Transfer Learning for Patent Vectorization: SEP Applications
Intellectual Property Management
May 4, 2026
Transfer learning fine-tunes models to vectorize SEPs for faster, accurate patent similarity, classification, and portfolio analysis.

Transfer learning is transforming how patents, especially Standard Essential Patents (SEPs), are analyzed. By leveraging pre-trained models and fine-tuning them for patent-specific tasks, this method simplifies the complex process of converting legal and technical documents into numerical vectors. These vectors enable semantic searches, helping identify similar patents and uncover relationships between technologies.
Key highlights:
Patent Vectorization: Converts patent text into numerical data for semantic analysis.
SEPs: Patents linked to technical standards like 5G or WiFi, requiring precise legal and technical analysis.
Transfer Learning Benefits: Reduces training data needs, improves accuracy, and speeds up tasks like patent classification and clustering.
Advanced Models: Tools like PatentSBERTa and PaECTER enhance document similarity analysis and prior art searches.
Practical Applications: AI-powered platforms now integrate these advancements, making SEP portfolio management faster and more reliable.
These advancements are reshaping SEP analytics, making it easier to handle the complexity of patent portfolios and evaluate licensing opportunities.
Core Techniques in Patent Vectorization
Patent vectorization plays a crucial role in analyzing Standard Essential Patents (SEPs), transforming complex legal and technical texts into numerical data. To refine this process, transfer learning has emerged as a key approach. But before diving into its impact, it’s important to understand the primary methods behind patent vectorization and the challenges they face.
Document Embedding Techniques
Early methods like Word2Vec and Doc2Vec laid the groundwork for patent analysis. Word2Vec's Skip-gram model, for instance, identifies word relationships within a limited context. However, its inability to handle the intricate language of patents limits its effectiveness.
Modern approaches leverage contextual word embeddings through transformer models such as BERT, SciBERT, and BERT for Patents. These models use attention mechanisms to analyze how a word's meaning shifts depending on its context. For patent-specific tasks, specialized models have been developed:
PatentSBERTa: A hybrid model designed for tasks like patent classification and distance measurement.
PaECTER: Fine-tunes BERT for Patents by incorporating examiner citation data. Using contrastive triplet loss, it distinguishes between similar and dissimilar patents, achieving a Mean Average Precision of 68.17, compared to 60.32 for standard BERT for Patents.
The vectorization process involves tokenizing and stemming text to standardize word forms. The processed text is then passed through transformer models to generate high-dimensional vectors. These vectors are mapped into a multi-dimensional space where related patents cluster together. Interestingly, mean pooling of output tokens has been shown to outperform the [CLS] token for similarity tasks.
These embeddings form the backbone of analytical methods like cosine similarity, which is discussed next.
Using Cosine Similarity for Patent Analysis
Cosine similarity builds on these embedding techniques to measure relationships between patent vectors. By calculating the angle between two vectors, cosine similarity quantifies how closely patents are related. A smaller angle indicates a higher similarity, which is particularly useful for identifying prior art.
Advanced models like Pat-SPECTER enhance this capability by comparing patents with scientific publications. Using Patent-Paper Pairs, these models trace the flow of knowledge from academic research to commercial technologies. One study examining 52,696 DocDB families revealed a median time lag of eight years between a cited scientific paper and the corresponding patent.
Additionally, integrating Subject-Action-Object (SAO) structures significantly improves retrieval accuracy - 43% better than keyword-based methods and 26% better than standard document embedding techniques. For large-scale datasets, algorithms like K-Nearest Neighbors (KNN) or Approximate Nearest Neighbor (ANN) efficiently identify similar patents once vectorization is complete.
Limitations of Standard Vectorization Methods
While these methods are powerful, they aren’t without their flaws. Token limits (512 tokens) and limited vocabulary overlap - only 50% between SciBERT and BERT for Patents - restrict the ability to fully capture patents' technical details. This is especially problematic for SEP analysis, where precision is critical. Moreover, models like BERT, originally trained to predict masked tokens, weren’t specifically designed for document similarity tasks, which are central to prior art searches.
Performance metrics highlight these gaps. For instance, traditional Word2Vec embeddings scored just 23.3 on certain similarity tasks, while eigenvector-based methods achieved a much higher score of 83.37. In SEP analytics, these limitations can lead to missed prior art, suboptimal patent grants, and increased risks of litigation or opposition proceedings.
