Semantic Embedding for Patent Search
Intellectual Property Management
May 12, 2026
Use semantic embeddings to find conceptually similar patents faster, reduce missed prior art, and enable cross-language searches.

Semantic embedding is reshaping patent searches by focusing on meaning instead of exact words. Unlike traditional keyword searches that often miss relevant patents due to vocabulary differences, this AI-based method uses high-dimensional vectors to identify conceptually similar patents - even across languages. Key benefits of using top patent tools include:
Improved accuracy: Reduces missed prior art by 30–60%.
Time-saving: Simplifies queries and delivers faster results.
Cross-language capability: Finds related patents in multiple languages without translations.
Efficient workflows: Enhances prior art searches, technology analysis, and portfolio management.
What is Semantic Embedding in Patent Search?
Definition of Semantic Embedding
Semantic embedding is a machine learning technique that transforms patent text into numerical data - essentially high-dimensional vectors that represent the meaning and context of words. Instead of seeing text as just a sequence of characters, these models convert technical descriptions into mathematical coordinates within an abstract feature space. These vectors, often ranging from 384 to 4,096 dimensions, allow patent texts with similar concepts - like "battery management" and "energy efficiency" - to naturally group together.
Each patent document is placed into this mathematical space, where related technical ideas cluster, even if they use different terminology. For example, a patent on "battery management" would likely be positioned near documents discussing "power optimization" or "energy efficiency". As explained by eOptimize:
Instead of matching words, semantic search matches meaning. It converts both documents and queries into high-dimensional numerical vectors - called embeddings - where similar concepts land close together in vector space.
This process uses Transformer-based natural language processing models, which analyze how terms interact within technical descriptions. Unlike traditional keyword searches that treat words as isolated units, these models grasp the relationships and context between terms. This mathematical transformation helps to overcome the limitations of traditional search methods.
How Semantic Embedding Solves Patent Search Problems
Semantic embedding tackles key challenges in patent search by leveraging its concept-based approach. One major issue in traditional searches is vocabulary mismatch - where inventors describe the same technology using entirely different terms. Conventional keyword searches struggle with this, often requiring exact matches or complex Boolean queries to cover all possible synonyms. Semantic embedding eliminates this problem by enabling searches based on meaning, not just specific keywords.
This capability is especially crucial for global patent searches. With more than 70% of patent applications filed outside the U.S., cross-linguistic semantic matching becomes essential for thorough prior art discovery. The technology automatically identifies patents with similar concepts across languages. Studies show that domain-specific models trained on patent datasets - like PatentSBERTa and Bert-for-patents - consistently outperform general-purpose AI models in pinpointing these technical similarities. These advancements significantly improve tasks like prior art searches and portfolio management, which are explored in later sections.
How AI is changing patent search, from keywords to semantic understanding
Semantic vs. Traditional Patent Search Methods
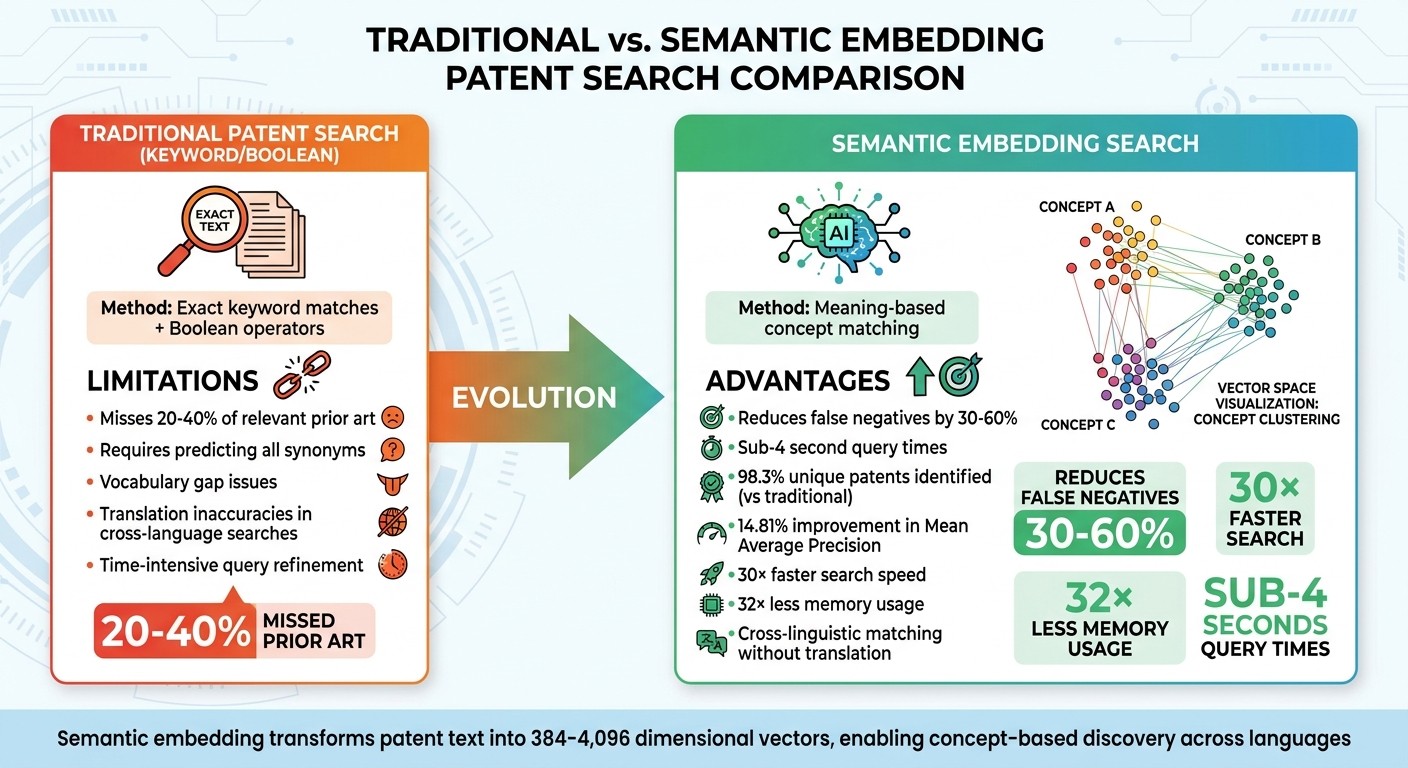
Semantic vs Traditional Patent Search: Performance Comparison
Problems with Keyword and Boolean Searches
