How Semantic Search Transforms Patent Analysis
Intellectual Property Management
Dec 23, 2025
AI-driven semantic search uses NLP and vector embeddings to find related patents across languages, improving prior art accuracy and cutting review time and costs.

Semantic search is changing patent analysis by focusing on meaning rather than exact keyword matches. This approach uses AI and Natural Language Processing (NLP) to handle the complexities of patent language, such as synonyms, abstract terms, and contextual differences. Here’s what you need to know:
Why it matters: Traditional keyword searches miss critical results due to synonym mismatches (e.g., "wire" vs. "cable") and terminology differences across regions or fields.
How it works: Semantic search uses vector embeddings to map concepts mathematically, enabling "meaning-based" matches even with different wording.
Key benefits: Faster and more accurate prior art discovery, reduced manual review times, and multi-language search capabilities.
Real-world impact: AI models like BERT trained on patent data improve search precision, cutting patent prosecution costs by up to 30%.
Platforms like Patently leverage these tools to simplify tasks like novelty assessments, litigation support, and infringement risk analysis. By prioritizing relevance over keywords, semantic search is making patent analysis faster, more precise, and easier to navigate.
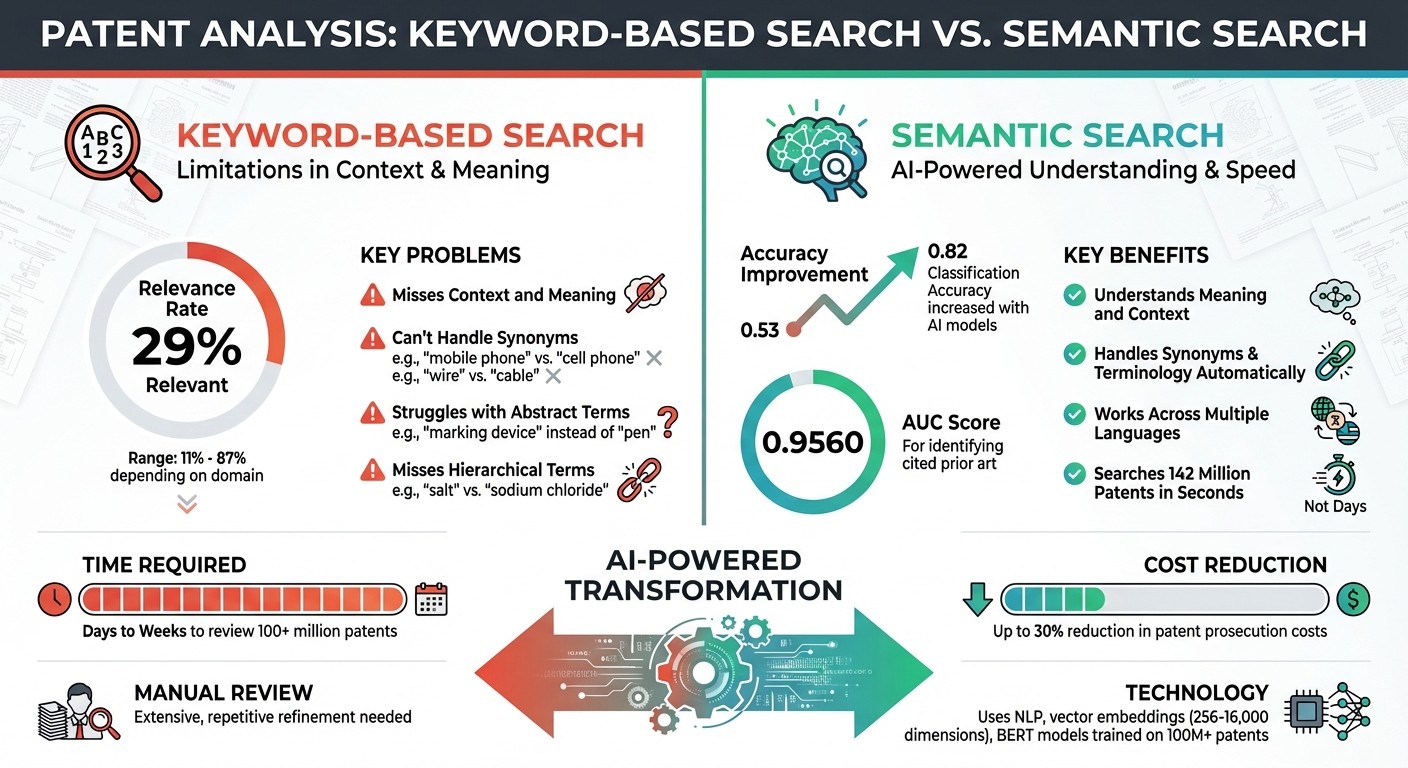
Keyword vs Semantic Patent Search: Accuracy and Efficiency Comparison
Limitations of Keyword-Based Patent Search
Missing Context in Search Results
Keyword searches rely on matching exact text, often ignoring the broader context of patent documents. As Lea Helmers and her colleagues explain:
Keyword searches often fail to return relevant documents... it is usually not possible to consider a patent application's entire text for the search, but merely query the database for specific keywords.
