How Vector AI Uses Multimodal Data for Patents
Intellectual Property Management
Apr 12, 2026
Multimodal Vector AI merges text, images, and metadata to boost patent search, classification, and real-time prior art discovery.

Vector AI transforms how patents are analyzed by combining text, images, and metadata into a single system. It addresses challenges like missed patents due to keyword limitations and the inability to process diagrams effectively. Here's how it works:
Multimodal Data: Processes text, visuals, and metadata together to retain context, such as spatial relationships in diagrams.
Vector Representations: Converts patent data into numerical vectors for precise comparisons and retrieval.
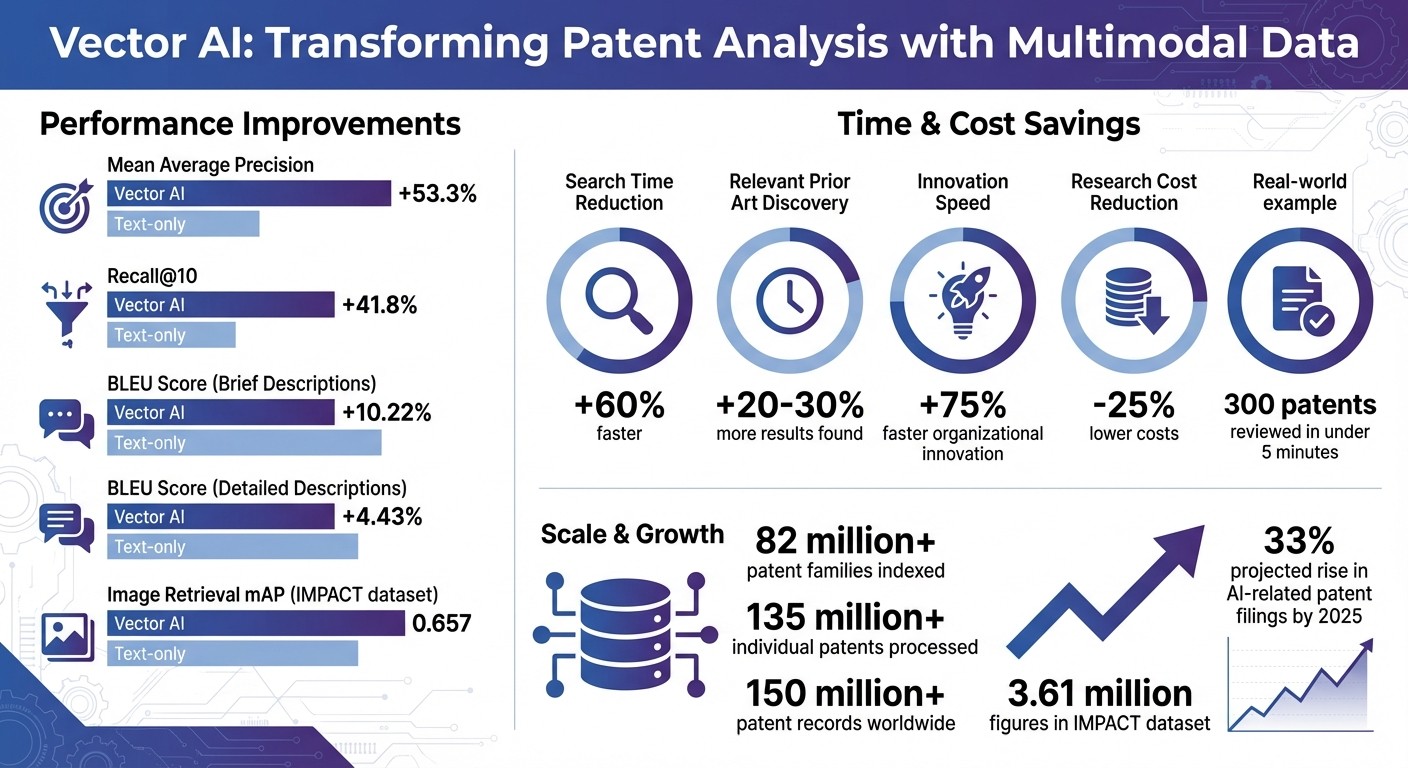
Advanced Search: Enables semantic searches, improving accuracy by 53.3% and recall by 41.8% compared to text-only methods.