Traditional patent search methods rely heavily on exact keyword matches and Boolean operators. This forces users to predict and include every possible synonym, variation, or related term in their queries. The result? A vocabulary gap that often leaves critical prior art undiscovered. Studies show that Boolean-only searches can miss 20% to 40% of relevant prior art, requiring professionals to spend significant time manually refining their queries. The challenge becomes even greater with cross-language searches, where translation inaccuracies can prevent conceptually similar patents in different languages from being identified. These issues highlight the limitations of traditional methods in capturing the deeper meaning behind technical terms.
Advantages of Semantic Embedding
Semantic embedding approaches shift the focus from exact word matches to understanding the meaning behind terms. This technology recognizes that phrases like "battery management", "power optimization", and "energy efficiency" are conceptually linked. According to WIPO, semantic search technologies can reduce false negatives in prior art searches by 30% to 60% compared to keyword-only methods.
The benefits are striking. For example, in September 2025, researcher Sundeep L implemented a semantic search engine using SentenceTransformers on a dataset of 2.9 million patents from Google’s patent corpus. The results? The system achieved sub-4 second query times and identified 98.3% unique patents that traditional keyword searches overlooked. Additionally, advanced embedding configurations demonstrated a 14.81% absolute improvement in Mean Average Precision compared to older methods. Embedding quantization further enhanced efficiency, enabling searches to run up to 30 times faster while using 32 times less memory.
Another major strength of semantic search is its ability to perform cross-linguistic concept matching. It identifies similar technical ideas across different languages without relying solely on translation accuracy. This capability is especially relevant in a globalized innovation landscape, as seen in the 28% year-over-year growth in AI-related patent applications reported by the European Patent Office's 2025 Patent Index. To make searches even more user-friendly, modern platforms like Patently Create now incorporate conversational AI assistants, allowing patent professionals to refine their queries interactively through dialogue.
Technical Methods Behind Semantic Embedding
Text Embedding Models
Transformer-based models play a key role in turning patent text into numerical vectors. Cutting-edge contextual models like BERT, RoBERTa, and Sentence-BERT (SBERT) excel at capturing the meaning of text by adapting to its context. This makes them especially useful for handling the complexities of patent-specific language.
Patent documents are tricky - they're packed with technical and legal terms that can vary in meaning depending on the context. For example, the word "cell" could refer to a battery component or a part of a telecommunications system. Contextual embeddings handle this challenge by analyzing how terms are used in their specific context. Transformer models are particularly adept at distinguishing these nuances.
Among these models, Sentence-BERT has proven to be a standout for patent-related tasks. The PatentSBERTa model, for instance, achieved an accuracy of 54% and an F1 score exceeding 66% in multi-label predictions of Cooperative Patent Classification (CPC) codes at the subclass level. This performance surpasses earlier state-of-the-art models. Its architecture is tailored for comparing patent claims at the sentence level, making it highly effective for identifying similarities across a vast number of patents. These detailed vector representations also facilitate clustering and dimensionality reduction, which are critical for organizing and analyzing patent data efficiently.