This creates a significant challenge: the same word can mean entirely different things depending on the field of use. Keyword searches can’t differentiate between these contexts, leading to irrelevant results and missing critical prior art.
The issue is further complicated by the abstract and broad language often used in patent drafting. For instance, instead of simply writing "pen", inventors might use terms like "marking device" to broaden the scope of their claims. While this strategy expands the protective reach of a patent, it also makes keyword searches less effective in identifying related prior art. These gaps in context lead to additional difficulties, particularly when it comes to synonym discrepancies.
Problems with Synonyms and Terminology Differences
Terminology varies across regions and technical fields, creating further obstacles for keyword-based searches. For example, Europeans might search for "mobile phones", while Americans commonly use "cell phones". Hierarchical terminology adds another layer of complexity. Arthi Krishna from the USPTO highlights this issue:
A patent application claiming a broader genus... such as 'salt' cannot be allowed where there is prior art disclosure of a narrower species... such as 'sodium chloride'.
A search for "salt" might completely overlook patents that only mention "sodium chloride", even though the terms refer to the same substance. This mismatch, often called the "vocabulary problem", prevents keyword searches from effectively bridging terminology gaps.
One study across five technology domains found that only 29% of documents retrieved through keyword searches were relevant. The relevance rate ranged from 87% for solid-state batteries to a mere 11% for electric vertical takeoff and landing (eVTOL) aircraft. Such terminology challenges leave patent professionals with no choice but to engage in time-intensive manual reviews.
Manual Review Takes Too Much Time
Because keyword searches generate a mix of irrelevant results while missing key documents, patent professionals are left with the tedious task of manual review. Rossitza Setchi and her team noted:
The most time-consuming step is sifting through the large number of patents retrieved.
Reviewing a database of over 100 million patents can take anywhere from days to weeks. Researchers also need to refine their searches repeatedly as they gain a deeper understanding of the prior art landscape. This process often involves adding new synonyms, tweaking Boolean operators, and analyzing yet another round of results. These repetitive and labor-intensive tasks highlight the inefficiencies of keyword-based searches - challenges that semantic search aims to address.
How Semantic Search Works for Patents
NLP and Concept Recognition
Patents are notorious for their specialized legal language, often difficult for the average person to understand. As Rob Srebrovic and Jay Yonamine from Google explain:
Patents are written in a highly specialized 'legalese' that can be unintelligible to a lay reader... and highly context dependent.
Traditional indexing methods, which simplify words to their base forms, struggle to link terms like "autonomous vehicle" and "self-driving car". This is where Natural Language Processing (NLP) steps in. Techniques like tokenization and parsing help extract meaning from both structured and unstructured patent data, including PDFs and dense technical descriptions. Models specifically designed for scientific and technical texts, like SciBERT, outperform general-purpose NLP models because they are better equipped to handle the nuanced terminology found in patents. For instance, Google trained a BERT model on more than 100 million patent publications, vastly improving its ability to identify relevant prior art. These advanced linguistic tools are key to mapping patent concepts into complex, multi-dimensional spaces.
Vector Embeddings for Concept Mapping
Vector embeddings convert the content of patents into numerical representations, capturing their semantic meaning in a multi-dimensional space. This approach shifts away from exact word matching to "meaning-based" matching, enabling the discovery of related prior art even when different terms are used. For example, patents addressing similar technical challenges are positioned closer to one another in this vector space, regardless of the specific language used by inventors.
These embeddings can range in complexity, from 256 to as many as 16,000 dimensions, with higher dimensions capturing more intricate technical details. To measure how closely two patent concepts align, systems use mathematical tools like cosine similarity, which calculates the angle between vectors. Since comparing a query vector against an entire database is computationally demanding, Approximate Nearest Neighbor algorithms are employed to search through millions of patents in milliseconds. For instance, matching 10,000 sentences might involve 50 million computations with a standard BERT model. To streamline this process, specialized models like Sentence-BERT are used to create embeddings that are both efficient and easy to search.