Real-Time Updates: Eliminates delays caused by batch processing, providing instant access to the latest filings.
Applications: Enhances patent search, classification, clustering, and even prior art identification.
This technology is reshaping patent analysis, saving time, improving accuracy, and making complex searches faster and more efficient.
Vector AI Performance Metrics and Impact on Patent Search Efficiency
Building an End-to-End AI Agent for Patent Analysis with Java ADK, AlloyDB & Gemini
How Vector AI Processes Multimodal Data
Vector AI takes patent documents - spanning text, images, and metadata - and converts them into multi-dimensional vectors. These vectors are essentially numerical representations that capture the semantic meaning of the content. This transformation allows for precise mathematical comparisons between patent documents, forming the foundation for the specialized encoding processes outlined below.
How Vector Representations Work
Specialized encoders handle text, images, and metadata simultaneously. For patent text, natural language processing models extract the meaning from descriptions and claims. When it comes to images, vision encoders like PatentMME focus on structural elements such as nodes, arrows, and labels found in technical drawings. Unlike encoders trained on general photographs, these are fine-tuned to interpret sparse and highly technical patent illustrations, making them particularly adept at analyzing engineering diagrams and flowcharts.
To align visual and textual data, a projection layer - such as a Multi-Layer Perceptron - maps visual features into the same embedding space as text. This alignment ensures that a text query like "hydraulic pump mechanism" can retrieve relevant patent drawings, even if those exact terms aren’t explicitly mentioned in the image metadata. Once all data is represented as vectors in this shared space, algorithms like K-Nearest Neighbors (KNN) calculate distances between vectors to identify similar patents. This shared vector space allows the system to seamlessly combine textual and visual information.
Combining Text and Visual Data
Integration of text and visual data occurs through fusion strategies. Early fusion combines different types of data at the input stage, late fusion merges outputs using weighted averaging, and hybrid fusion enables interactions between modalities during processing.
More advanced models incorporate layout-aware processing, which uses 2D spatial embeddings to maintain the relationship between text annotations and specific visual elements in patent drawings. For example, a label pointing to a specific gear in a mechanical diagram only makes sense when the system understands both the text and its spatial positioning. Training methods like "Masked Language Modeling" and "Layout-Aware Masked Image Modeling" teach the model to interpret the unique visual syntax of technical drawings. The result is a system capable of understanding how text and images work together to explain an invention, rather than treating them as separate entities.
Applications of Multimodal AI in Patents
Improved Patent Search and Retrieval
Multimodal AI is revolutionizing how patents are searched. Traditional keyword-based searches often fall short due to vocabulary differences, missing patents that describe the same invention with different terms or in different languages. By using Vector AI, which converts both text and images into mathematical representations, the focus shifts to capturing meaning rather than merely matching words. This approach has shown impressive results, with a +53.3% improvement in mean Average Precision and a +41.8% boost in Recall@10 compared to text-only methods.
This technology also overcomes language barriers by identifying conceptually similar documents, regardless of the language they’re written in. For example, it can match the German term "Datenverarbeitung" with the English "data processing" based on their meanings, not direct translation. Additionally, Visual Language Models can analyze abstract drawings commonly found in patents, uncovering technical similarities that text alone cannot detect. These advancements pave the way for automated and more efficient patent classification systems.
Patent Classification and Clustering
Multimodal AI doesn’t just improve searches - it also enhances how patents are classified and organized. With over 150 million patent records worldwide, relying on automated systems is essential. Unlike simple text-based systems, multimodal AI combines visual and textual data, making it particularly effective for design patents, which often use sparse and templated language. By incorporating visual elements and metadata, these systems can assign International Patent Classification (IPC), Cooperative Patent Classification (CPC), or Locarno codes more accurately.