Clustering and Dimensionality Reduction
After embedding patents, clustering algorithms step in to group similar documents, boosting the relevance of search results. For instance, K-Nearest Neighbors (KNN) can predict CPC classification codes by examining the classifications of the most similar patents in vector space. This approach reduces the need for manual review and uncovers related technologies that might otherwise go unnoticed.
To ensure these models are performing well, researchers use benchmarks like patent interferences - cases where examiners have determined that two patent claims overlap. These serve as a ground truth for evaluating how effectively embedding models identify conceptually similar patents.
Patent-Specific Models
Generic language models often miss the mark when it comes to the nuances of patent language. That’s why specialized models like PatentSBERTa, Bert-for-patents, and Patent sBERT-adapt-ub have been developed specifically for patent applications. These models are fine-tuned on patent datasets and frequently leverage CPC classifications to better understand the unique patterns and terminology found in patent documents.
The Patent sBERT-adapt-ub model, for example, uses domain adaptation techniques to improve similarity detection. By training on millions of patents with CPC classifications, it learns the intricate vocabulary, sentence structures, and technical relationships that define patent language. This specialization enhances the accuracy of semantic search, making tasks like prior art discovery and portfolio management more efficient and precise.
How Semantic Embedding Improves Patent Workflows
Semantic embedding is changing the game for patent professionals by streamlining key workflows, making processes faster and more accurate.
Prior Art Search
Semantic embedding brings a fresh approach to prior art searches, going beyond traditional keyword-based methods. Instead of relying on manual reviews or static keyword matches, this method uses automated relevance scores to highlight patents that are conceptually similar. This helps professionals quickly identify critical "knockout" prior art - documents that might challenge the novelty of an invention - without spending excessive time or money on third-party searches. For example, semantic models can detect connections between technologies even when different terms are used, ensuring nothing important slips through the cracks. These models are rigorously tested against established benchmarks to ensure their reliability.
Technology Landscaping and Trend Analysis
Keeping up with shifting innovation trends is no small task, but semantic embedding makes it easier. By analyzing the textual similarity across entire patent portfolios, companies can monitor changes in the competitive landscape and map out innovation trends in real time. This approach replaces outdated static reports with dynamic, up-to-date insights. The resulting "technology space" can be visualized as a network, helping professionals pinpoint emerging trends and identify untapped opportunities.
Another advantage is the ability for non-experts to conduct detailed portfolio audits using natural language instead of complex Boolean queries. These insights are invaluable for making strategic decisions about patent portfolios, like spotting areas for growth or identifying potential risks.
Patent Portfolio Management
Semantic embedding doesn’t just make searching and analysis better - it also improves how companies manage their patent portfolios. By ranking patents based on how well they align with specific business goals or technical needs, companies can ensure their holdings are strategically relevant. This method also reveals connections between different entities in the innovation ecosystem, helping businesses make smarter choices about partnerships and competitive positioning.
Another standout feature is the ability to match patents across languages without needing exact translations. This multilingual capability makes it easier to track global innovation and identify potential collaborations or conflicts. Additionally, automated semantic alerts can notify professionals when new patents align with their core technologies, providing early warnings about potential infringements or new market players.
Implementing Semantic Embedding Tools
Introducing semantic embedding tools into patent search workflows requires a well-thought-out approach. This involves preparing data, selecting the right models, and setting up the necessary infrastructure. Key steps include picking suitable embedding models, configuring vector databases, and seamlessly integrating the tools into existing processes. These decisions are essential for leveraging the advanced functionalities offered by platforms like Patently.
Patently: AI-Powered Semantic Search
Patently has integrated semantic search capabilities directly into its platform using Vector AI technology. With access to over 82 million patent families and 135 million individual patents, it stands out as one of the most extensive semantic search solutions available. This integration supports a range of tasks, from prior art searches to AI-assisted drafting. For example, Patently’s Onardo tool actively searches for relevant patents while users draft patent specifications.
"Elastic is used to deliver the new Standard Essential Patent (SEP) tool, Patently License. It's even used by our AI patent drafting assistant, Onardo, to search for prior art whilst preparing a patent specification." - Jerome Spaargaren, Founder and Director, Patently
In October 2024, IP professional Laurence Brown showcased Patently’s capabilities by searching for "In-ear headphones with noise isolating tips." By filtering for Sony applications filed before 2000, the system returned 300 relevant results in under five minutes, demonstrating its speed and precision. Patently’s cloud-based architecture ensures real-time updates, so users always access the latest filings and legal events.
