Semantic Vector Search: How It Transforms Patent Databases
Intellectual Property Management
Dec 20, 2025
How semantic vector search converts patent text into embeddings to find conceptually similar patents, improving prior-art, FTO, and claim drafting.

Semantic vector search revolutionizes how patents are searched by focusing on meaning instead of exact keywords. Using machine learning, it converts text into numerical vectors that represent concepts, enabling the discovery of relevant patents even when different terminology is used. For example, searching for "autonomous vehicles" also retrieves results for "self-driving cars."
Key Takeaways:
How it works: Transforms patent text into vectors stored in databases, compared using metrics like cosine similarity.
Why it’s better: Identifies conceptually similar patents, solving issues like obscure language or keyword ambiguity in traditional searches.
Applications:
Prior Art Searches: Finds related patents regardless of wording differences.
Freedom-to-Operate (FTO): Identifies potential infringement risks by uncovering semantically related claims.
Claim Drafting: Integrates prior art insights to improve the quality and uniqueness of patent claims.
Tools: Models like BERT and fastText generate embeddings, while vector databases use algorithms like HNSW for efficient searches.
By enabling more accurate and efficient patent searches, semantic vector search addresses challenges posed by the growing complexity and volume of patent data.
NODES 2024 - Building Knowledge Graphs with LLMs from USPTO Patent Data
How Semantic Vector Search Works
How Semantic Vector Search Works in Patent Databases: 3-Step Process
Embeddings and Vectors Explained
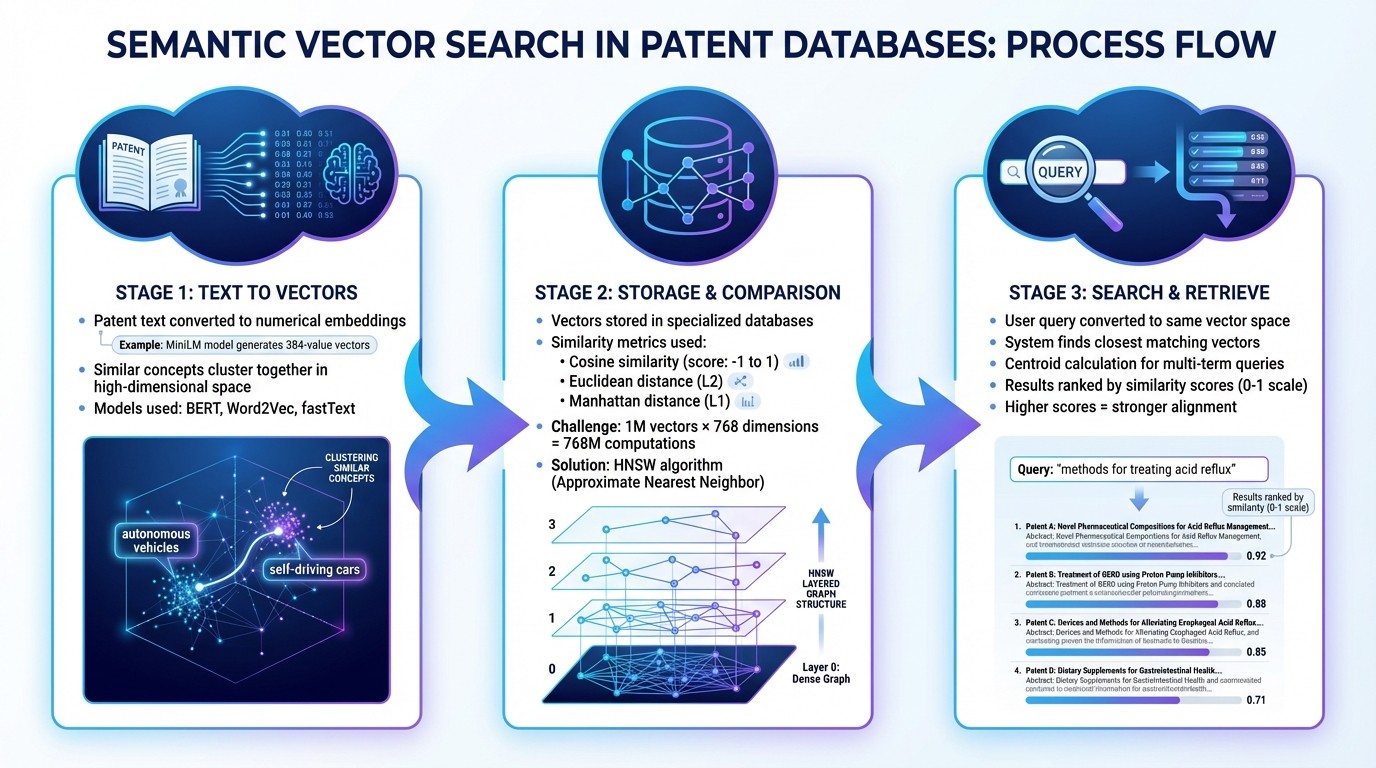
Semantic search transforms patent text - like claims, abstracts, or technical descriptions - into embeddings, which are essentially numerical representations capturing meaning and context. These embeddings are stored as numeric vectors in a high-dimensional space, where each dimension reflects a specific feature or characteristic of the patent data, such as technical tone or functional details. For instance, a MiniLM model generates vectors with 384 values each. In this space, similar ideas naturally cluster together, even if different words are used. For example, a patent discussing "autonomous vehicles" would be positioned near one about "self-driving cars" because their vectors align closely.