To achieve this, models like DesignCLIP and hybrid CNN-Vision Transformer architectures analyze both local geometric details and global shapes in patent sketches. This integration saves countless hours of manual work in portfolio analysis. With the United States Patent and Trademark Office (USPTO) projecting a 33% rise in AI-related patent filings by 2025, automated classification becomes even more critical.
Semantic Search with Patently
Patently takes semantic search to the next level by leveraging a unified vector space. Powered by Elastic's Search AI Platform, Patently maps each patent across 226 distinct fields, ensuring thorough search capabilities. The platform has also transitioned from batch processing to real-time access, allowing professionals to explore the latest filings instantly.
Here’s a real-world example: In October 2024, patent professional Laurence Brown used Patently's Vector AI to search for "in-ear headphones with noise isolating tips", filtering results by priority dates before 2000. By applying relevance-based sorting and narrowing the results to Sony applications, Brown identified the needed patents from a pool of 300 in under five minutes. Jerome Spaargaren, Founder and Director of Patently, highlighted the platform’s impact:
"This addition [Vector AI] has positioned Patently as one of the top patent tools for semantic patent search and is core to our technology stack."
Patently also offers tools like Onardo, an AI assistant that searches for prior art in real-time during the drafting process, and Patently License, which identifies Standard Essential Patents using the same vector search infrastructure. These features make it a comprehensive solution for modern patent professionals.
Technical Foundations of Multimodal AI
Deep Learning Architectures in Patent AI
Multimodal patent analysis depends on advanced deep learning models and generative AI patent drafting tools designed to handle both visual and textual data. These models are tailored for the unique challenges of patent documents, such as processing sparse technical drawings filled with labeled nodes, arrows, and figure numbers.
One standout model, PatentLMM, integrates two core components: PatentMME and PatentLLaMA. PatentMME is a vision encoder based on the LayoutLMv3 framework, capable of analyzing image patches, OCR text, and layout details simultaneously. PatentLLaMA, on the other hand, is a language model adapted from the LLaMA-2 7B model and trained specifically on Harvard USPTO patent descriptions. Using a technique called Layout-Aware Masked Image Modeling (LAMIM), the model masks structural elements like nodes and arrows to learn the visual syntax of technical drawings. This approach has led to a 10.22% improvement in BLEU scores for brief descriptions and a 4.43% boost for detailed descriptions compared to general-purpose models.
Another notable architecture is DesignCLIP, introduced by Zhu Wang and Sourav Medya in August 2025. Built on the CLIP framework, DesignCLIP uses contrastive learning and multi-view image techniques to align patent images with their captions. This model has shown superior performance in classification and retrieval tasks, particularly when combined with AI-generated captions, outperforming baseline models in these areas.
Datasets for Training and Evaluation
The success of these models hinges on high-quality datasets that pair technical drawings with descriptive text. Among the most influential resources is the IMPACT dataset (Integrated Multimodal Patent Analysis and Creation Dataset). This dataset includes 3.61 million figures extracted from 500,000 design patents granted by the USPTO between 2007 and 2022. Unlike utility patents, design patents often lack detailed textual descriptions, and IMPACT fills this gap by using vision-language models like LLaVA to generate captions that describe the shape and functionality of patent sketches. Human evaluations have validated these captions, with over 60% of experts agreeing on their accuracy. Fine-tuning a CLIP-ViT-B model on IMPACT improved its image retrieval mean Average Precision to 0.657, outperforming other top-tier patent models.
Another key dataset, PatentDesc-355K, features 355,000 figures from over 60,000 U.S. patents. It provides both brief descriptions averaging 34 tokens and detailed ones averaging 1,680 tokens - far more extensive than datasets like COCO, where captions average just 12 tokens. This highlights the need for models capable of handling long-form technical text. For more focused tasks, the PatFigVQA dataset supports visual question answering for patent figures, offering few-shot learning splits with training samples ranging from 9 to 150.
Together, these datasets - paired with metrics like Recall@K and mean Average Precision - help researchers benchmark and continually refine multimodal AI models for patent analysis. These models power enterprise-grade AI-enabled patent analysis platforms used for novelty and validity searches. The combination of specialized architectures and tailored datasets is driving advancements in this field.