AI Models That Learn and Improve
Semantic search systems are designed to adapt and improve over time, making them increasingly effective for uncovering prior art in the ever-changing world of patents. These systems learn from user interactions, such as clicks and query adjustments, to enhance relevance rankings. Additionally, fine-tuning on massive datasets like USPTO-2M and USPTO-3M enables these models to better understand patent-specific terminology. The impact is clear: fine-tuning Pretrained Language Models like BERT and RoBERTa for patent data has boosted classification accuracy from 0.53 to 0.82.
As new patents and research papers are published, they are added to the vector space, allowing the system to incorporate emerging terms and map them to existing concepts. Feedback from patent examiners also plays a crucial role, helping refine search queries and improve the accuracy of novelty assessments. This ongoing learning process ensures that semantic search systems become faster and more precise as they process larger volumes of patent data.
Patent Analysis: The once and future discipline
Benefits of Semantic Search for Patent Analysis
Semantic search has proven to be a game-changer in patent analysis, addressing challenges like synonym mismatches and contextual gaps. Its advantages span improved accuracy, faster results, lower costs, and the ability to work seamlessly across multiple languages.
More Accurate Prior Art Discovery
One of the standout benefits of semantic search is its ability to uncover prior art with greater precision. Unlike traditional keyword searches, which often stumble when different terms are used for the same concept (like "wire" versus "cable"), semantic search understands the relationships between ideas rather than just matching words.
Studies have shown that using advanced language models like BERT and RoBERTa significantly boosts accuracy in patent-related tasks, with precision levels jumping from 0.53 to 0.82. When it comes to full-text similarity searches, semantic analysis achieves an impressive Area Under the Curve score of 0.9560 for identifying cited prior art. As highlighted by Lea Helmers and her team in PLOS ONE:
By considering the entire texts of the documents, much more information, including the context of keywords used within the respective documents, is taken into account.
This deeper understanding reduces the chances of missing critical prior art or flagging irrelevant results due to terminology differences. The outcome is a more comprehensive and reliable search process, which also translates into saving time and cutting costs.
Reduced Time and Costs
The sheer volume of patent data is staggering - over 100 million published patent applications exist globally, with each document averaging around 10,000 words of dense legal and technical language. The real challenge isn’t running the search but sifting through this massive database to find relevant information.
Semantic search simplifies this process by prioritizing results based on conceptual relevance instead of mere keyword frequency. This allows professionals to input natural language queries while the AI takes care of the heavy lifting. As Rahul Bhattacharya from Effectual Knowledge Services explains:
What a researcher loses in terms of transparency... they gain in terms of the intrinsic relationship extracted between the concept and the documents.
With access to approximately 142 million patent documents, semantic tools can process complex queries within seconds - tasks that traditionally took days or even weeks. This efficiency not only speeds up the research process but also reduces the risk of litigation by ensuring more thorough prior art discovery.
Search Across Multiple Languages
Semantic search also eliminates language barriers, making global patent analysis more accessible. For instance, an inventor in Germany might describe a concept differently than a researcher in Japan, but semantic tools align these equivalent ideas across languages automatically.
Google, for example, trained a BERT model on over 100 million patent publications from various countries, enabling the system to grasp the nuances of legal and technical language across jurisdictions. Rob Srebrovic and Jay Yonamine from Google Cloud emphasize this complexity:
The patent corpus is large... complex... unique... and highly context dependent (many terms are used to mean completely different things in different patents).
Modern semantic tools also tackle synonyms effortlessly, recognizing that terms like "autonomous vehicles" in English might correspond to equivalent phrases in other languages. This capability eliminates the need for manual translations and ensures that patent searches are truly global, leaving no relevant prior art undiscovered.
Practical Uses of Semantic Search in Patent Work
Semantic search isn't just a theoretical upgrade - it's transforming the way patent professionals tackle critical tasks. Whether it's assessing the novelty of an invention or defending against infringement claims, AI-driven search tools are proving their worth in scenarios where precision and speed are crucial. By addressing the shortcomings of traditional keyword searches, these tools are reshaping the landscape of patent analysis.
Novelty and Patentability Assessments
Determining whether an invention is truly new - and therefore eligible for patent protection - requires combing through massive patent databases. Traditional keyword searches often fall short because inventors and examiners may describe the same concepts using entirely different terms. Semantic search bridges this gap by focusing on the relationships between ideas rather than just matching specific words.