To create these embeddings, models like BERT, Word2Vec, or fastText are used, as they effectively capture relationships between technical terms. In 2019, researchers at the United States Patent and Trademark Office (USPTO) - including Arthi Krishna and Ye Jin - trained fastText models on patent data spanning 2001 to 2018 using AWS m5.12xlarge instances. Their work focused on fields like Immunology (Workgroup 1640) and Optics, demonstrating that domain-specific corpora can identify relevant query expansions that general-purpose models might overlook. For example, in optics, the models accurately identified related terms for "lens", such as "refracting", "focal", and "aspheric." By training models on specific patent categories - using Cooperative Patent Classification or Art Units - the system resolves ambiguities, distinguishing between terms like "mold" in microbiology versus "mold" in 3D printing.
Once converted into embeddings, patents are stored and compared efficiently within vector databases.
Vector Databases and Similarity Metrics
After patent documents are converted into vectors, they are stored in specialized vector databases optimized for fast similarity searches. These databases rely on mathematical metrics to measure the distance between a query vector and stored patent vectors.
One widely used metric is cosine similarity, which calculates the angle between two vectors and ranges from –1 to 1. A score of 1 indicates perfectly aligned vectors, while 0 means they are orthogonal.
IBM researchers Meredith Syed and Erika Russi explain, "Cosine similarity is particularly useful when dealing with vectors, as it focuses on the directional relationship between vectors rather than their magnitudes".
Other metrics include Euclidean distance (L2), which measures the straight-line distance between points, and Manhattan distance (L1), which sums the absolute differences across dimensions. Each metric has specific strengths - Euclidean distance works best for lower-dimensional vectors, while Manhattan distance is often preferred for high-dimensional, feature-rich data.
Searching through millions of vectors can be computationally demanding. For example, querying 1 million vectors with 768 dimensions requires 768 million computations. To address this, vector databases use Approximate Nearest Neighbor (ANN) algorithms. A popular ANN method, HNSW (Hierarchical Navigable Small World), organizes vectors into layered graphs, enabling the system to quickly "jump" through the data and find the closest matches without examining every vector.
Elastic explains, "ANN sacrifices perfect accuracy in exchange for executing efficiently in high dimensional embedding spaces, at scale".
Query Processing and Patent Retrieval
With vectors stored and similarity metrics in place, the system processes user queries by converting them into the same vector space. Whether you input a natural language query (like "methods for treating acid reflux"), a technical description, or claim text, the system uses the same embedding model to transform your input into a vector. This ensures that both the query and the patents are represented in the same mathematical framework. The system then identifies the vectors closest to your query.
IBM describes this process: "Vector search represents data as dense vectors... in a continuous vector space. Each dimension of the dense vector corresponds to a latent feature or aspect of the data".
For more complex queries, the system calculates a centroid from the vectors of individual words, retrieving the most relevant patents. A USPTO study showed that combining terms like "lens", "optic", and "microlens" into a centroid improved F1 accuracy in search results as additional terms were added. This method is especially effective for prior art searches, where similar innovations may be described using varied terminology.
Search results are ranked based on similarity scores, typically ranging from 0 to 1. Higher scores indicate stronger alignment with the query's intent. This allows semantic search to go beyond simple keyword matching, delivering results that are conceptually relevant even when the language differs.