Future Developments and Innovations
New Applications in Patent Analysis
Multimodal AI is making significant strides in patent analysis, advancing beyond basic search and classification. One of the most promising developments is Visual Question Answering (VQA) systems. These tools enable professionals to ask specific questions about patent figures, like "What type of projection is shown in this drawing?" or "Which components connect to the central node?" - and receive instant, precise answers. Powered by LVLM technology, these VQA systems can handle thousands of patent classes through multiple-choice queries, ensuring computational efficiency and accuracy.
Another exciting advancement is multi-view image learning, which evaluates patent sketches from multiple perspectives. The DesignCLIP framework combines contrastive learning with AI-generated captions to enhance the retrieval of abstract design patents. This is especially helpful for design patents, which often lack the detailed textual descriptions that utility patents include.
Additionally, the move from monthly batch updates to real-time data integration is revolutionizing access to new filings. Instead of waiting weeks for updates, platforms now process data as it becomes available. This ensures that searches reflect the most up-to-date prior art, improving both speed and reliability for patent professionals.
Benefits for Patent Professionals
These advancements are delivering tangible improvements for patent professionals, particularly in terms of time savings and accuracy. Tools like Onardo are integrating AI-assisted drafting with real-time prior art searches, allowing professionals to draft patent specifications while simultaneously conducting research. This eliminates the traditional, time-consuming back-and-forth between writing and searching.
With platforms like Patently managing a massive database of over 82 million patent families and 135 million individual patents, these efficiency improvements are becoming increasingly critical as datasets grow. By streamlining workflows and automating routine tasks, these innovations are reshaping the landscape of patent analysis.
Conclusion
With the integration of Vector AI and multimodal data - capable of understanding semantics and processing information in real time - patent professionals are now overcoming long-standing challenges in patent searches. By moving beyond keyword matching to semantic understanding, Vector AI tackles issues like vocabulary mismatches and the limited ability to analyze diagrams. Additionally, the transition from monthly batch updates to real-time data processing provides immediate access to the latest filings, which is crucial for tasks like freedom-to-operate or novelty searches and staying ahead in competitive intelligence.
The benefits of these advancements are undeniable. Semantic search enables professionals to uncover 20-30% more relevant prior art while reducing search times by up to 60%. In practice, complex searches that once took hours can now be completed in minutes.
Jerome Spaargaren’s endorsement highlights the revolutionary impact Vector AI has had on patent search platforms. As datasets grow larger, the ability to search efficiently is no longer just an advantage - it’s a necessity.
Perhaps the most profound outcome is the increased accessibility of patent intelligence. Traditional tools often come with high costs, but AI-powered platforms are leveling the playing field. Organizations can now innovate 75% faster while cutting research costs by 25%. This combination of affordability and advanced multimodal analysis is reshaping patent search, turning it into a core component of the innovation process. Leveraging multimodal data through Vector AI is not just enhancing patent analysis - it’s making it more accessible and integral to driving innovation.
FAQs
What is multimodal patent search?
Multimodal patent search leverages advanced AI to process and analyze multiple types of data - such as text, images, videos, and audio. This method goes beyond traditional keyword searches by integrating these formats to uncover deeper semantic meanings and connections.
By converting diverse content into high-dimensional vectors, this approach enables cross-modal similarity searches. This means patent professionals can more effectively identify prior art, monitor emerging trends, and simplify the patent examination process. It's a powerful way to make patent retrieval and analysis more comprehensive and efficient.
How does Vector AI match drawings with text queries?
Vector AI leverages multimodal machine learning models to link drawings with text-based queries. By blending visual and textual data, it enables precise cross-modal searches and interpretations, particularly for patent images and their descriptions. This approach ensures that visual and written patent information is analyzed together, leading to more accurate search outcomes.
How do real-time updates change prior art searches?
Real-time updates are transforming prior art searches with the help of AI-powered tools like visualization, semantic analysis, and autonomous search. These technologies streamline the process by quickly identifying relevant prior art, reducing the reliance on manual keyword searches. As a result, they save time and lower the risks of missing critical information.