This is achieved through technologies like Named Entity Recognition (NER) and knowledge graph construction, which identify connections between concepts, even when documents use different terminology. Freederia Research explains it well:
The cornerstone technologies employed are Named Entity Recognition (NER), relation extraction, and knowledge graph construction... searching a knowledge graph is fundamentally different than a keyword search; it allows finding articles discussing concepts related to a patent application, even if those articles don't use the exact same terminology.
This approach is especially useful because patent drafters often use abstract or vague terms to broaden the scope of their protection, making it harder for simple keyword searches to detect relevant prior art. By analyzing the full text of patent documents, semantic search provides a more thorough similarity assessment. Research supports this claim, showing that these systems can achieve an Area Under the Curve (AUC) score exceeding 0.9 in identifying relevant prior art. This level of precision strengthens the foundation for defending patents or challenging their validity in legal disputes.
Opposition and Litigation Support
When it comes to contesting the validity of a patent or defending against infringement claims, finding the right prior art can be the deciding factor in a case. Semantic search has proven to be a powerful tool in uncovering evidence that traditional search methods might miss.
For example, a study on biotechnology patent litigation highlighted how semantic analysis could have flagged conflicts earlier by analyzing around 4,000 patents within US Class 435/6 using multi-dimensional scaling. Modern AI tools can now compare patent claims with prior art to determine if all elements of a claim are present in earlier documents, helping to structure compelling arguments. These tools can even extract specific paragraphs from "Non-Final Rejection" documents that were previously used as grounds for rejection, offering strong evidence in litigation cases.
As noted in World Patent Information, this approach significantly reduces the workload:
The study suggested that AI... can reduce the time and cost of the process of sifting through a large number of patents.
Such capabilities are invaluable for legal teams conducting infringement risk assessments or defending intellectual property rights.
Infringement Risk Analysis
Before launching a new product or filing a patent application, companies must evaluate whether they risk infringing on existing patents. Semantic search enhances this process by identifying potential conflicts that traditional keyword searches might miss, often due to differences in terminology or the use of abstract language.
Semantic search employs full-text contextual analysis, comparing entire patent documents rather than isolated keywords. This helps uncover technical nuances and reduces the chance of overlooking relevant patents. Advanced systems also utilize knowledge graphs to map out indirect relationships between technical concepts, enabling a form of "reasoning" to identify patents that may be relevant even if they don't explicitly state so. As Helmers and colleagues caution in PLOS One:
False negatives may lead to an erroneous grant of a patent, which can have profound legal and financial implications for both the owner of said patent as well as competitors.
For companies managing extensive patent portfolios, semantic search can organize and index content to reveal connections between specific projects, products, and existing intellectual property. This allows for more detailed risk assessments. Some systems even integrate visual analysis alongside textual data to identify potential risks in both utility and design patents. Together, these capabilities ensure a comprehensive approach, making semantic search a game-changer in patent analysis.
Patently: Semantic Search with Vector AI
Traditional patent search methods have their limits, and that's where platforms like Patently step in, leveraging semantic search to transform how patent professionals work. Patently, an AI-driven platform, uses Vector AI to power its search capabilities, handling a massive database of 82 million patent families, 135 million patents, and 226 field mappings. By combining semantic search technology with advanced tools, Patently offers a robust solution for patent analysis.
Vector AI for Context-Aware Search
Patently's Vector AI takes search to the next level by understanding full sentences, allowing users to conduct searches in natural, conversational language. With Elastic's Search AI and vector search capabilities, the platform can interpret complex data relationships, delivering relevant results even when there's no exact keyword match. Andrew Crothers, Creative Director at Patently, compares the system to having a seasoned patent attorney guiding every search:
With Elastic, it's like having a patent attorney with decades of experience guiding every search.
In October 2024, an IP professional used Patently to quickly identify key patents for "In-ear headphones with noise isolating tips." By applying a priority date filter, they narrowed 300 results down to specific Sony applications in under five minutes. The platform’s transition from monthly updates to real-time processing ensures users always have access to the latest patent filings.
Collaboration and Workflow Tools
Patently doesn’t stop at search - it also enhances teamwork with integrated workflow tools. The Forward & Backward (FAB) browser helps users navigate through generations of citations, automatically removing duplicates at the family level. Meanwhile, the C-Tree visualization tool graphically maps priority claims and relationships within a patent family. Teams can organize their work by marking important assets, tagging items, and adding comments at various stages to keep reviews on track.