How Semantic Vector Search Improves Patent Workflows
Semantic vector search is reshaping how patent professionals handle their most challenging tasks. Instead of spending hours crafting complex Boolean queries, they can now describe inventions in plain language and quickly retrieve conceptually similar patents. This technology significantly impacts three key areas: prior art searches, freedom-to-operate (FTO) analysis, and claim drafting.
Better Prior Art and Novelty Searches
Traditional keyword searches often fall short when different terminology is used to describe similar concepts. For example, a keyword search for "autonomous vehicles" might miss patents referring to "self-driving cars." Semantic search bridges this gap by identifying conceptual matches, helping uncover "near-miss" prior art that could otherwise jeopardize a U.S. provisional filing later on.
In October 2024, IP professional Laurence Brown used Patently Vector AI to search for "In-ear headphones with noise isolating tips." By applying filters for patents filed before 2000 and narrowing results to Sony applications, the tool delivered 300 relevant results. This was achieved using relevance-based sorting powered by Elastic Search AI.
Jerome Spaargaren, Founder and Director of Patently, shared: "Vector AI... has positioned Patently as one of the most innovative platforms for semantic patent search and is core to our technology stack. It's even used by our AI patent drafting assistant, Onardo, to search for prior art whilst preparing a patent specification."
Patently’s constantly updated database ensures novelty searches include the latest filings, a crucial feature for evaluating invention disclosures during early-stage reviews.
Improved Freedom-to-Operate (FTO) and Infringement Analysis
Semantic vector search also transforms legal risk assessments, such as freedom-to-operate analysis. This process involves identifying patents that could pose infringement risks for launching a product in the U.S. Missing a critical patent can lead to delays or litigation. By analyzing patents based on their semantic relationships, this approach uncovers conceptually similar claims even when different vocabulary is used.
For example, K-Nearest Neighbors (KNN) algorithms locate vectors closest to the search term, enabling users to find patents related to "autonomous vehicles" even when the query specifies "self-driving cars". Combining semantic search with traditional filters like dates, assignees, and classifications refines results into a legally actionable list. Additionally, grouping related patents into families prevents redundant reviews of the same invention across jurisdictions.
Stan Zurek, Head of Research and Innovation at Megger Instruments, emphasized: "In the cutting-edge world of electrical testing, staying ahead of the curve is essential. Patently has become an indispensable tool for us, playing a crucial role in various aspects of our Research and Innovation processes."
Faster Claim Drafting and Quality Checks
Semantic search doesn’t just improve searches - it also speeds up the drafting process. By integrating real-time prior art insights, drafting teams can input entire disclosures or draft claims into semantic search engines to find contextually similar patents, eliminating the need for complex Boolean strings. Modern AI drafting assistants, like Onardo, incorporate prior art retrieval directly into the process, ensuring claims align with the current technological landscape.
This seamless integration streamlines the entire workflow, from research to drafting.
Andrew Crothers, Creative Director at Patently, noted: "With Elastic, it's like having a patent attorney with decades of experience guiding every search."
Drafting teams use similarity scores to prioritize results, focusing on patents with the highest semantic proximity to their invention. This method not only improves the quality of claims but also ensures they stand out from prior art, enhancing both clarity and differentiation.
How to Use Semantic Vector Search Effectively
Semantic vector search can transform complex patent searches into a more efficient and insightful process. To get the most out of it, focus on crafting precise queries, applying filters thoughtfully, and understanding how to interpret the results.
Writing Effective Queries
Use full sentences to describe your invention instead of relying on isolated keywords. For example, rather than searching for "autonomous vehicle sensor", try something like, "A vehicle navigation system that uses radar sensors to detect obstacles and adjust speed automatically." This approach captures the relationships between components that single keywords often miss.
Combine multiple related terms to refine your search for niche concepts. The system calculates a centroid from these terms, helping it zero in on the conceptual center of your query. For instance, grouping terms like "lens", "optic", and "microlens" can steer results toward more specific concepts such as "GRIN", "lenslet", or "fresnel." A study across 11 technical fields showed this method significantly improved search accuracy (F1 scores) from 0.0839 to 0.609 after incorporating expert feedback.
Balance broad and specific terminology to increase recall. Patent language often mixes general terms (hypernyms) with more specific ones (hyponyms). For example, when researching "3D printing", include related terms like "stereolithography" or "additive manufacturing" to ensure you cover all relevant prior art. Be mindful to add enough context when a term could have multiple interpretations.
Once you’ve crafted a strong query, you can refine your results further using metadata and filters.
