.patentsview.org/docs/docs/Search API/SearchAPIReference). Bulk downloads are even more restrictive, often limited to just four requests per minute per API key.
To work around these limitations, asynchronous architectures and modern HTTP clients (such as async/await with httpx) can handle multiple API calls simultaneously. Cursor-based pagination using an "after" parameter ensures consistent performance, unlike traditional offset pagination, which slows down with larger datasets [[20]](https://search.patentsview.org/docs/docs/Search API/SearchAPIReference). Adding exponential backoff and automatic retry logic helps manage rate limits and temporary network issues.
A hybrid approach is often the most effective. Real-time queries can support immediate dashboard updates, while bulk feeds populate data lakes for deeper analysis. These strategies not only improve efficiency but also help manage errors and conflicts more effectively.
Error Handling and Conflict Resolution
Patent data synchronization comes with unique challenges in error handling and conflict resolution. Regular quality checks - such as verifying expiry calculations and ensuring accurate family linkages - are critical, especially for high-stakes decisions. Real-time monitoring systems that send automated alerts to platforms like Slack or Teams can notify teams immediately when issues arise or significant changes are detected.
Standardizing geographic data is another key step. Matching raw city, state, and country data against master geocode files (from providers like Google or MaxMind) helps resolve location discrepancies. Crosswalk tables that link patents to inventors, assignees, and locations ensure data integrity and consistency across updates, maintaining a single source of truth.
Building resilience into every part of the synchronization process is essential. From retry logic in API calls to validation checks that catch errors before they spread, a robust system is vital for ensuring reliable, real-time patent data synchronization.
How Patently Supports Real-Time Patent Data Sync
Patently has transformed how patent professionals handle data by shifting from monthly batch updates to real-time synchronization. This upgrade ensures instant access to the latest patent information. Currently, the platform manages a staggering 82 million patent families (equivalent to 135 million individual patents) and supports 226 field mappings for each patent entry.
AI-Powered Tools for Patent Professionals
At the heart of Patently's real-time capabilities is Vector AI, a semantic search engine designed to decode complex data relationships and deliver highly relevant results. For example, in October 2024, Laurence Brown used Vector AI to search for "In-ear headphones with noise isolating tips" (pre-2000). The system returned 300 relevant patents almost instantly. This kind of speed and precision is critical in environments where quick data reconciliation is key.
"With Elastic, it's like having a patent attorney with decades of experience guiding every search."
Andrew Crothers, Creative Director, Patently
Another standout feature is Onardo, Patently's AI drafting assistant. Onardo taps into real-time data to search for prior art during the drafting process, ensuring users always have the most current information at their fingertips.
Integration and Team Collaboration Features
Patently's cloud-first architecture, powered by Elastic Cloud, guarantees stability even during high-volume data ingestion. Its real-time collaboration tools, built on Yjs technology, allow team members to work on patent specifications simultaneously. Features like shared comments, ratings, and insights streamline teamwork by helping to resolve conflicts and maintain uniformity. Additionally, granular access controls ensure data security remains uncompromised.
Real-Time Data Accuracy and Portfolio Insights
To maintain data accuracy, Patently integrates proactive monitoring and alerting systems. These tools identify and address potential issues before they can disrupt users. Built-in error-checking protocols validate retrieved patent records during synchronization, and automatic project updates every 30 days keep portfolios current. At the same time, real-time updates on individual patent changes ensure teams stay informed without being overwhelmed by constant notifications.
"Features for real-time monitoring and alerting became crucial for preserving the system's integrity. Through proactive monitoring, the team can fix any problems before they affect users."
Elastic Blog
Conclusion
Real-time patent data synchronization has become a game-changer for modern patent professionals. With manual tracking, there’s always the risk of missed deadlines or overlooked updates, which can lead to lost rights. Real-time systems address these challenges with automated alerts and continuous monitoring, ensuring nothing slips through the cracks.
At its core, real-time sync handles critical tasks like detecting changes, transmitting updates, resolving conflicts, and verifying data consistency. For large innovation teams, this automation translates into significant time savings and improved efficiency.
Take Patently’s platform as an example. It processes millions of patent records in real time, moving beyond outdated monthly batch updates. By offering current and reliable information, it enables patent professionals to make quick, informed decisions. Features like AI-enabled patent analysis for semantic search, a scalable cloud-first design, and proactive monitoring ensure data accuracy and dependability.
This shift to real-time insights allows professionals to stay ahead. They can track competitor activity, monitor legal events, and spot filing trends as they occur - not weeks or months later. The result? More actionable strategies and fewer operational headaches.
When evaluating synchronization tools, look for platforms with event-driven architecture instead of basic polling, two-way sync for seamless team collaboration, and automated docketing to reduce manual errors. These features ensure your data remains accurate, up-to-date, and ready for action when you need it most.
Adopting real-time sync isn’t just about keeping up - it’s about staying ahead in a fast-paced world of innovation.
FAQs
What counts as “real-time” sync in practice?
In practice, “real-time” sync means systems update instantly, reflecting changes as they happen. Think of it like a live sports scoreboard - every play updates the score immediately, ensuring the information stays current and consistent without any noticeable delay. This creates a smooth, up-to-date experience across all platforms.
How do you keep patent data correct when two systems update it at once?
Real-time synchronization ensures patent data remains accurate, even when two systems update it simultaneously. This process actively identifies conflicts, discrepancies, or missing information as they occur. By carefully reconciling the data with an understanding of the broader business context, it preserves consistency and resolves potential issues before they impact users.
How can you scale sync without hitting patent office API rate limits?
To handle real-time patent data syncing without hitting API rate limits, consider using bulk data downloads provided by sources like the USPTO. These downloads minimize the need for frequent individual API calls. Additionally, employ techniques such as client-side rate limiting, request batching, and retry logic to manage API requests effectively.
Using tools like client libraries that include features like automatic retries and timeout handling can further streamline the process. These methods help maintain smooth, scalable synchronization while adhering to API usage guidelines.