The platform also builds "Genetic families" using proprietary algorithms developed over a decade, creating custom patent family structures directly from leading patent offices. Stan Zurek, Head of Research and Innovation at Megger Instruments, highlights its importance:
Patently has become an indispensable tool for us, playing a crucial role in various aspects of our Research and Innovation processes.
SEP Analytics and Custom Features
For those working with Standard Essential Patents (SEPs), Patently offers Patently License, a tool designed specifically for SEP data analysis. This feature relies on the same semantic search engine that powers the rest of the platform. Another standout feature is Onardo, an AI drafting assistant that simplifies prior art searches and patent drafting. Jerome Spaargaren, Founder and Director of Patently, underscores the impact of these tools:
This powerful addition [Vector AI] has positioned Patently as one of the most innovative platforms for semantic patent search and is core to our technology stack.
Patently brings together and cleans data from multiple sources into a single, streamlined interface. It flags ambiguities, highlights critical issues, and allows users to sort results using custom metrics like family size, in-force member count, or forward citation counts. This flexibility helps users prioritize their analysis based on specific project goals.
Conclusion
Semantic search has transformed the way patent analysis is conducted, moving beyond simple keyword matching to a deeper, context-driven understanding. By leveraging technologies like natural language processing (NLP) and vector embeddings, these AI-powered systems can interpret the meaning behind complex patent "legalese" and technical concepts, no matter how they are phrased or structured.
The efficiency gains are staggering. Full-text similarity methods now achieve AUC scores exceeding 0.9, while tasks that once required patent examiners to spend days combing through over 100 million published applications can now be completed in just a matter of hours. Additionally, cross-language capabilities enable seamless analysis across jurisdictions, bridging linguistic barriers automatically. As Rahul Bhattacharya from Effectual Knowledge Services aptly puts it:
Semantic searching can help a user to dig through information and find connections that they might not otherwise have realised existed.
These advancements are seamlessly integrated into cutting-edge platforms like Patently, which combine semantic search with tools for collaboration, citation browsing, and SEP analytics. Such platforms not only streamline patent management but also empower users with real-time insights and a more connected understanding of the patent landscape.
FAQs
How does semantic search enhance patent analysis compared to traditional keyword searches?
Semantic search leverages advanced Natural Language Processing (NLP) to grasp the context and deeper meaning within patent documents. Rather than depending solely on exact keyword matches, it transforms patents into contextual vectors. This allows the system to detect conceptually similar content, even when varied terminology is used.
By doing so, it enhances the accuracy of patent analysis in two key ways: improving precision (finding more relevant results) and boosting recall (reducing the chances of missing important documents). This method helps professionals uncover meaningful insights, streamline the process of prior art discovery, and save considerable time during patent research.
How does Natural Language Processing (NLP) improve semantic search for patents?
Natural Language Processing (NLP) takes the complexity of patent text and turns it into data that's easier to search and understand. With tools like BERT and large-scale transformers, NLP dives into the context, synonyms, and technical jargon of patents. This means searches can focus on the ideas behind the text, not just the exact words. The result? More precise and relevant matches for tasks like finding prior art or classifying patents.
What’s more, modern NLP models generate dense vector embeddings for patents. These embeddings allow for lightning-fast comparisons, pinpointing similar inventions in seconds. Compared to older keyword-based methods, this approach delivers much better accuracy when uncovering related technologies. Platforms such as Patently use NLP to help patent professionals explore technology landscapes, find relevant prior art, and work more efficiently - all with less hassle.
How does semantic search simplify multilingual patent analysis?
Semantic search revolutionizes the way patents are analyzed across different languages by focusing on the meaning of the text rather than exact wording. Using advanced AI models trained on millions of patents from regions like the United States, Europe, Japan, and China, this method transforms text into a shared vector space. This shared space captures meaning in a way that's independent of language, making it possible to match English queries with patents written in languages like German or Japanese - no translation required.
Here’s how it works: First, the full text of each patent is converted into a dense vector representation using a multilingual AI model. Next, the same model processes the user’s query - whether it’s a phrase, an example patent, or a natural-language question - into a query vector. Finally, the system compares this query vector to the patent vectors, ranking results based on semantic similarity instead of relying on keyword matches. This method ensures that even nuanced technical concepts are identified, breaking down language barriers and streamlining the search for prior art.
Patently takes full advantage of this technology, offering a Vector AI-powered search engine that lets users query in English while instantly retrieving relevant patents in other languages. This not only reduces the chances of missing critical references but also eliminates the time and effort spent on manual translation.