Refining Results With Metadata and Filters
Start with priority date filters when performing novelty searches. Exclude patents filed after your invention date to focus on relevant prior art.
Layer filters thoughtfully to strike a balance between breadth and precision. Begin with a semantic search to find conceptual matches, then narrow the results using filters like jurisdiction, assignee, or classification. For instance, in a freedom-to-operate analysis, filtering by country code can highlight patents enforceable in your target market, while filtering by assignee can help with competitive intelligence.
Sort results using influence metrics instead of relying solely on similarity scores. After retrieving relevant patents, reorder them based on factors like forward citation count or family size. For example, platforms like Patently offer up to 226 distinct field mappings, enabling granular filtering.
Understanding Similarity Scores and Results
Interpreting similarity scores is key to assessing how closely retrieved patents align with your query.
Similarity scores reflect conceptual distance, not just keyword overlap. Tools like Patently calculate cosine similarity between your query vector and patent document vectors in a multi-dimensional space. While higher scores generally indicate closer alignment, consider the broader context of your search.
Provide detailed input for accurate scoring - a full claim, abstract, or technical disclosure works best. This ensures a more reliable assessment of similarity. Once you review the initial results, features like "More Like" allow you to re-rank the database based on a particularly relevant document's profile.
Combine automation with manual review for thoroughness. While AI tools can reduce search time by 40–60%, manual validation often identifies 30–50% of references that automated searches might overlook. Pairing automated retrieval with manual checks - and using citation network analysis to explore forward and backward citations - can help uncover foundational prior art that uses different terminology. These similarity scores play a crucial role in ranking results, ensuring the most relevant documents appear at the top.
Conclusion
Semantic vector search is changing the game for patent professionals, offering a more intuitive and effective way to conduct searches. By eliminating the need for intricate Boolean queries, this approach allows you to use natural language to find relevant prior art - even when it's described with completely different terminology. It’s a system that understands the meaning and context behind your search, uncovering connections that traditional methods often overlook.
Beyond just speeding up the process, semantic vector search brings more thorough results. It reduces the chances of missing key references, strengthens freedom-to-operate analyses, and helps craft more solid patent applications. When combined with tools like metadata filters and family-based grouping, it creates a workflow that’s not only efficient but also covers all the bases.
Patently makes it easier to stay ahead in a competitive intellectual property world that values both accuracy and speed. By focusing on meaning rather than just matching words, this technology bridges the gap between how inventors describe their innovations and how prior art is recorded. The real question is: how soon will you embrace semantic vector search to maintain your edge in this ever-evolving patent landscape?
FAQs
What makes semantic vector search different from traditional keyword search in patent databases?
Semantic vector search leverages advanced AI to transform patents and search queries into numerical embeddings, enabling it to grasp the underlying meaning and context of the words. Instead of just looking for exact matches, this approach ranks results based on semantic similarity, which means it can identify relevant patents even when they use entirely different terms to express the same idea.
On the other hand, traditional keyword search focuses on matching exact words or their stems from a pre-indexed database. While this method works well for straightforward searches, it often overlooks results that describe the same concept using different phrasing. Semantic search fills this gap, offering a more effective way to uncover nuanced connections and deeper insights within patent data.
How do models like BERT and fastText enhance semantic vector search for patent databases?
Models like BERT and fastText are essential tools in semantic vector search. They create dense vector embeddings of patent text, which represent the meaning and context of words. This approach allows the search system to identify related documents based on conceptual similarity, rather than just matching exact keywords.
Using these advanced models, semantic vector search reveals deeper relationships between patents, making it easier for professionals to navigate complex databases with greater accuracy and relevance.
How does semantic vector search enhance the patent claim drafting process?
Semantic vector search transforms the way claims are drafted by focusing on the meaning behind prior-art documents rather than just matching exact keywords. It works by turning a draft claim or natural-language input into a vector, enabling the system to find patents with related concepts - even when different terminology is used. This approach helps patent professionals uncover critical references that might otherwise go unnoticed, offering a broader and more accurate understanding of the innovation landscape.
Patently’s advanced Vector AI engine takes this capability to the next level. Users can input full-sentence queries, and the system automatically groups related patent families. This makes it easier to refine claim language, pinpoint overlapping elements, and spot features that could potentially block novelty - all within seconds. The outcome? Drafting becomes quicker, revisions are minimized, and claims are crafted to be both novel and precise, reducing the likelihood of rejections.