How Transfer Learning Improves Patent Vectorization
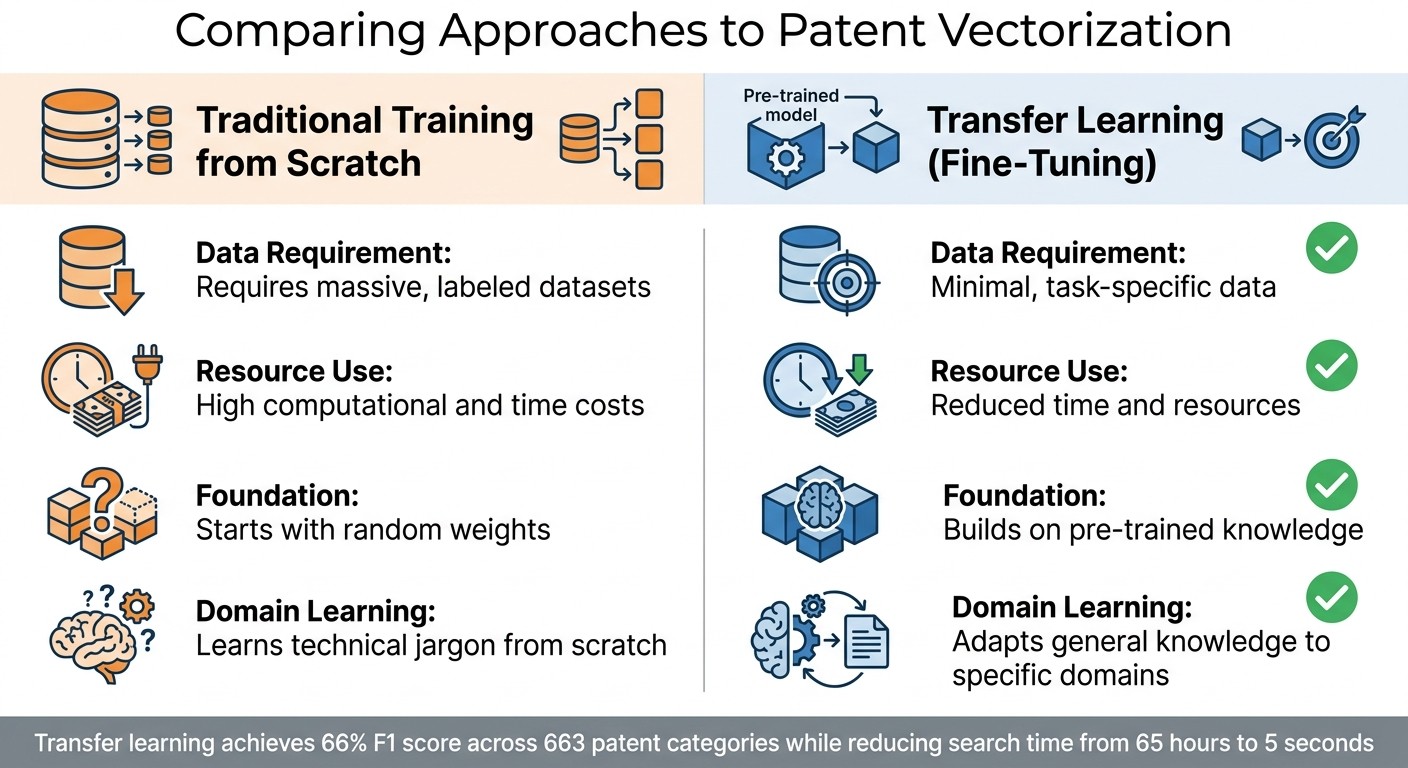
Traditional Training vs Transfer Learning for Patent Vectorization
Transfer learning addresses the limitations of standard vectorization by utilizing pre-trained models tailored to the specific language of SEPs (Standard Essential Patents). Instead of relying on millions of labeled examples, this method fine-tunes existing models with smaller, domain-specific datasets. This allows the system to grasp both general language patterns and the technical jargon unique to standards documents.
"Transfer learning... leverages pre-trained models to solve new, related problems with minimal data and computational resources." – Meegle
This approach lays the groundwork for fine-tuning techniques that adapt models for patent-related tasks.
Fine-Tuning Pre-trained Models for SEPs
Models like BERT are excellent at understanding general language but often struggle with the specialized vocabulary found in SEPs. Fine-tuning resolves this by retraining the final layers of these models using patent-specific datasets. For example, PatentSBERTa fine-tunes SBERT with supervised patent claims through Siamese networks. This process has achieved an F1 score of 66% for Cooperative Patent Classification across 663 categories while reducing search times dramatically - from 65 hours to just 5 seconds.
Reducing Training Data Requirements
Traditional machine learning models typically need vast amounts of labeled data to perform well. Transfer learning, however, bypasses this hurdle by applying knowledge from general text analysis to patent-specific tasks. For instance, PatentSBERTa demonstrates how this method can achieve effective results with significantly less data compared to training a model from scratch.