Selecting Models and Infrastructure
Choosing an embedding model depends on factors like budget and performance requirements. Proprietary options such as OpenAI's text-embedding-3-small ($0.02 per 1M tokens) or Google's Gemini Embedding 001 (free under certain limits) offer strong performance with minimal setup. Open-source models like BGE-M3 or Qwen3-Embedding-0.6B provide more control and can be cost-effective for larger-scale deployments.
In 2026, Sutro demonstrated the scalability of embedding tools by processing Apple Inc.'s entire patent portfolio - around 30,000 patents split into over 4 million document chunks - using the Qwen3-Embedding-0.6B model. This setup enabled millisecond retrieval times for complex queries like "battery thermal management" at a total cost of about $15.
For infrastructure, vector databases are essential for managing high-dimensional embeddings. Options include:
Pinecone: A managed platform requiring minimal operational effort.
Qdrant: A high-performance solution for self-hosted setups.
pgvector: Integrates directly with PostgreSQL for seamless database management.
Cost-saving measures, such as using Matryoshka embeddings, can significantly reduce storage and compute expenses. By compressing dimensions (e.g., from 3,072 to 256), these embeddings can cut costs by up to six times while maintaining retrieval quality.
When preparing patent documents, splitting them into chunks of 200–800 tokens ensures semantic accuracy. Recursive splitting that respects paragraph and sentence boundaries is preferable to fixed-size cuts, as it preserves the natural context of patent claims and improves search results.
After setting up models and infrastructure, thorough testing and smooth integration are critical to achieving optimal performance.
Testing and Integration
Performance validation involves metrics like recall@k and precision, tested against labeled datasets. For retrieval-augmented generation (RAG) workflows using large language models, setting the model temperature to zero ensures consistent and reproducible outputs.
Effective integration often combines semantic search with traditional filtering methods. For example, pre-filtering datasets by date, category, or jurisdiction can refine results before running vector similarity searches. Recording source attribution ensures transparency and verification of results. Additionally, standardizing query language and enabling real-time data ingestion enhance accuracy and ensure results stay up to date with the latest legal developments.
Conclusion
Semantic embedding is transforming how patent search and portfolio management are handled. By moving beyond rigid keyword matching to a concept-based approach, this method tackles the persistent issue of vocabulary mismatches. It also simplifies the process for users by allowing natural language queries instead of requiring complex Boolean strings, making patent discovery more intuitive for inventors, executives, and legal teams.
The benefits of these advancements are striking. For example, advanced embeddings deliver a 14.81% boost in Mean Average Precision compared to traditional methods, while enabling searches that are 30× faster and using 32× less memory. These improvements mean tasks that once took hours can now be completed in seconds.
Another key advantage is cross-linguistic matching. Semantic models can identify related concepts across languages without needing exact translations. For instance, a search for "brake system" can automatically bring up relevant patents in German ("Bremssystem") or Japanese, dramatically broadening the scope of discovery beyond what was possible with older techniques.
The integration of semantic search into AI-powered drafting tools adds even more value. These tools provide real-time patent insights, allowing professionals to identify prior art while drafting specifications. This reduces the risk of missing critical references. As Laurence Brown, an IP professional, aptly puts it:
AI-related patents are crucial to securing ownership over discoveries and inventions.
Looking ahead, natural language interfaces are set to make patent search more accessible, encouraging better collaboration across teams. Domain-specific models trained on patent data are continually improving their grasp of legal terminology and claim structures. By blending semantic discovery with traditional verification methods, these hybrid approaches ensure a more thorough and efficient patent analysis process.
FAQs
How do embeddings find similar patents without matching exact keywords?
Embeddings help pinpoint similar patents by interpreting the meaning and context of patent text through semantic representations. Essentially, these methods transform documents into high-dimensional vectors using advanced NLP models, like transformer-based architectures. By applying algorithms like cosine similarity to these vectors, the system can uncover patents that are conceptually related - even when they use different terms or are written in other languages. This approach enhances search precision and addresses challenges like vocabulary mismatches.
Do I need to translate foreign patents to use semantic search?
Advanced AI models, like those utilizing vector embeddings and natural language processing (NLP), make translation unnecessary for semantic search. These systems can grasp the semantic meaning of patents in various languages, allowing for efficient multilingual analysis without relying on manual translation.
What’s the best way to chunk patent text for accurate embedding search?
To get precise results with embedding search, it’s crucial to break down patent text into smaller, meaningful sections while keeping the context intact. Useful ways to segment include dividing the text by claims, abstract, description, or even finer units like paragraphs or sentences. Studies show that using domain-specific segmentation and keeping chunk sizes manageable (e.g., up to 4,096 tokens) leads to better retrieval accuracy and broader applicability. Prioritize logical divisions that maintain the overall semantic flow for the best outcomes.