Feature | Traditional Training from Scratch | Transfer Learning (Fine-Tuning) |
|---|---|---|
Data Requirement | Requires massive, labeled datasets | Minimal, task-specific data |
Resource Use | High computational and time costs | Reduced time and resources |
Foundation | Starts with random weights | Builds on pre-trained knowledge |
Domain Learning | Learns technical jargon from scratch | Adapts general knowledge to specific domains |
By reducing the need for extensive data collection, transfer learning accelerates training and improves tasks like patent classification and clustering.
Better Patent Classification and Clustering
Transfer learning also enhances how SEP portfolios are organized and analyzed. Advanced workflows now use section-aware extraction techniques to maintain the hierarchical structure of standards like 3GPP 5G specifications. This ensures the normative scope and interdependencies of standards documents are preserved, resulting in more accurate clustering of related patents.
Modern systems are moving beyond simple text analysis by incorporating multi-modal extraction. This includes parsing tables, mathematical equations (using LaTeX), and technical diagrams from standards documents. Such comprehensive methods enable more precise essentiality ratings, categorizing SEPs as Normative (explicitly required), Implied (naturally satisfying requirements), Informative (described but optional), or Contextual (indirectly relevant). Additionally, combining transfer learning with section-aware analysis supports a dual-index architecture. This system stores canonical metadata in a structured database while leveraging section-level vector indexing for high-recall retrieval.
Advanced Models for Patent Vectorization
Sentence-BERT for Patent Analysis
Sentence-BERT (SBERT) simplifies similarity comparisons by creating fixed-size embeddings. Unlike the original BERT, which processes every document pair individually, SBERT generates embeddings that can be compared almost instantly using cosine similarity.
Taking this a step further, PatentSBERTa introduces "Augmented SBERT", fine-tuned with supervised patent claims data to better capture the technical details of patents. This model, when combined with a K-Nearest Neighbors classifier, excels in subclass classification. It achieved 54% accuracy and an F1 score exceeding 66% when applied to 1,492,294 patents across 663 subclasses. The patembed family, launched in late 2025, improves results even further through multi-task training and hard negative mining. It also supports extended context lengths of up to 4,096 tokens, making it ideal for handling complex patent texts.
"PatentSBERTa, Bert-for-patents, and TF-IDF Weighted Word Embeddings have the best accuracy for computing sentence embeddings at the subclass level." – Hamid Bekamiri, Daniel S. Hain, and Roman Jurowetzki
Semi-Supervised Learning for SEPs
Semi-supervised learning combines the strengths of both supervised and unsupervised methods, offering better interpretability and performance. This is particularly useful for analyzing Standard-Essential Patents (SEPs), where labeled data is often scarce. Hybrid frameworks excel in capturing the subtle overlaps and nuances of technological features, as reflected in CPC overlap metrics.
For SEPs, this approach is invaluable - it helps uncover the intricate connections between standards and patents by analyzing both explicit claims and hidden technical relationships. SBERT models paired with K-Nearest Neighbors classifiers also offer greater transparency compared to fully supervised deep learning models, which can often feel like "black boxes." Additionally, the performance of these hybrid models can be adjusted for specific patent classes, ensuring a tailored approach that enhances accuracy.
Performance Metrics and Model Comparisons
The progress in advanced patent vectorization models is evident in their improved accuracy and speed. Metrics like Mean Average Precision (MAP) and Mean Reciprocal Rank (MRR@10) assess ranking quality and retrieval efficiency. For classification tasks, F1 scores remain a key measure, balancing precision and recall in multi-label scenarios.
The patembed-base model set a new benchmark in October 2025, achieving a V-measure of 0.494 on the MTEB BigPatentClustering.v2 benchmark, surpassing the previous best of 0.445. In terms of processing speed, ModernBERT-base-PT stood out by handling 157.2 samples per second - more than three times faster than the earlier PatentBERT, which managed 44.0 samples per second. These advancements make modern models not only more accurate but also practical for real-time analysis of extensive SEP portfolios using top patent tools.
"PatenTEB addresses a critical gap in patent text understanding by providing the first comprehensive benchmark specifically designed for patent text embeddings." – Iliass Ayaou
Transfer Learning and Vectorization in SEP Analytics
Managing SEP Portfolios More Effectively
Transfer learning has revolutionized how patent teams retrieve standard-essential patents (SEPs), making the process faster and more precise. For instance, PaECTER can predict the most similar patent with an average rank of 1.32 among 25 unrelated ones. This level of accuracy allows teams to quickly pinpoint relevant prior art, evaluate the strength of their portfolios, and uncover potential licensing opportunities - all without sifting through countless documents manually.
SEP tools also streamline coverage analysis for standards like 3GPP (5G/LTE), IEEE (WiFi-7), and codecs (H.266, AV1, IVAS). Unlike traditional keyword searches that often fail to capture semantic relationships, vector-based methods identify patents based on technical similarity - even when different terminology is used. This is especially crucial for telecommunications portfolios, where standards evolve rapidly, and technical language often shifts with each new generation.
Identifying Technology Relationships
Beyond improving retrieval, advanced vectorization techniques now reveal connections between different technologies. For example, fine-tuned models like Pat-SPECTER enable cross-corpus mapping, linking patents to scientific publications and tracing the flow of knowledge from research labs to commercial products. In SEP analytics, these tools allow analysts to map patent claims directly to specific technical limitations in standards documents, even on a limitation-by-limitation basis.
Next-generation workflows take this a step further by using section-aware extraction to map claims to technical standards. These systems maintain the structure of documents, including hierarchies, equations, and illustrations, rather than reducing everything to plain text. The result? Automated claim charting that transforms thousands of pages of technical standards into organized, searchable evidence.
Integration into AI-Powered Tools like Patently
Advances in transfer learning are now embedded into operational platforms like Patently, which uses Vector AI semantic search to help patent professionals find SEPs based on meaning rather than keywords. Its dual-index architecture combines a structured database for document hierarchies with a vector index for high-recall retrieval. This approach ensures both precision and comprehensive coverage across vast patent datasets.
Features like Interactive Agentic Analysis allow IP professionals to ask natural language questions about essentiality and receive citation-backed insights directly within claim charts. By incorporating models like PaECTER and domain-specific encoders, these tools outperform general-purpose text embedding models (e.g., E5, GTE, and BGE) in identifying semantically related patents. This reduces the need for time-consuming manual searches, letting analysts focus on strategic tasks like licensing, litigation, and portfolio development. These advancements highlight how transfer learning is reshaping the landscape of SEP analytics.
Conclusion
Transfer learning is reshaping how patent professionals tackle SEP (Standard Essential Patent) analytics. By fine-tuning models like PaECTER and ModernBERT-base-PT on specialized patent datasets, teams can now achieve precision levels far beyond traditional keyword searches. For example, the PaECTER model ranks the most similar patent at an average position of 1.32 when compared to 25 unrelated patents. This showcases how advanced vectorization techniques are driving real progress.
Moving beyond keyword-based searches, semantic understanding has become a game-changer. Analysts can now identify patents with technical similarities even when terminology differs - a critical need in fast-changing fields like telecommunications. Domain-specific pretraining equips these models to navigate the intricate legal and technical language that often trips up general-purpose AI. These advances are no longer just theoretical; they’re being integrated into practical tools.
Platforms such as Patently Know are bringing these innovations to life. With features like Vector AI semantic search and interactive agent analysis, IP professionals can now ask natural language questions and receive citation-backed insights in seconds. Modern tools also process dense, technical patent documents over three times faster than older models, thanks to updates like FlashAttention. This leap in speed and accuracy significantly reduces the time and expense of manual reviews, making SEP analytics more efficient and accessible.
As transfer learning continues to advance, the divide between generic text analysis and specialized patent intelligence will grow wider. Organizations leveraging these tailored models and AI-driven platforms will gain a clear edge in areas like portfolio management, essentiality checks, and FRAND compliance - turning what was once a tedious process into a strategic advantage.
FAQs
What’s the difference between keyword search and vector semantic search for SEPs?
Keyword searches rely on matching exact words or phrases in patent documents. While effective to some degree, this approach can overlook related patents that use different terminology. Vector semantic search changes the game by leveraging NLP models to interpret the meaning and context of text. It transforms text into mathematical vectors, enabling the system to identify conceptually similar patents - even when they don’t share the same keywords. This leads to better recall and more precise results, especially in SEP analysis.
How much labeled SEP data do I need to fine-tune a model successfully?
When it comes to fine-tuning models with Standard Essential Patent (SEP) data, there isn’t a specific amount of labeled data required for success. However, one thing is clear: quality matters more than sheer quantity.
For context, manually verifying the essentiality of a single patent can cost anywhere from $4,159 to $7,860. This highlights just how crucial high-quality, accurate data is in this process. Rather than fixating on volume, the priority should be ensuring the data is both relevant and precise to deliver effective outcomes.
How do these models handle long patent claims and standards sections beyond 512 tokens?
Graph transformer-based models are designed to process invention graphs, allowing them to handle lengthy documents more efficiently. This approach boosts computational efficiency compared to traditional text-based models, making it ideal for managing sections like patent claims and standards that go beyond 512 tokens.